 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Image-to-Image Translation HourGlass-based Architecture for Object Pushing Policy Learning
Aug 02, 2021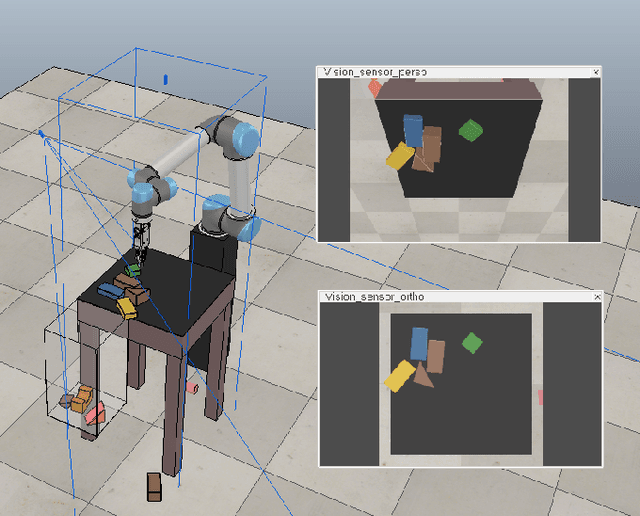
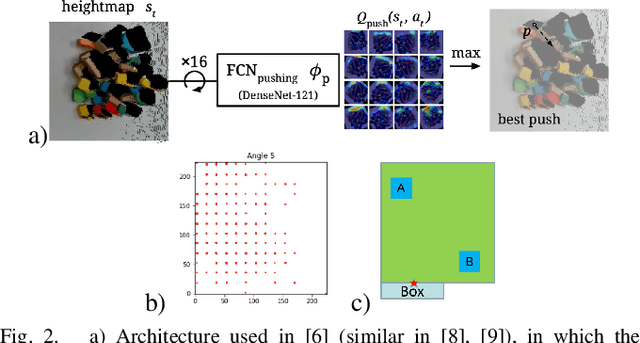
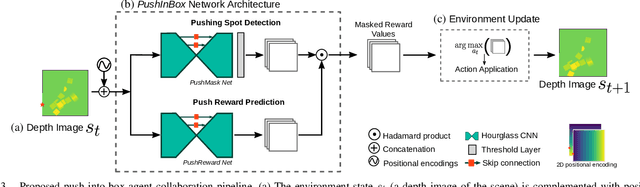
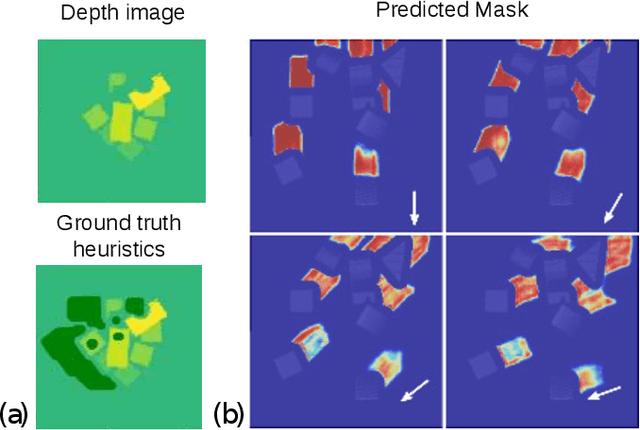
Humans effortlessly solve pushing tasks in everyday life but unlocking these capabilities remains a challenge in robotics because physics models of these tasks are often inaccurate or unattainable. State-of-the-art data-driven approaches learn to compensate for these inaccuracies or replace the approximated physics models altogether. Nevertheless, approaches like Deep Q-Networks (DQNs) suffer from local optima in large state-action spaces. Furthermore, they rely on well-chosen deep learning architectures and learning paradigms. In this paper, we propose to frame the learning of pushing policies (where to push and how) by DQNs as an image-to-image translation problem and exploit an Hourglass-based architecture. We present an architecture combining a predictor of which pushes lead to changes in the environment with a state-action value predictor dedicated to the pushing task. Moreover, we investigate positional information encoding to learn position-dependent policy behaviors. We demonstrate in simulation experiments with a UR5 robot arm that our overall architecture helps the DQN learn faster and achieve higher performance in a pushing task involving objects with unknown dynamics.
Assisted Teleoperation in Changing Environments with a Mixture of Virtual Guides
Aug 12, 2020
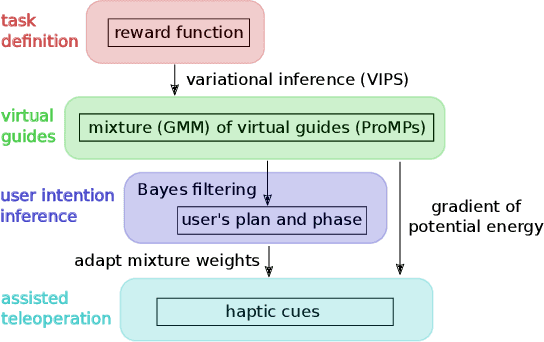
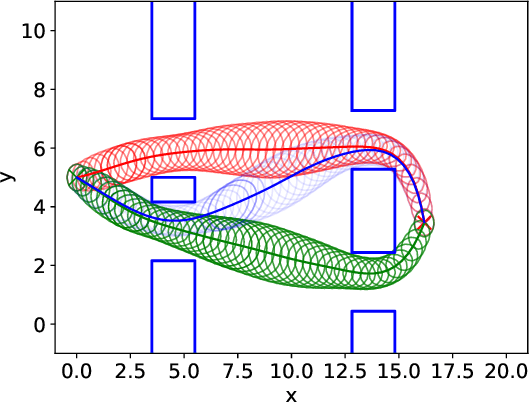
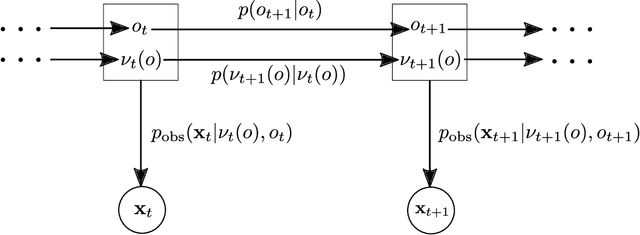
Haptic guidance is a powerful technique to combine the strengths of humans and autonomous systems for teleoperation. The autonomous system can provide haptic cues to enable the operator to perform precise movements; the operator can interfere with the plan of the autonomous system leveraging his/her superior cognitive capabilities. However, providing haptic cues such that the individual strengths are not impaired is challenging because low forces provide little guidance, whereas strong forces can hinder the operator in realizing his/her plan. Based on variational inference, we learn a Gaussian mixture model (GMM) over trajectories to accomplish a given task. The learned GMM is used to construct a potential field which determines the haptic cues. The potential field smoothly changes during teleoperation based on our updated belief over the plans and their respective phases. Furthermore, new plans are learned online when the operator does not follow any of the proposed plans, or after changes in the environment. User studies confirm that our framework helps users perform teleoperation tasks more accurately than without haptic cues and, in some cases, faster. Moreover, we demonstrate the use of our framework to help a subject teleoperate a 7 DoF manipulator in a pick-and-place task.
* 19 pages, 9 figures