 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Machine Learning Framework for UAV Trajectory Optimization in O-RAN
Jun 23, 2026The deployment of unmanned aerial vehicles (UAV) as open radio units (O-RUs) in 6G cellular systems presents a promising opportunity to achieve scalable and adaptive network coverage. However, optimizing UAV trajectories in dynamic and unfamiliar environments remains a critical challenge, particularly due to the need for extensive retraining in each new scenario. In this paper, we introduce a novel UAV trajectory optimization framework that integrates enhanced continual transfer learning within the O-RAN architecture. The proposed system maintains a library of pre-trained models and employs a model selection mechanism to identify and transfer knowledge from the most relevant environments, minimizing adaptation time and improving efficiency. When no sufficiently similar model is available, a fallback model empowered by continuous refinements ensures baseline performance. The framework leverages real-world city maps and ray tracing techniques to enhance learning reliability and improve trajectory planning. Simulation results demonstrate that the proposed model selection-based transfer learning approach reduces convergence time by 44% to 56% compared to retraining from scratch, and up to 40% compared to traditional transfer learning without model selection.
* 16 pages, 12 figures, IEEE Transactions on Vehicular Technology
Large-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
Energy Consumption Reduction for UAV Trajectory Training : A Transfer Learning Approach
Jan 20, 2025The advent of 6G technology demands flexible, scalable wireless architectures to support ultra-low latency, high connectivity, and high device density. The Open Radio Access Network (O-RAN) framework, with its open interfaces and virtualized functions, provides a promising foundation for such architectures. However, traditional fixed base stations alone are not sufficient to fully capitalize on the benefits of O-RAN due to their limited flexibility in responding to dynamic network demands. The integration of Unmanned Aerial Vehicles (UAVs) as mobile RUs within the O-RAN architecture offers a solution by leveraging the flexibility of drones to dynamically extend coverage. However, UAV operating in diverse environments requires frequent retraining, leading to significant energy waste. We proposed transfer learning based on Dueling Double Deep Q network (DDQN) with multi-step learning, which significantly reduces the training time and energy consumption required for UAVs to adapt to new environments. We designed simulation environments and conducted ray tracing experiments using Wireless InSite with real-world map data. In the two simulated environments, training energy consumption was reduced by 30.52% and 58.51%, respectively. Furthermore, tests on real-world maps of Ottawa and Rosslyn showed energy reductions of 44.85% and 36.97%, respectively.
Optimized Resource Allocation for Cloud-Native 6G Networks: Zero-Touch ML Models in Microservices-based VNF Deployments
Oct 09, 2024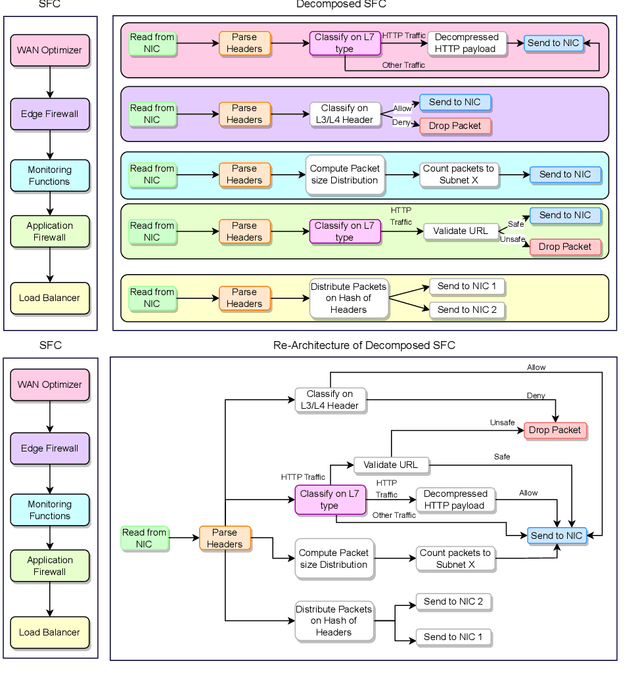
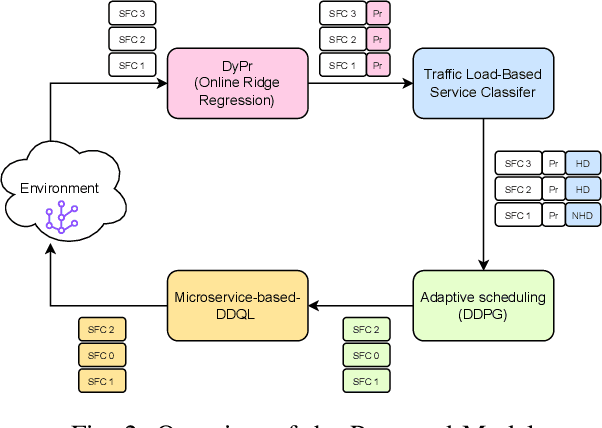
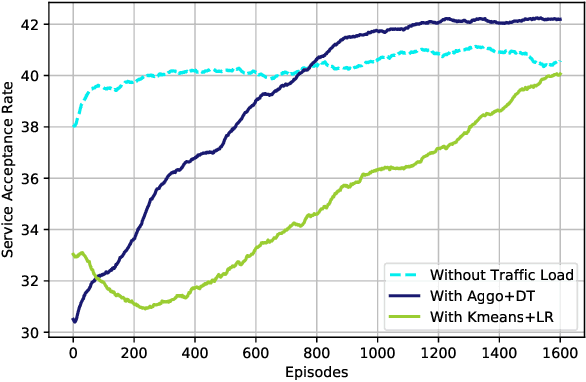
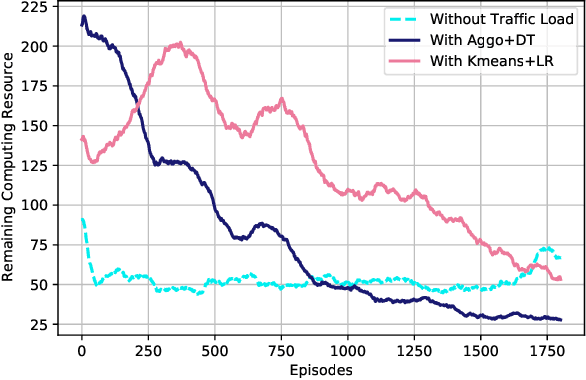
6G, the next generation of mobile networks, is set to offer even higher data rates, ultra-reliability, and lower latency than 5G. New 6G services will increase the load and dynamism of the network. Network Function Virtualization (NFV) aids with this increased load and dynamism by eliminating hardware dependency. It aims to boost the flexibility and scalability of network deployment services by separating network functions from their specific proprietary forms so that they can run as virtual network functions (VNFs) on commodity hardware. It is essential to design an NFV orchestration and management framework to support these services. However, deploying bulky monolithic VNFs on the network is difficult, especially when underlying resources are scarce, resulting in ineffective resource management. To address this, microservices-based NFV approaches are proposed. In this approach, monolithic VNFs are decomposed into micro VNFs, increasing the likelihood of their successful placement and resulting in more efficient resource management. This article discusses the proposed framework for resource allocation for microservices-based services to provide end-to-end Quality of Service (QoS) using the Double Deep Q Learning (DDQL) approach. Furthermore, to enhance this resource allocation approach, we discussed and addressed two crucial sub-problems: the need for a dynamic priority technique and the presence of the low-priority starvation problem. Using the Deep Deterministic Policy Gradient (DDPG) model, an Adaptive Scheduling model is developed that effectively mitigates the starvation problem. Additionally, the impact of incorporating traffic load considerations into deployment and scheduling is thoroughly investigated.
Continuous Transfer Learning for UAV Communication-aware Trajectory Design
May 16, 2024
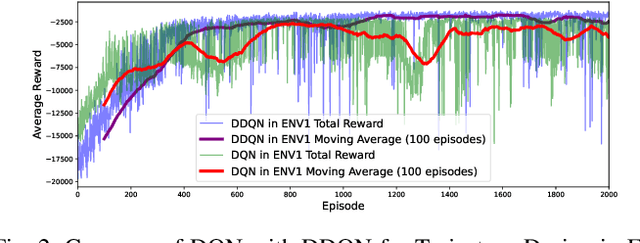
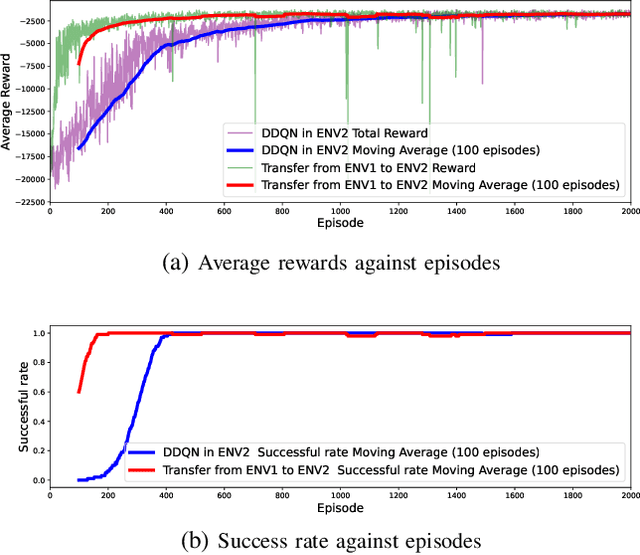
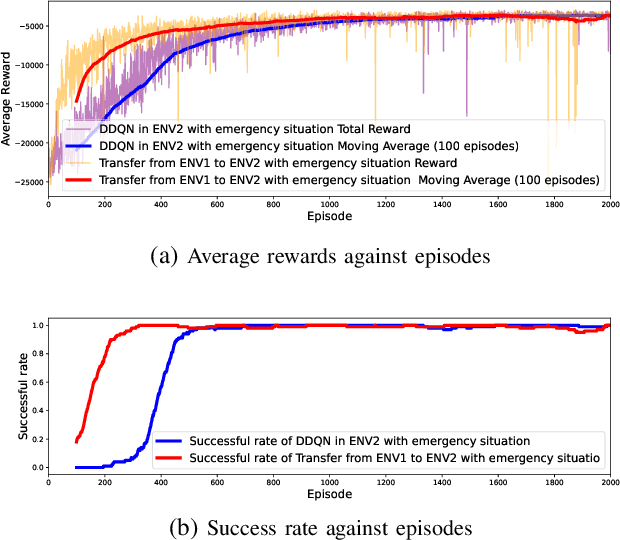
Deep Reinforcement Learning (DRL) emerges as a prime solution for Unmanned Aerial Vehicle (UAV) trajectory planning, offering proficiency in navigating high-dimensional spaces, adaptability to dynamic environments, and making sequential decisions based on real-time feedback. Despite these advantages, the use of DRL for UAV trajectory planning requires significant retraining when the UAV is confronted with a new environment, resulting in wasted resources and time. Therefore, it is essential to develop techniques that can reduce the overhead of retraining DRL models, enabling them to adapt to constantly changing environments. This paper presents a novel method to reduce the need for extensive retraining using a double deep Q network (DDQN) model as a pretrained base, which is subsequently adapted to different urban environments through Continuous Transfer Learning (CTL). Our method involves transferring the learned model weights and adapting the learning parameters, including the learning and exploration rates, to suit each new environment specific characteristics. The effectiveness of our approach is validated in three scenarios, each with different levels of similarity. CTL significantly improves learning speed and success rates compared to DDQN models initiated from scratch. For similar environments, Transfer Learning (TL) improved stability, accelerated convergence by 65%, and facilitated 35% faster adaptation in dissimilar settings.