 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Temporal Video Grounding with Deep Semantic Clustering
Jan 14, 2022
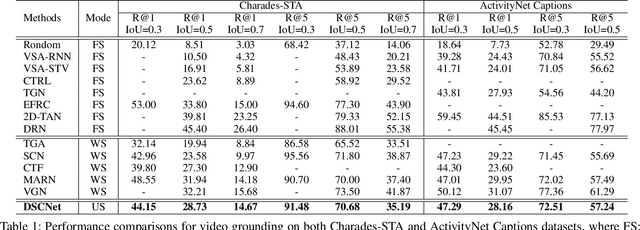
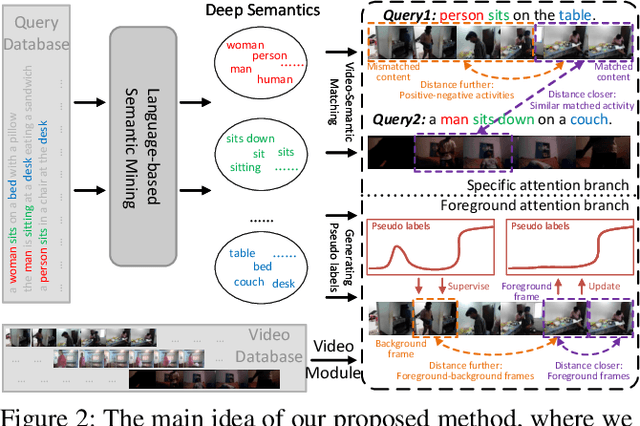

Temporal video grounding (TVG) aims to localize a target segment in a video according to a given sentence query. Though respectable works have made decent achievements in this task, they severely rely on abundant video-query paired data, which is expensive and time-consuming to collect in real-world scenarios. In this paper, we explore whether a video grounding model can be learned without any paired annotations. To the best of our knowledge, this paper is the first work trying to address TVG in an unsupervised setting. Considering there is no paired supervision, we propose a novel Deep Semantic Clustering Network (DSCNet) to leverage all semantic information from the whole query set to compose the possible activity in each video for grounding. Specifically, we first develop a language semantic mining module, which extracts implicit semantic features from the whole query set. Then, these language semantic features serve as the guidance to compose the activity in video via a video-based semantic aggregation module. Finally, we utilize a foreground attention branch to filter out the redundant background activities and refine the grounding results. To validate the effectiveness of our DSCNet, we conduct experiments on both ActivityNet Captions and Charades-STA datasets. The results demonstrate that DSCNet achieves competitive performance, and even outperforms most weakly-supervised approaches.