 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDTR-Bench: An in silico Environment and Benchmark Platform for Reinforcement Learning Based Dynamic Treatment Regime
May 28, 2024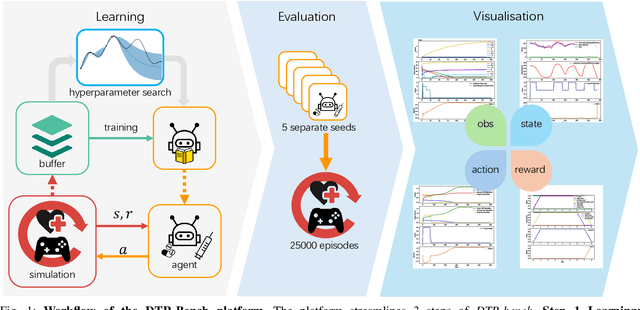
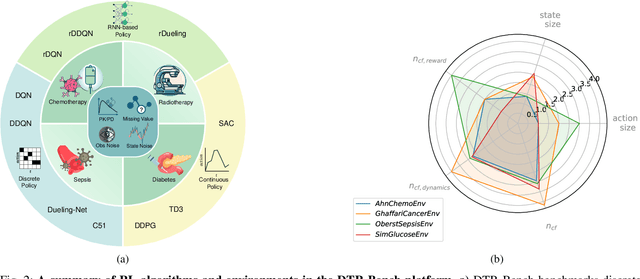


Reinforcement learning (RL) has garnered increasing recognition for its potential to optimise dynamic treatment regimes (DTRs) in personalised medicine, particularly for drug dosage prescriptions and medication recommendations. However, a significant challenge persists: the absence of a unified framework for simulating diverse healthcare scenarios and a comprehensive analysis to benchmark the effectiveness of RL algorithms within these contexts. To address this gap, we introduce \textit{DTR-Bench}, a benchmarking platform comprising four distinct simulation environments tailored to common DTR applications, including cancer chemotherapy, radiotherapy, glucose management in diabetes, and sepsis treatment. We evaluate various state-of-the-art RL algorithms across these settings, particularly highlighting their performance amidst real-world challenges such as pharmacokinetic/pharmacodynamic (PK/PD) variability, noise, and missing data. Our experiments reveal varying degrees of performance degradation among RL algorithms in the presence of noise and patient variability, with some algorithms failing to converge. Additionally, we observe that using temporal observation representations does not consistently lead to improved performance in DTR settings. Our findings underscore the necessity of developing robust, adaptive RL algorithms capable of effectively managing these complexities to enhance patient-specific healthcare. We have open-sourced our benchmark and code at https://github.com/GilesLuo/DTR-Bench.
A Brief Review of Hypernetworks in Deep Learning
Jun 12, 2023Hypernetworks, or hypernets in short, are neural networks that generate weights for another neural network, known as the target network. They have emerged as a powerful deep learning technique that allows for greater flexibility, adaptability, faster training, information sharing, and model compression etc. Hypernets have shown promising results in a variety of deep learning problems, including continual learning, causal inference, transfer learning, weight pruning, uncertainty quantification, zero-shot learning, natural language processing, and reinforcement learning etc. Despite their success across different problem settings, currently, there is no review available to inform the researchers about the developments and help in utilizing hypernets. To fill this gap, we review the progress in hypernets. We present an illustrative example to train deep neural networks using hypernets and propose to categorize hypernets on five criteria that affect the design of hypernets as inputs, outputs, variability of inputs and outputs, and architecture of hypernets. We also review applications of hypernets across different deep learning problem settings. Finally, we discuss the challenges and future directions that remain under-explored in the field of hypernets. We believe that hypernetworks have the potential to revolutionize the field of deep learning. They offer a new way to design and train neural networks, and they have the potential to improve the performance of deep learning models on a variety of tasks. Through this review, we aim to inspire further advancements in deep learning through hypernetworks.
Dynamic Inter-treatment Information Sharing for Heterogeneous Treatment Effects Estimation
May 25, 2023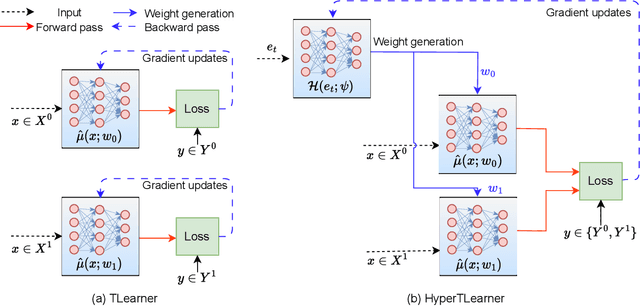
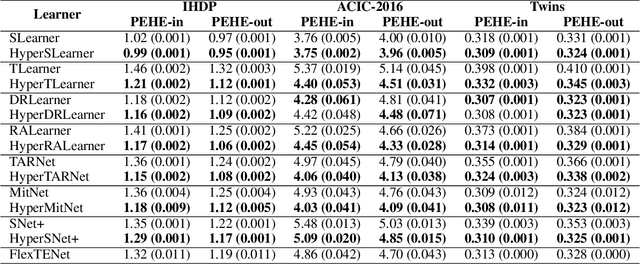
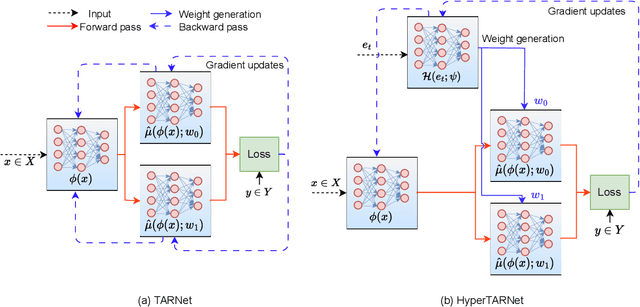
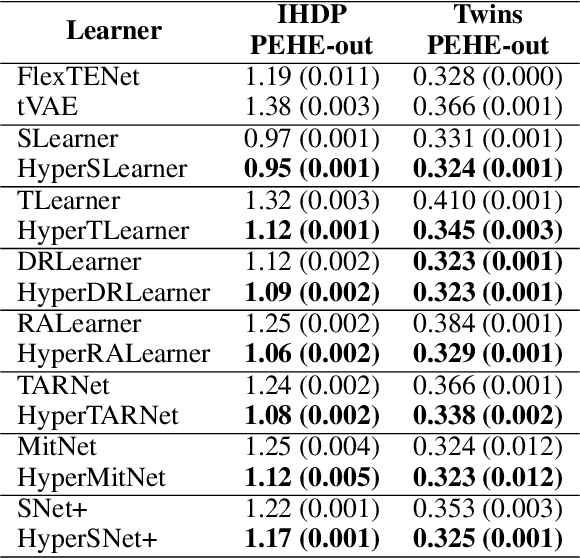
Existing heterogeneous treatment effects learners, also known as conditional average treatment effects (CATE) learners, lack a general mechanism for end-to-end inter-treatment information sharing, and data have to be split among potential outcome functions to train CATE learners which can lead to biased estimates with limited observational datasets. To address this issue, we propose a novel deep learning-based framework to train CATE learners that facilitates dynamic end-to-end information sharing among treatment groups. The framework is based on \textit{soft weight sharing} of \textit{hypernetworks}, which offers advantages such as parameter efficiency, faster training, and improved results. The proposed framework complements existing CATE learners and introduces a new class of uncertainty-aware CATE learners that we refer to as \textit{HyperCATE}. We develop HyperCATE versions of commonly used CATE learners and evaluate them on IHDP, ACIC-2016, and Twins benchmarks. Our experimental results show that the proposed framework improves the CATE estimation error via counterfactual inference, with increasing effectiveness for smaller datasets.
Motif-aware temporal GCN for fraud detection in signed cryptocurrency trust networks
Nov 22, 2022



Graph convolutional networks (GCNs) is a class of artificial neural networks for processing data that can be represented as graphs. Since financial transactions can naturally be constructed as graphs, GCNs are widely applied in the financial industry, especially for financial fraud detection. In this paper, we focus on fraud detection on cryptocurrency truct networks. In the literature, most works focus on static networks. Whereas in this study, we consider the evolving nature of cryptocurrency networks, and use local structural as well as the balance theory to guide the training process. More specifically, we compute motif matrices to capture the local topological information, then use them in the GCN aggregation process. The generated embedding at each snapshot is a weighted average of embeddings within a time window, where the weights are learnable parameters. Since the trust networks is signed on each edge, balance theory is used to guide the training process. Experimental results on bitcoin-alpha and bitcoin-otc datasets show that the proposed model outperforms those in the literature.