 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Free Lunch Theorem for Privacy-Preserving LLM Inference
Paper and Code
May 31, 2024
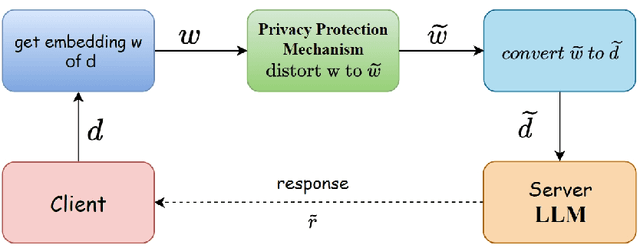
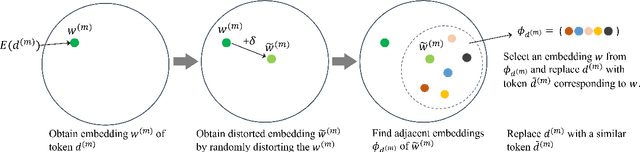
Individuals and businesses have been significantly benefited by Large Language Models (LLMs) including PaLM, Gemini and ChatGPT in various ways. For example, LLMs enhance productivity, reduce costs, and enable us to focus on more valuable tasks. Furthermore, LLMs possess the capacity to sift through extensive datasets, uncover underlying patterns, and furnish critical insights that propel the frontiers of technology and science. However, LLMs also pose privacy concerns. Users' interactions with LLMs may expose their sensitive personal or company information. A lack of robust privacy safeguards and legal frameworks could permit the unwarranted intrusion or improper handling of individual data, thereby risking infringements of privacy and the theft of personal identities. To ensure privacy, it is essential to minimize the dependency between shared prompts and private information. Various randomization approaches have been proposed to protect prompts' privacy, but they may incur utility loss compared to unprotected LLMs prompting. Therefore, it is essential to evaluate the balance between the risk of privacy leakage and loss of utility when conducting effective protection mechanisms. The current study develops a framework for inferring privacy-protected Large Language Models (LLMs) and lays down a solid theoretical basis for examining the interplay between privacy preservation and utility. The core insight is encapsulated within a theorem that is called as the NFL (abbreviation of the word No-Free-Lunch) Theorem.