 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the impact of feature selection on the accuracy of heart disease prediction
Paper and Code
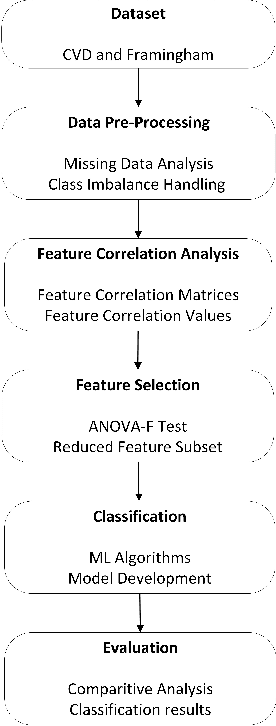
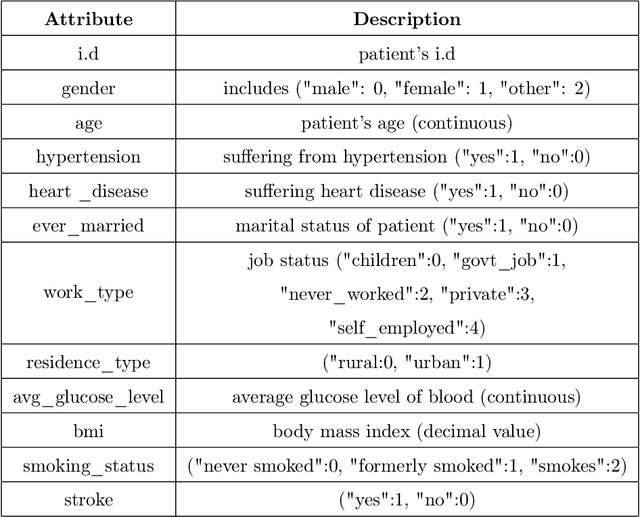
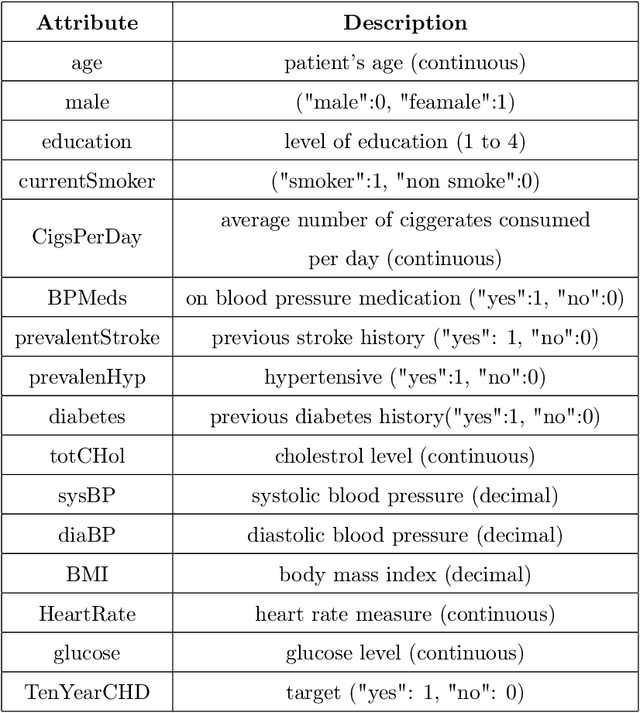
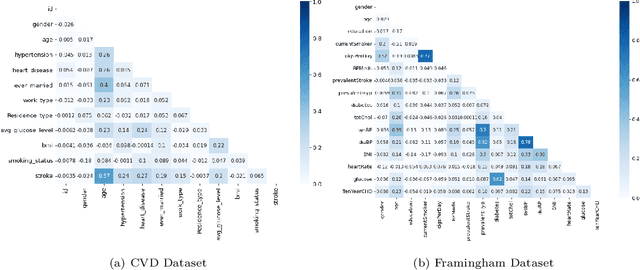
Heart Disease has become one of the most serious diseases that has a significant impact on human life. It has emerged as one of the leading causes of mortality among the people across the globe during the last decade. In order to prevent patients from further damage, an accurate diagnosis of heart disease on time is an essential factor. Recently we have seen the usage of non-invasive medical procedures, such as artificial intelligence-based techniques in the field of medical. Specially machine learning employs several algorithms and techniques that are widely used and are highly useful in accurately diagnosing the heart disease with less amount of time. However, the prediction of heart disease is not an easy task. The increasing size of medical datasets has made it a complicated task for practitioners to understand the complex feature relations and make disease predictions. Accordingly, the aim of this research is to identify the most important risk-factors from a highly dimensional dataset which helps in the accurate classification of heart disease with less complications. For a broader analysis, we have used two heart disease datasets with various medical features. The classification results of the benchmarked models proved that there is a high impact of relevant features on the classification accuracy. Even with a reduced number of features, the performance of the classification models improved significantly with a reduced training time as compared with models trained on full feature set.