 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdverse Event Extraction from Discharge Summaries: A New Dataset, Annotation Scheme, and Initial Findings
Jun 17, 2025In this work, we present a manually annotated corpus for Adverse Event (AE) extraction from discharge summaries of elderly patients, a population often underrepresented in clinical NLP resources. The dataset includes 14 clinically significant AEs-such as falls, delirium, and intracranial haemorrhage, along with contextual attributes like negation, diagnosis type, and in-hospital occurrence. Uniquely, the annotation schema supports both discontinuous and overlapping entities, addressing challenges rarely tackled in prior work. We evaluate multiple models using FlairNLP across three annotation granularities: fine-grained, coarse-grained, and coarse-grained with negation. While transformer-based models (e.g., BERT-cased) achieve strong performance on document-level coarse-grained extraction (F1 = 0.943), performance drops notably for fine-grained entity-level tasks (e.g., F1 = 0.675), particularly for rare events and complex attributes. These results demonstrate that despite high-level scores, significant challenges remain in detecting underrepresented AEs and capturing nuanced clinical language. Developed within a Trusted Research Environment (TRE), the dataset is available upon request via DataLoch and serves as a robust benchmark for evaluating AE extraction methods and supporting future cross-dataset generalisation.
Infusing clinical knowledge into tokenisers for language models
Jun 20, 2024



This study introduces a novel knowledge enhanced tokenisation mechanism, K-Tokeniser, for clinical text processing. Technically, at initialisation stage, K-Tokeniser populates global representations of tokens based on semantic types of domain concepts (such as drugs or diseases) from either a domain ontology like Unified Medical Language System or the training data of the task related corpus. At training or inference stage, sentence level localised context will be utilised for choosing the optimal global token representation to realise the semantic-based tokenisation. To avoid pretraining using the new tokeniser, an embedding initialisation approach is proposed to generate representations for new tokens. Using three transformer-based language models, a comprehensive set of experiments are conducted on four real-world datasets for evaluating K-Tokeniser in a wide range of clinical text analytics tasks including clinical concept and relation extraction, automated clinical coding, clinical phenotype identification, and clinical research article classification. Overall, our models demonstrate consistent improvements over their counterparts in all tasks. In particular, substantial improvements are observed in the automated clinical coding task with 13\% increase on Micro $F_1$ score. Furthermore, K-Tokeniser also shows significant capacities in facilitating quicker converge of language models. Specifically, using K-Tokeniser, the language models would only require 50\% of the training data to achieve the best performance of the baseline tokeniser using all training data in the concept extraction task and less than 20\% of the data for the automated coding task. It is worth mentioning that all these improvements require no pre-training process, making the approach generalisable.
Sexism detection: The first corpus in Algerian dialect with a code-switching in Arabic/ French and English
Apr 03, 2021
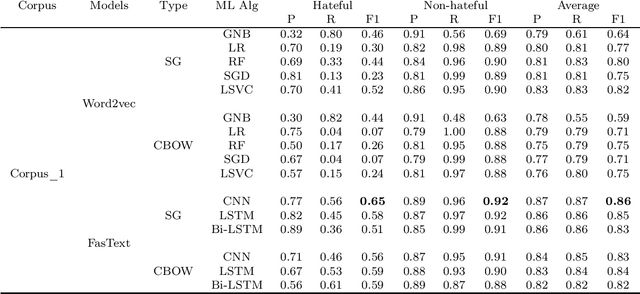
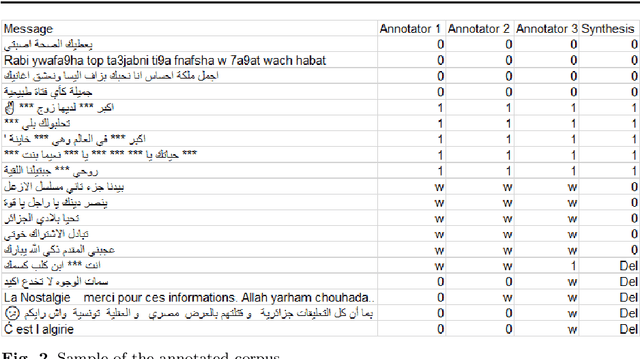
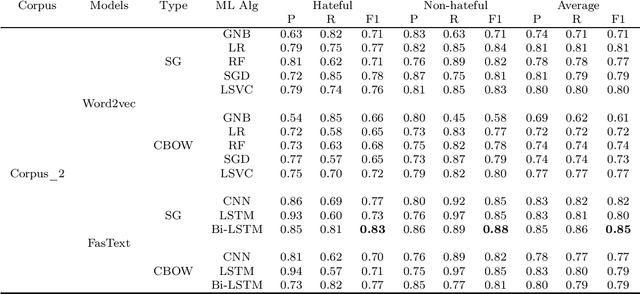
In this paper, an approach for hate speech detection against women in Arabic community on social media (e.g. Youtube) is proposed. In the literature, similar works have been presented for other languages such as English. However, to the best of our knowledge, not much work has been conducted in the Arabic language. A new hate speech corpus (Arabic\_fr\_en) is developed using three different annotators. For corpus validation, three different machine learning algorithms are used, including deep Convolutional Neural Network (CNN), long short-term memory (LSTM) network and Bi-directional LSTM (Bi-LSTM) network. Simulation results demonstrate the best performance of the CNN model, which achieved F1-score up to 86\% for the unbalanced corpus as compared to LSTM and Bi-LSTM.
Arabic natural language processing: An overview
Mar 07, 2019
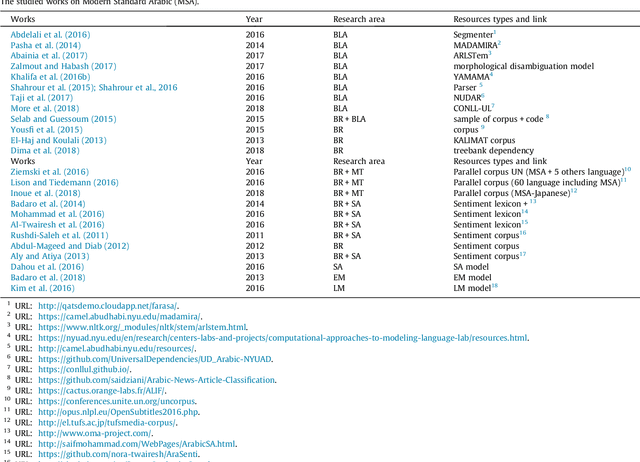
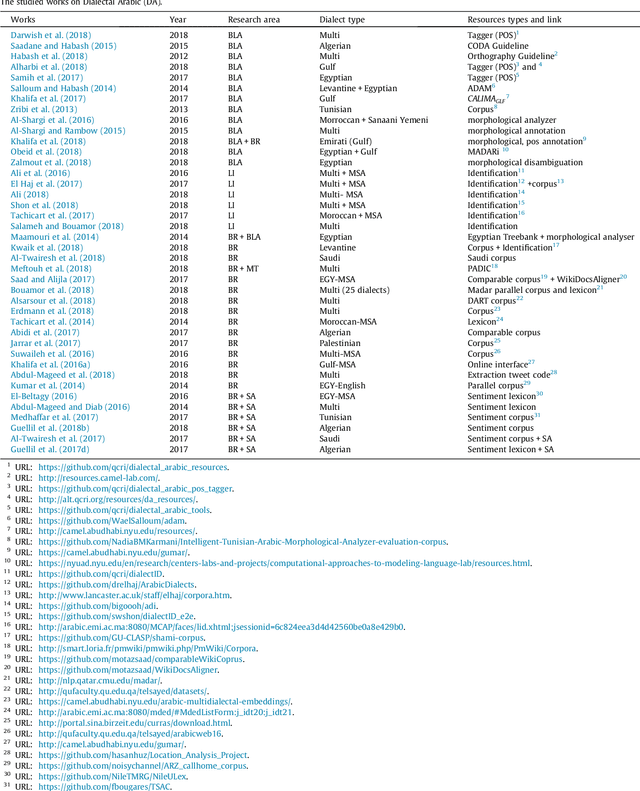
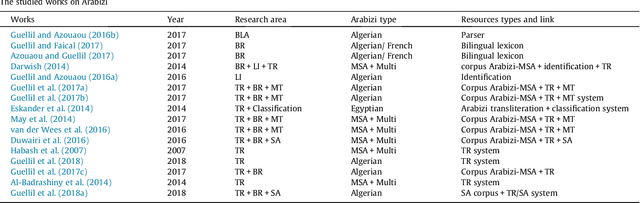
Arabic is recognised as the 4th most used language of the Internet. Arabic has three main varieties: (1) classical Arabic (CA), (2) Modern Standard Arabic (MSA), (3) Arabic Dialect (AD). MSA and AD could be written either in Arabic or in Roman script (Arabizi), which corresponds to Arabic written with Latin letters, numerals and punctuation. Due to the complexity of this language and the number of corresponding challenges for NLP, many surveys have been conducted, in order to synthesise the work done on Arabic. However these surveys principally focus on two varieties of Arabic (MSA and AD, written in Arabic letters only), they are slightly old (no such survey since 2015) and therefore do not cover recent resources and tools. To bridge the gap, we propose a survey focusing on 90 recent research papers (74% of which were published after 2015). Our study presents and classifies the work done on the three varieties of Arabic, by concentrating on both Arabic and Arabizi, and associates each work to its publicly available resources whenever available.
SentiALG: Automated Corpus Annotation for Algerian Sentiment Analysis
Aug 15, 2018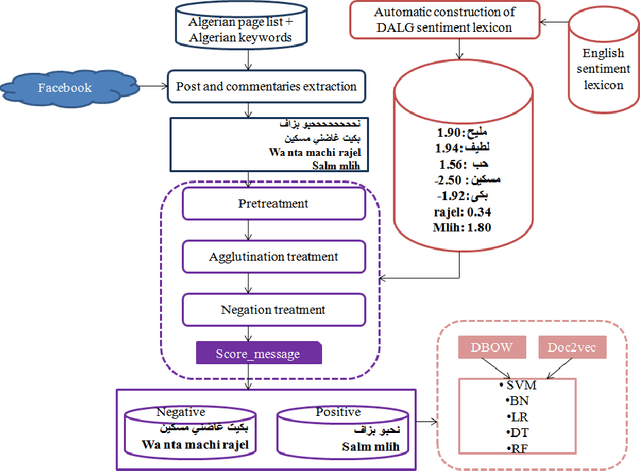
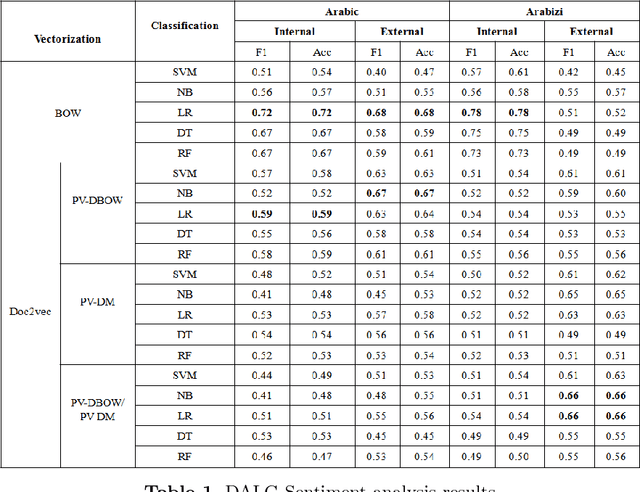
Data annotation is an important but time-consuming and costly procedure. To sort a text into two classes, the very first thing we need is a good annotation guideline, establishing what is required to qualify for each class. In the literature, the difficulties associated with an appropriate data annotation has been underestimated. In this paper, we present a novel approach to automatically construct an annotated sentiment corpus for Algerian dialect (a Maghrebi Arabic dialect). The construction of this corpus is based on an Algerian sentiment lexicon that is also constructed automatically. The presented work deals with the two widely used scripts on Arabic social media: Arabic and Arabizi. The proposed approach automatically constructs a sentiment corpus containing 8000 messages (where 4000 are dedicated to Arabic and 4000 to Arabizi). The achieved F1-score is up to 72% and 78% for an Arabic and Arabizi test sets, respectively. Ongoing work is aimed at integrating transliteration process for Arabizi messages to further improve the obtained results.
Hybrid approach for transliteration of Algerian arabizi: a primary study
Aug 10, 2018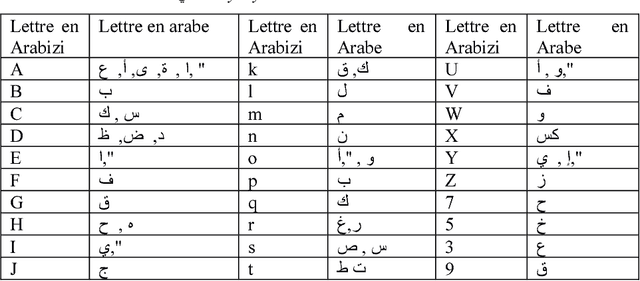
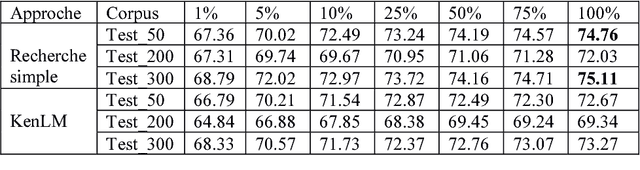
A hybrid approach for the transliteration of Algerian Arabizi: A primary study In this paper, we present a hybrid approach for the transliteration of the Algerian Arabizi. We define a set of rules enable us the passage from Arabizi to Arabic. Through these rules, we generate a set of candidates for the transliteration of each Arabizi word into arabic. Then, we extract the best candidate. This approach was evaluated by using three test corpora, and the obtained results show an improvement of the precision score which is equal to 75.11% for the best result. These results allow us to verify that our approach is very competitive comparing to others works that treat Arabizi transliteration in general. Keywords: Arabizi, Dialecte Alg\'erien, Arabizi Alg\'erien, Translit\'eration.
* in French