 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic natural language processing: An overview
Paper and Code
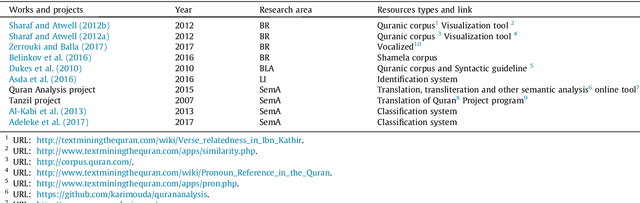
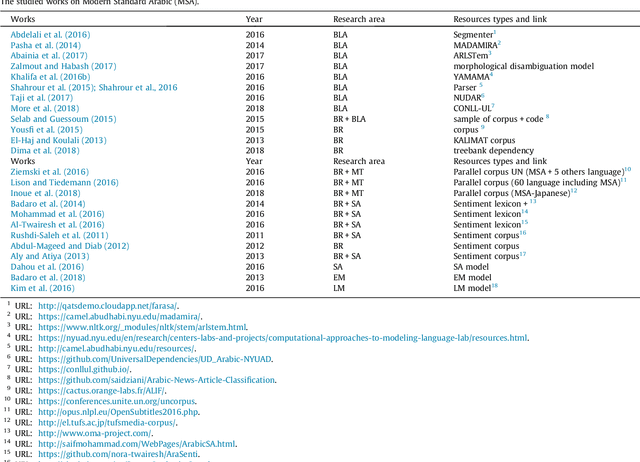
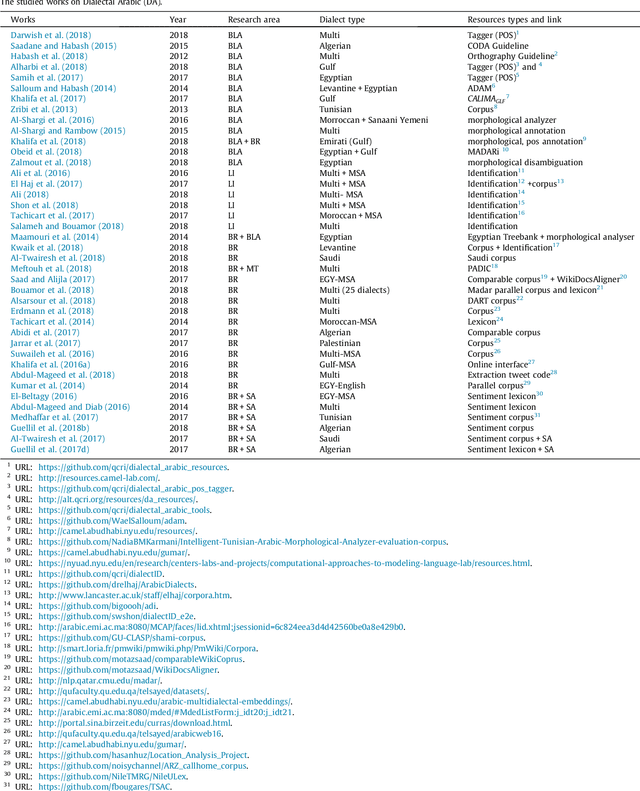
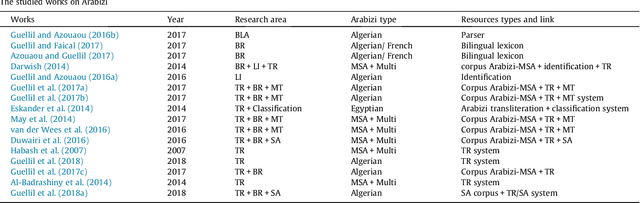
Arabic is recognised as the 4th most used language of the Internet. Arabic has three main varieties: (1) classical Arabic (CA), (2) Modern Standard Arabic (MSA), (3) Arabic Dialect (AD). MSA and AD could be written either in Arabic or in Roman script (Arabizi), which corresponds to Arabic written with Latin letters, numerals and punctuation. Due to the complexity of this language and the number of corresponding challenges for NLP, many surveys have been conducted, in order to synthesise the work done on Arabic. However these surveys principally focus on two varieties of Arabic (MSA and AD, written in Arabic letters only), they are slightly old (no such survey since 2015) and therefore do not cover recent resources and tools. To bridge the gap, we propose a survey focusing on 90 recent research papers (74% of which were published after 2015). Our study presents and classifies the work done on the three varieties of Arabic, by concentrating on both Arabic and Arabizi, and associates each work to its publicly available resources whenever available.