 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evaluation of Standard Statistical Models and LLMs on Time Series Forecasting
Paper and Code
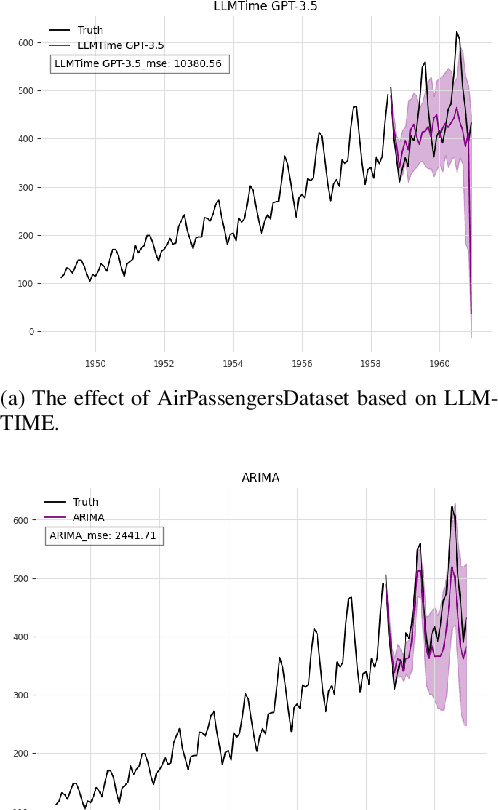
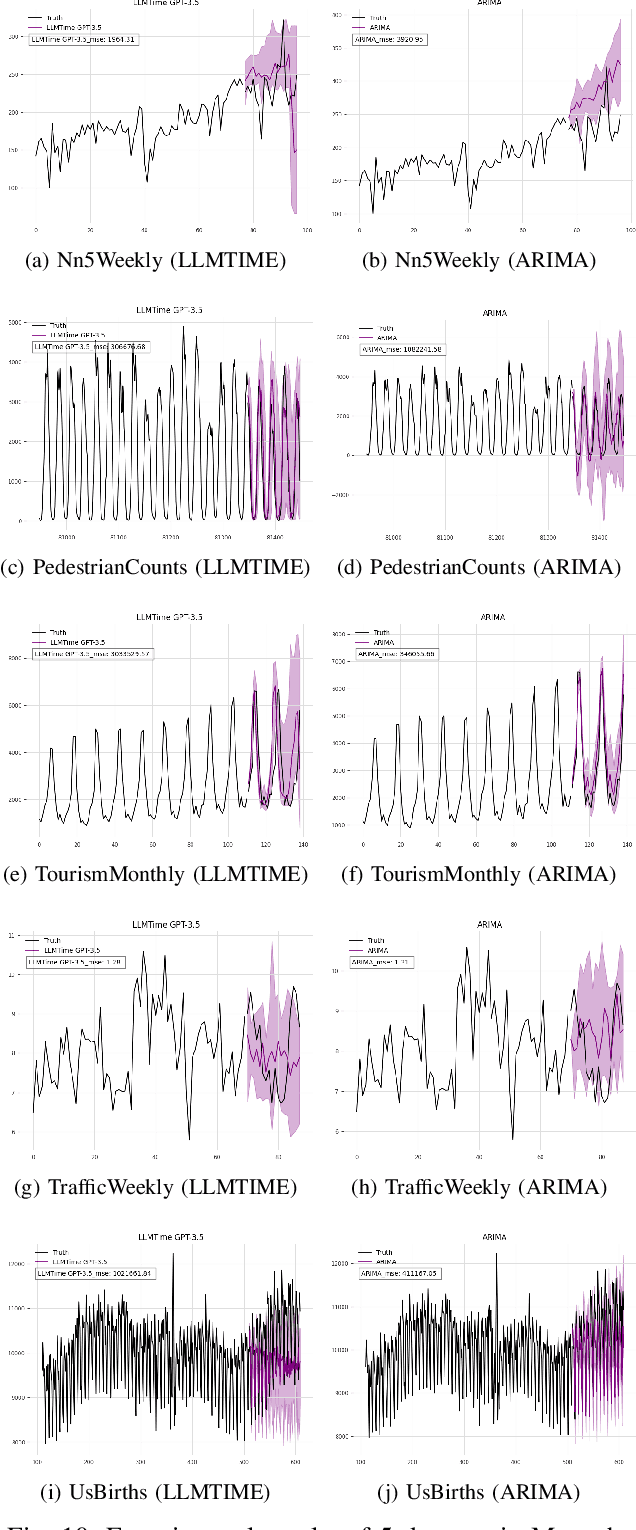
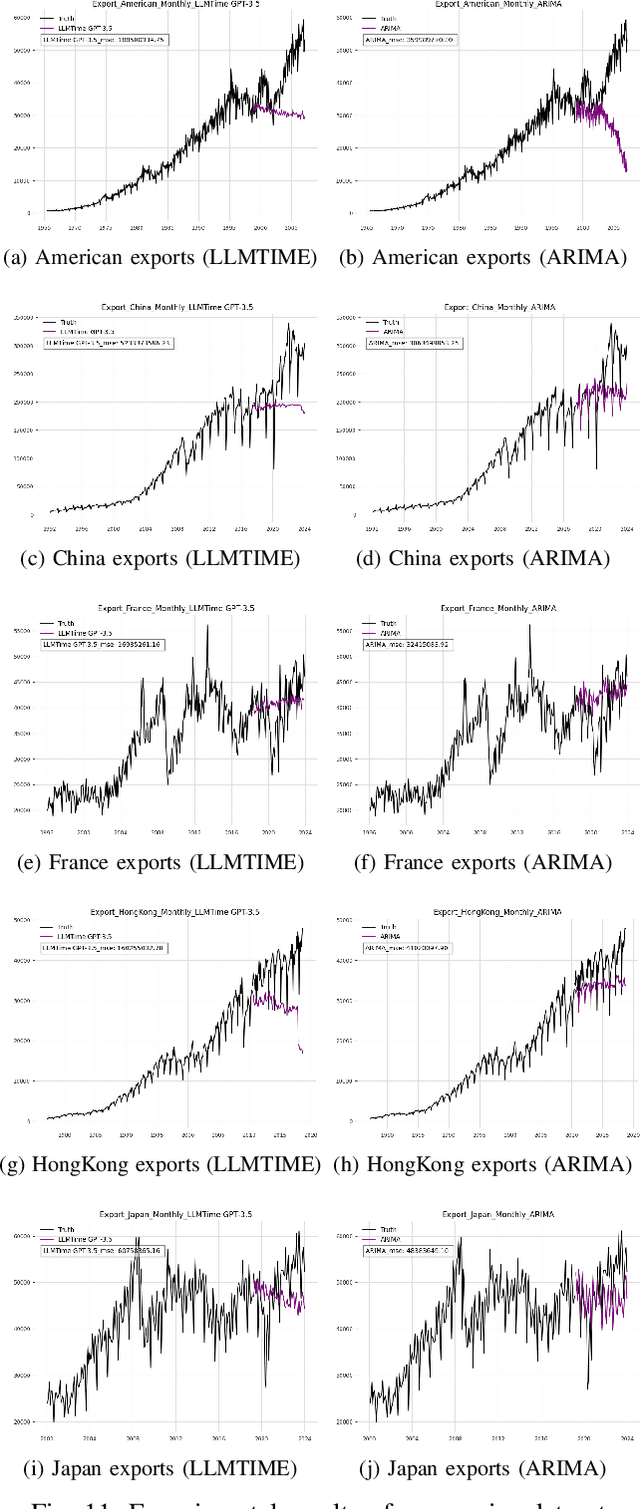
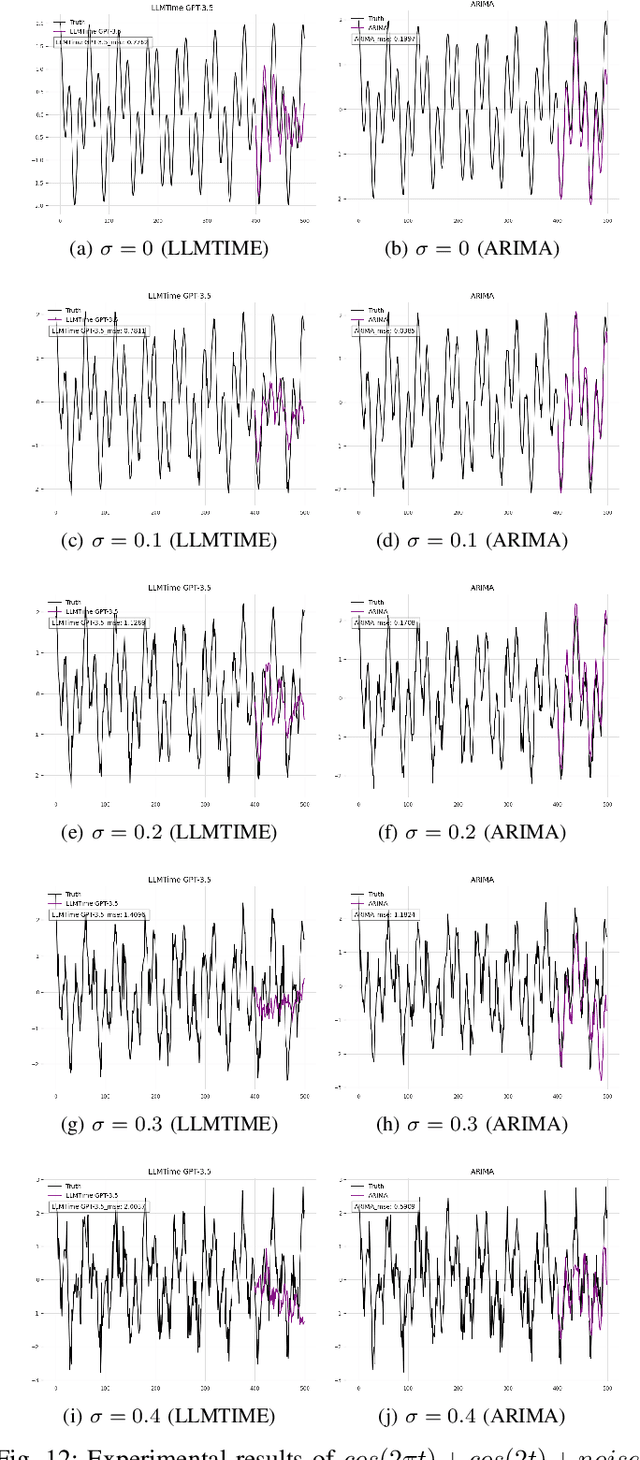
This research examines the use of Large Language Models (LLMs) in predicting time series, with a specific focus on the LLMTIME model. Despite the established effectiveness of LLMs in tasks such as text generation, language translation, and sentiment analysis, this study highlights the key challenges that large language models encounter in the context of time series prediction. We assess the performance of LLMTIME across multiple datasets and introduce classical almost periodic functions as time series to gauge its effectiveness. The empirical results indicate that while large language models can perform well in zero-shot forecasting for certain datasets, their predictive accuracy diminishes notably when confronted with diverse time series data and traditional signals. The primary finding of this study is that the predictive capacity of LLMTIME, similar to other LLMs, significantly deteriorates when dealing with time series data that contain both periodic and trend components, as well as when the signal comprises complex frequency components.