 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Transfer Learning for UAV Communication-aware Trajectory Design
Paper and Code
May 16, 2024
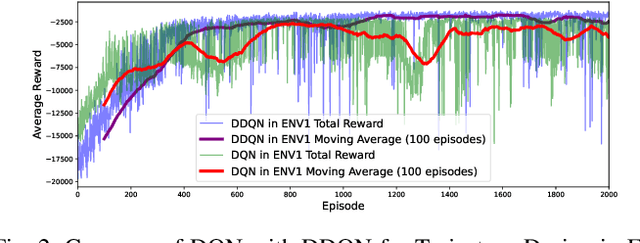
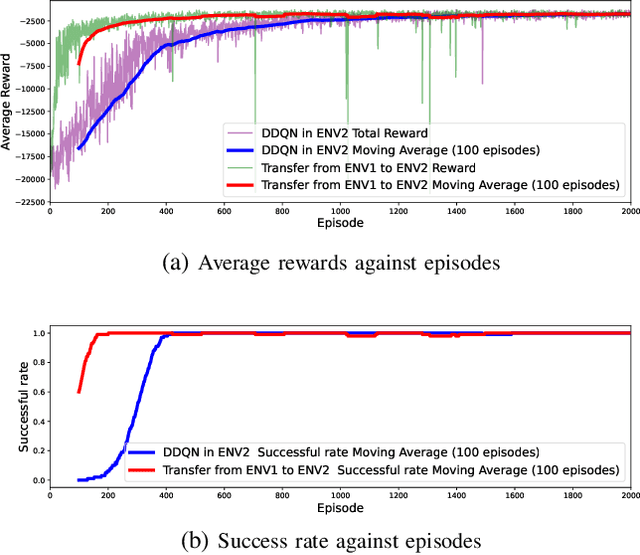
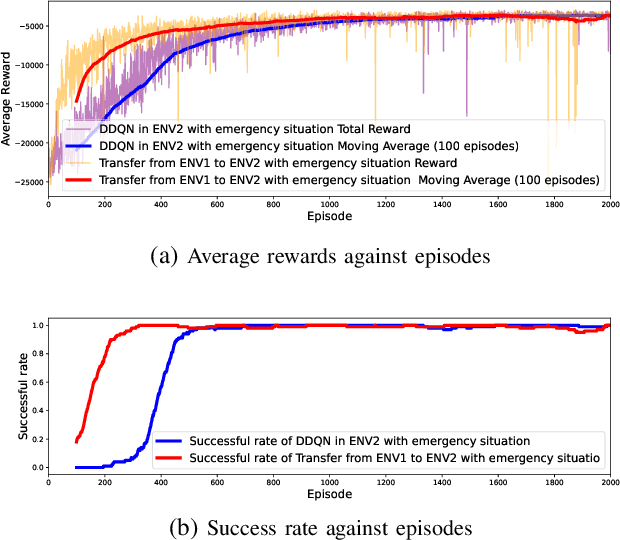
Deep Reinforcement Learning (DRL) emerges as a prime solution for Unmanned Aerial Vehicle (UAV) trajectory planning, offering proficiency in navigating high-dimensional spaces, adaptability to dynamic environments, and making sequential decisions based on real-time feedback. Despite these advantages, the use of DRL for UAV trajectory planning requires significant retraining when the UAV is confronted with a new environment, resulting in wasted resources and time. Therefore, it is essential to develop techniques that can reduce the overhead of retraining DRL models, enabling them to adapt to constantly changing environments. This paper presents a novel method to reduce the need for extensive retraining using a double deep Q network (DDQN) model as a pretrained base, which is subsequently adapted to different urban environments through Continuous Transfer Learning (CTL). Our method involves transferring the learned model weights and adapting the learning parameters, including the learning and exploration rates, to suit each new environment specific characteristics. The effectiveness of our approach is validated in three scenarios, each with different levels of similarity. CTL significantly improves learning speed and success rates compared to DDQN models initiated from scratch. For similar environments, Transfer Learning (TL) improved stability, accelerated convergence by 65%, and facilitated 35% faster adaptation in dissimilar settings.