 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Am I and What Will I See: An Auto-Regressive Model for Spatial Localization and View Prediction
Paper and Code

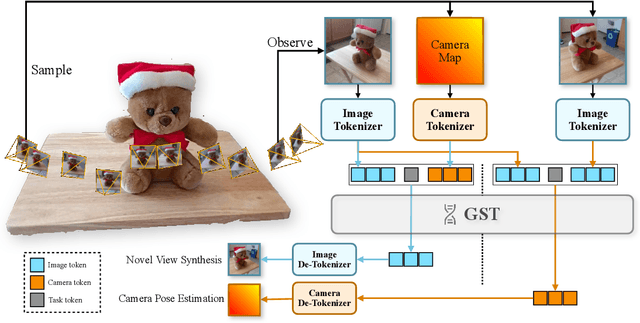
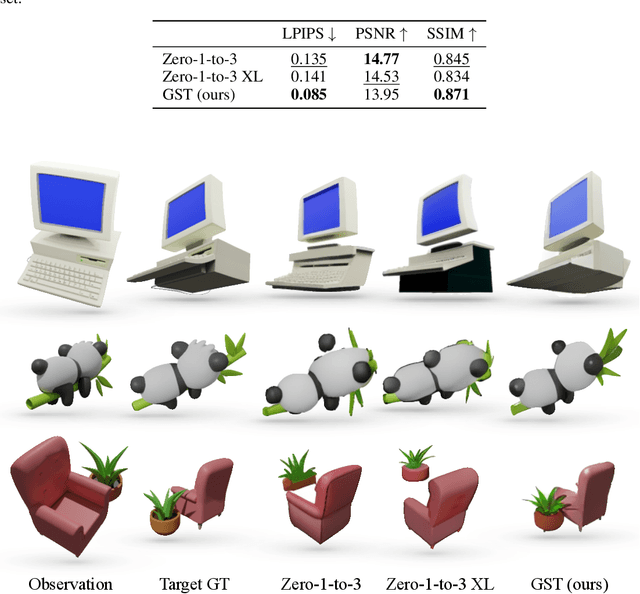
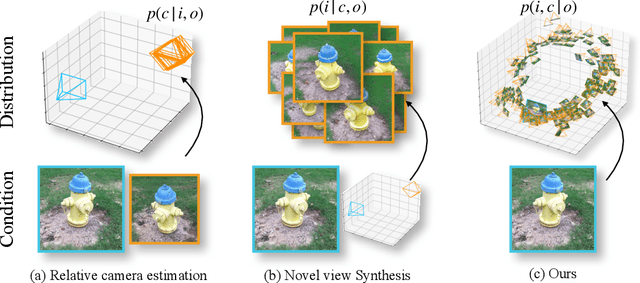
Spatial intelligence is the ability of a machine to perceive, reason, and act in three dimensions within space and time. Recent advancements in large-scale auto-regressive models have demonstrated remarkable capabilities across various reasoning tasks. However, these models often struggle with fundamental aspects of spatial reasoning, particularly in answering questions like "Where am I?" and "What will I see?". While some attempts have been done, existing approaches typically treat them as separate tasks, failing to capture their interconnected nature. In this paper, we present Generative Spatial Transformer (GST), a novel auto-regressive framework that jointly addresses spatial localization and view prediction. Our model simultaneously estimates the camera pose from a single image and predicts the view from a new camera pose, effectively bridging the gap between spatial awareness and visual prediction. The proposed innovative camera tokenization method enables the model to learn the joint distribution of 2D projections and their corresponding spatial perspectives in an auto-regressive manner. This unified training paradigm demonstrates that joint optimization of pose estimation and novel view synthesis leads to improved performance in both tasks, for the first time, highlighting the inherent relationship between spatial awareness and visual prediction.