 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenED-SC: Generative Editing Semantic Communication with Integrated Multi-Modal LLMs
May 31, 2026Deep learning-based joint source-channel coding has recently demonstrated strong potential for semantic communication (SemComm). However, most existing approaches focus on optimizing visual-fidelity metrics, which can lead to reduced perceptual quality. Generative model-based SemComm leverages rich prior knowledge from large-scale pre-training to enhance perceptual quality, but often at the cost of increased distortion and unreliability. This paper addresses the above issues by proposing a two-stage semantic image transmission framework, integrating a multimodal large language model (MLLM) for generative editing. In the first stage, a JSCC-based discriminative transmission selectively prioritizes semantically important regions, preserving scene layout and object integrity under limited bandwidth. In the second phase, MLLM-driven generative editing refines missing details based on the textual descriptions, enhancing semantic fidelity and perceptual quality. Extensive experiments show that the proposed framework achieves state-of-the-art performance in semantic preservation, perceptual quality, and visual fidelity across a wide range of channel conditions, especially in low-SNR regimes.
Distortion-Aware UAV Placement for Aerial Semantic Relay Communications: An Analytical Approach
May 31, 2026Aerial semantic relay communications (SRC) employs an unmanned aerial vehicle (UAV) equipped with a semantic encoder as a relay, which not only extends the data acquisition coverage of the base station (BS) from resource-limited sensing device (SD) but also enhances communication efficiency through semantic feature transmission over the UAV-BS link. Existing works mainly focus on sum-rate maximization, overlooking the end-to-end reconstruction distortion of sensory data in UAV-assisted SRC systems. Optimizing the UAV placement is crucial for minimizing the end-to-end reconstruction distortion, as it fundamentally trades off the input perturbation at the UAV-side encoder against that at the BS-side decoder through the two-hop wireless channel conditions. In this paper, we propose an interpretable and efficient UAV placement policy by minimizing end-to-end reconstruction distortion in aerial SRC. This is a challenging task since the black-box nature of the DNN-based codecs and the intricate coupling between the heterogeneous codec sensitivities, along with two-hop channel impairments, render the end-to-end distortion analytically intractable to characterize. We first derive an analytical expression of the end-to-end distortion, explicitly revealing the impact of cross-hop perturbation coupling, wireless channel and radio resource on the reconstruction error. Based on that, we develop a closed-form UAV placement strategy with fast adaptability across various aerial SRC system configurations. Numerical results demonstrate that the proposed distortion-aware UAV deployment closely tracks the empirical exhaustive-search optimum, while achieving lower distortion compared to representative capacity-based and curve-fitting benchmarks.
Scalable Multimodal Beam Alignment in V2X: An Anti-Imbalance Graph Learning Approach
Apr 23, 2026Efficient beam alignment is fundamental to high-throughput and reliable connectivity in Vehicle-to-Everything (V2X) systems. However, conventional beam management in dynamic vehicular topologies incurs prohibitive alignment overhead and struggles to maintain robust links under rapid mobility. To overcome these challenges, this paper proposes a distributed multimodal graph beam alignment (GBA) framework. The core innovation lies in leveraging onboard multimodal sensing data to predict implicit feedback while employing graph neural networks to coordinate multi-user alignment, thereby jointly enhancing scalability and drastically reducing overhead. The architecture adopts a dual-network design with GBA-RSU and GBA-Vehicle units, optimized through a hybrid strategy of centralized learning and federated learning (FL) to balance global performance with local privacy. Furthermore, a dedicated data augmentation (DA) scheme is introduced to address multimodal data imbalance issues in vehicular networks. Negative augmentation applies dominant modality dropout to bolster robustness, while positive augmentation generates underrepresented samples to mitigate label imbalance. Numerical results demonstrate that GBA maintains a competitive sum rate on par with high-resolution codebook-based feedback yet reduces beam alignment overhead by over 90\% and scales efficiently in mobile scenarios. Notably, integrating DA enables GBA to consistently outperform state-of-the-art FL-based alignment benchmarks, with particularly pronounced gains under severe label and modality imbalance, establishing a practical solution for V2X beam management.
Joint Source-Channel-Check Coding with HARQ for Reliable Semantic Communications
Mar 25, 2026Semantic communication has emerged as a promising paradigm for improving transmission efficiency and task-level reliability, yet most existing reliability-enhancement approaches rely on retransmission strategies driven by semantic fidelity checking that require additional check codewords solely for retransmission triggering, thereby incurring substantial communication overhead. In this paper, we propose S3CHARQ, a Joint Source-Channel-Check Coding framework with hybrid automatic repeat request that fundamentally rethinks the role of check codewords in semantic communications. By integrating the check codeword into the JSCC process, S3CHARQ enables JS3C, allowing the check codeword to simultaneously support semantic fidelity verification and reconstruction enhancement. At the transmitter, a semantic fidelity-aware check encoder embeds auxiliary reconstruction information into the check codeword. At the receiver, the JSCC and check codewords are jointly decoded by a JS3C decoder, while the check codeword is additionally exploited for perceptual quality estimation. Moreover, because retransmission decisions are necessarily based on imperfect semantic quality estimation in the absence of ground-truth reconstruction, estimation errors are unavoidable and fundamentally limit the effectiveness of rule-based decision schemes. To overcome this limitation, we develop a reinforcement learning-based retransmission decision module that enables adaptive, sample-level retransmission decisions, effectively balancing recovery and refinement information under dynamic channel conditions. Experimental results demonstrate that compared with existing HARQ-based semantic communication systems, the proposed S3CHARQ framework achieves a 2.36 dB improvement in the 97th percentile PSNR, as well as a 37.45% reduction in outage probability.
Robust MIMO Semantic Communication with Imperfect CSI via Knowledge Distillation
Sep 04, 2025Semantic communication (SemComm) has emerged as a new communication paradigm. To enhance efficiency, multiple-input-multiple-output (MIMO) technology has been further integrated into SemComm systems. However, existing MIMO SemComm systems assume perfect channel matrix estimation for channel-adaptive joint source-channel coding, which is impractical due to hardware and pilot overhead constraints. In this paper, we propose a semantic image transmission system with channel matrix and channel noise adaptation, named HANA-JSCC, to cope with channel estimation errors in MIMO systems. We propose a channel matrix adaptor that collaborates with the channel codec to adapt to misaligned channel state information, thereby mitigating the impact of estimation errors. Since the relationship between the estimated channel matrix and true channel matrix is ill-posed (one-to-many), we further introduce a two-stage training strategy with knowledge distillation to overcome the convergence difficulties caused by the ill-posed problem. Comparing with the state-of-the-art benchmarks, HANA-JSCC achieves $0.40\sim0.54$dB higher average performance across various noise and estimation error levels in various datasets.
Aligning Beam with Imbalanced Multi-modality: A Generative Federated Learning Approach
Apr 21, 2025As vehicle intelligence advances, multi-modal sensing-aided communication emerges as a key enabler for reliable Vehicle-to-Everything (V2X) connectivity through precise environmental characterization. As centralized learning may suffer from data privacy, model heterogeneity and communication overhead issues, federated learning (FL) has been introduced to support V2X. However, the practical deployment of FL faces critical challenges: model performance degradation from label imbalance across vehicles and training instability induced by modality disparities in sensor-equipped agents. To overcome these limitations, we propose a generative FL approach for beam selection (GFL4BS). Our solution features two core innovations: 1) An adaptive zero-shot multi-modal generator coupled with spectral-regularized loss functions to enhance the expressiveness of synthetic data compensating for both label scarcity and missing modalities; 2) A hybrid training paradigm integrating feature fusion with decentralized optimization to ensure training resilience while minimizing communication costs. Experimental evaluations demonstrate significant improvements over baselines achieving 16.2% higher accuracy than the current state-of-the-art under severe label imbalance conditions while maintaining over 70% successful rate even when two agents lack both LiDAR and RGB camera inputs.
Scalable Multi-task Edge Sensing via Task-oriented Joint Information Gathering and Broadcast
Apr 16, 2025The recent advance of edge computing technology enables significant sensing performance improvement of Internet of Things (IoT) networks. In particular, an edge server (ES) is responsible for gathering sensing data from distributed sensing devices, and immediately executing different sensing tasks to accommodate the heterogeneous service demands of mobile users. However, as the number of users surges and the sensing tasks become increasingly compute-intensive, the huge amount of computation workloads and data transmissions may overwhelm the edge system of limited resources. Accordingly, we propose in this paper a scalable edge sensing framework for multi-task execution, in the sense that the computation workload and communication overhead of the ES do not increase with the number of downstream users or tasks. By exploiting the task-relevant correlations, the proposed scheme implements a unified encoder at the ES, which produces a common low-dimensional message from the sensing data and broadcasts it to all users to execute their individual tasks. To achieve high sensing accuracy, we extend the well-known information bottleneck theory to a multi-task scenario to jointly optimize the information gathering and broadcast processes. We also develop an efficient two-step training procedure to optimize the parameters of the neural network-based codecs deployed in the edge sensing system. Experiment results show that the proposed scheme significantly outperforms the considered representative benchmark methods in multi-task inference accuracy. Besides, the proposed scheme is scalable to the network size, which maintains almost constant computation delay with less than 1% degradation of inference performance when the user number increases by four times.
Low-Rate Semantic Communication with Codebook-based Conditional Generative Models
Apr 07, 2025
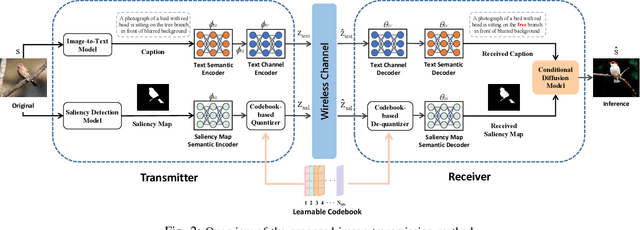
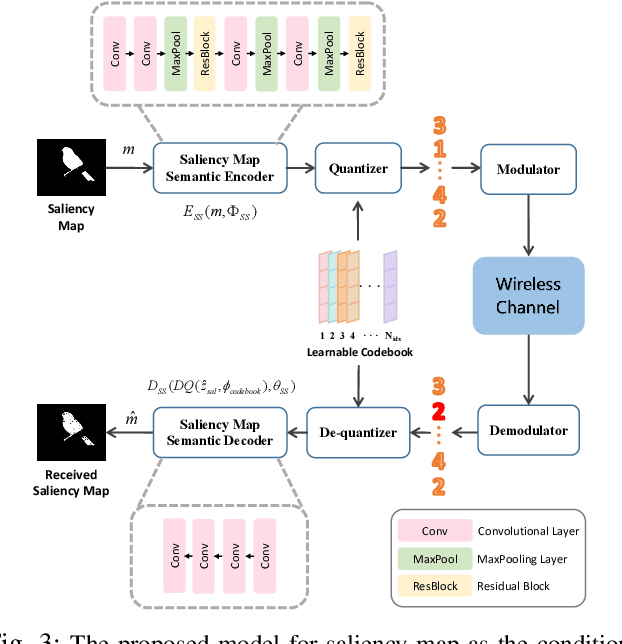
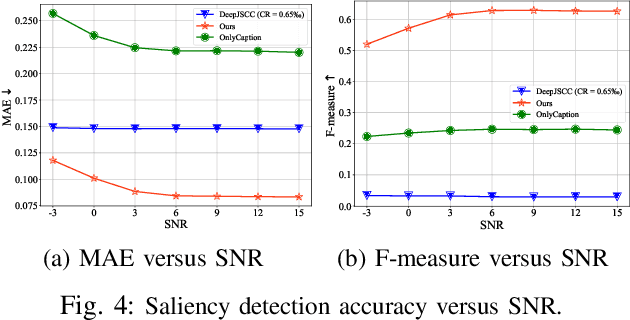
Generative semantic communication models are reshaping semantic communication frameworks by moving beyond pixel-wise optimization to align with human perception. However, many existing approaches prioritize image-level perceptual quality, often neglecting alignment with downstream tasks, which can lead to suboptimal semantic representation. This paper introduces an Ultra-Low Bitrate Semantic Communication (ULBSC) system that employs a conditional generative model and a learnable condition codebook.By integrating saliency conditions and image-level semantic information, the proposed method enables high-perceptual-quality and controllable task-oriented image transmission. Recognizing shared patterns among objects, we propose a codebook-assisted condition transmission method, integrated with joint source-channel coding (JSCC)-based text transmission to establish ULBSC. The codebook serves as a knowledge base, reducing communication costs to achieve ultra-low bitrate while enhancing robustness against noise and inaccuracies in saliency detection. Simulation results indicate that, under ultra-low bitrate conditions with an average compression ratio of 0.57Z%o, the proposed system delivers superior visual quality compared to traditional JSCC techniques and achieves higher saliency similarity between the generated and source images compared to state-of-the-art generative semantic communication methods.
Predictive Target-to-User Association in Complex Scenarios via Hybrid-Field ISAC Signaling
Jan 18, 2025



This paper presents a novel and robust target-to-user (T2U) association framework to support reliable vehicle-to-infrastructure (V2I) networks that potentially operate within the hybrid field (near-field and far-field). To address the challenges posed by complex vehicle maneuvers and user association ambiguity, an interacting multiple-model filtering scheme is developed, which combines coordinated turn and constant velocity models for predictive beamforming. Building upon this foundation, a lightweight association scheme leverages user-specific integrated sensing and communication (ISAC) signaling while employing probabilistic data association to manage clutter measurements in dense traffic. Numerical results validate that the proposed framework significantly outperforms conventional methods in terms of both tracking accuracy and association reliability.
Digital Semantic Communications: An Alternating Multi-Phase Training Strategy with Mask Attack
Aug 09, 2024Semantic communication (SemComm) has emerged as new paradigm shifts.Most existing SemComm systems transmit continuously distributed signals in analog fashion.However, the analog paradigm is not compatible with current digital communication frameworks. In this paper, we propose an alternating multi-phase training strategy (AMP) to enable the joint training of the networks in the encoder and decoder through non-differentiable digital processes. AMP contains three training phases, aiming at feature extraction (FE), robustness enhancement (RE), and training-testing alignment (TTA), respectively. AMP contains three training phases, aiming at feature extraction (FE), robustness enhancement (RE), and training-testing alignment (TTA), respectively. In particular, in the FE stage, we learn the representation ability of semantic information by end-to-end training the encoder and decoder in an analog manner. When we take digital communication into consideration, the domain shift between digital and analog demands the fine-tuning for encoder and decoder. To cope with joint training process within the non-differentiable digital processes, we propose the alternation between updating the decoder individually and jointly training the codec in RE phase. To boost robustness further, we investigate a mask-attack (MATK) in RE to simulate an evident and severe bit-flipping effect in a differentiable manner. To address the training-testing inconsistency introduced by MATK, we employ an additional TTA phase, fine-tuning the decoder without MATK. Combining with AMP and an information restoration network, we propose a digital SemComm system for image transmission, named AMP-SC. Comparing with the representative benchmark, AMP-SC achieves $0.82 \sim 1.65$dB higher average reconstruction performance among various representative datasets at different scales and a wide range of signal-to-noise ratio.