 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHVM-1: Large-scale video models pretrained with nearly 5000 hours of human-like video data
Jul 25, 2024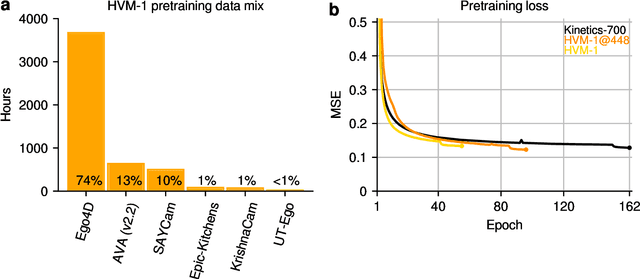
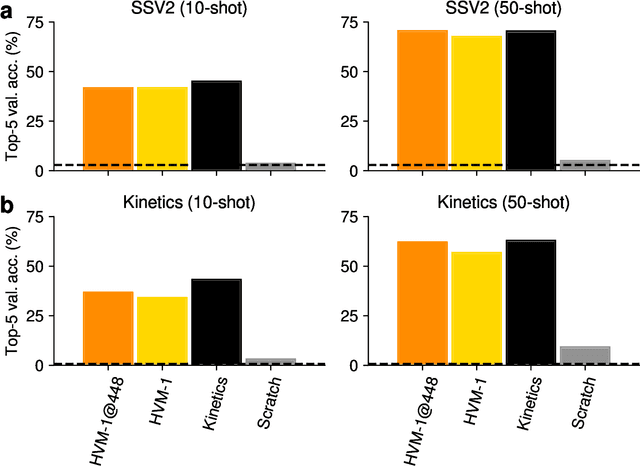
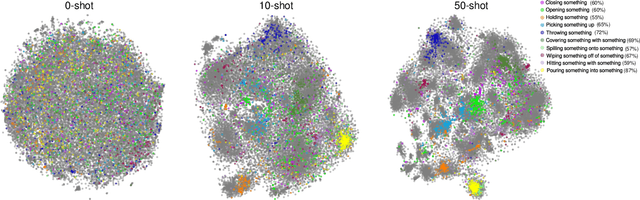
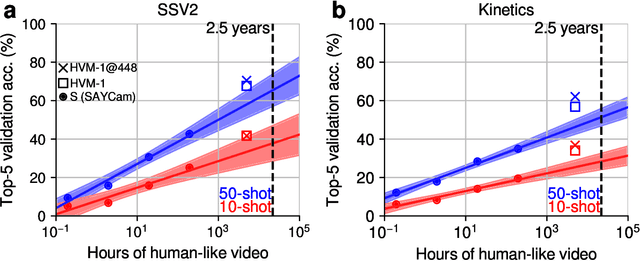
We introduce Human-like Video Models (HVM-1), large-scale video models pretrained with nearly 5000 hours of curated human-like video data (mostly egocentric, temporally extended, continuous video recordings), using the spatiotemporal masked autoencoder (ST-MAE) algorithm. We release two 633M parameter models trained at spatial resolutions of 224x224 and 448x448 pixels. We evaluate the performance of these models in downstream few-shot video and image recognition tasks and compare them against a model pretrained with 1330 hours of short action-oriented video clips from YouTube (Kinetics-700). HVM-1 models perform competitively against the Kinetics-700 pretrained model in downstream evaluations despite substantial qualitative differences between the spatiotemporal characteristics of the corresponding pretraining datasets. HVM-1 models also learn more accurate and more robust object representations compared to models pretrained with the image-based MAE algorithm on the same data, demonstrating the potential benefits of learning to predict temporal regularities in natural videos for learning better object representations.
Self-supervised learning of video representations from a child's perspective
Feb 01, 2024



Children learn powerful internal models of the world around them from a few years of egocentric visual experience. Can such internal models be learned from a child's visual experience with highly generic learning algorithms or do they require strong inductive biases? Recent advances in collecting large-scale, longitudinal, developmentally realistic video datasets and generic self-supervised learning (SSL) algorithms are allowing us to begin to tackle this nature vs. nurture question. However, existing work typically focuses on image-based SSL algorithms and visual capabilities that can be learned from static images (e.g. object recognition), thus ignoring temporal aspects of the world. To close this gap, here we train self-supervised video models on longitudinal, egocentric headcam recordings collected from a child over a two year period in their early development (6-31 months). The resulting models are highly effective at facilitating the learning of action concepts from a small number of labeled examples; they have favorable data size scaling properties; and they display emergent video interpolation capabilities. Video models also learn more robust object representations than image-based models trained with the exact same data. These results suggest that important temporal aspects of a child's internal model of the world may be learnable from their visual experience using highly generic learning algorithms and without strong inductive biases.
Scaling may be all you need for achieving human-level object recognition capacity with human-like visual experience
Aug 10, 2023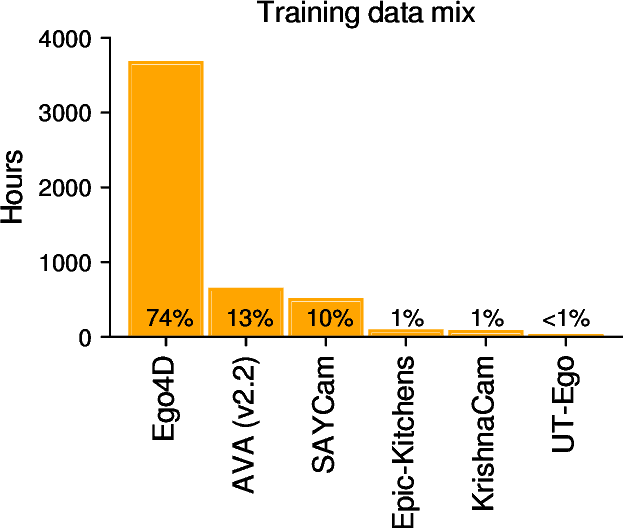

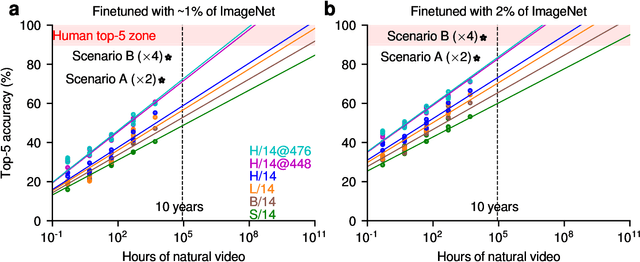
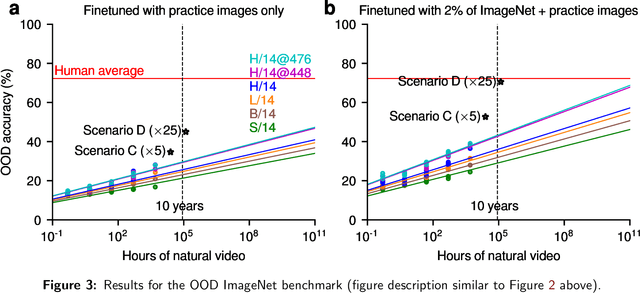
This paper asks whether current self-supervised learning methods, if sufficiently scaled up, would be able to reach human-level visual object recognition capabilities with the same type and amount of visual experience humans learn from. Previous work on this question only considered the scaling of data size. Here, we consider the simultaneous scaling of data size, model size, and image resolution. We perform a scaling experiment with vision transformers up to 633M parameters in size (ViT-H/14) trained with up to 5K hours of human-like video data (long, continuous, mostly egocentric videos) with image resolutions of up to 476x476 pixels. The efficiency of masked autoencoders (MAEs) as a self-supervised learning algorithm makes it possible to run this scaling experiment on an unassuming academic budget. We find that it is feasible to reach human-level object recognition capacity at sub-human scales of model size, data size, and image size, if these factors are scaled up simultaneously. To give a concrete example, we estimate that a 2.5B parameter ViT model trained with 20K hours (2.3 years) of human-like video data with a spatial resolution of 952x952 pixels should be able to reach roughly human-level accuracy on ImageNet. Human-level competence is thus achievable for a fundamental perceptual capability from human-like perceptual experience (human-like in both amount and type) with extremely generic learning algorithms and architectures and without any substantive inductive biases.
What can generic neural networks learn from a child's visual experience?
May 24, 2023Young children develop sophisticated internal models of the world based on their egocentric visual experience. How much of this is driven by innate constraints and how much is driven by their experience? To investigate these questions, we train state-of-the-art neural networks on a realistic proxy of a child's visual experience without any explicit supervision or domain-specific inductive biases. Specifically, we train both embedding models and generative models on 200 hours of headcam video from a single child collected over two years. We train a total of 72 different models, exploring a range of model architectures and self-supervised learning algorithms, and comprehensively evaluate their performance in downstream tasks. The best embedding models perform at 70% of a highly performant ImageNet-trained model on average. They also learn broad semantic categories without any labeled examples and learn to localize semantic categories in an image without any location supervision. However, these models are less object-centric and more background-sensitive than comparable ImageNet-trained models. Generative models trained with the same data successfully extrapolate simple properties of partially masked objects, such as their texture, color, orientation, and rough outline, but struggle with finer object details. We replicate our experiments with two other children and find very similar results. Broadly useful high-level visual representations are thus robustly learnable from a representative sample of a child's visual experience without strong inductive biases.
Recognition, recall, and retention of few-shot memories in large language models
Mar 30, 2023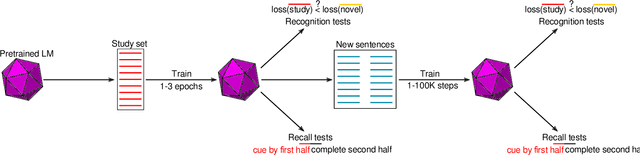
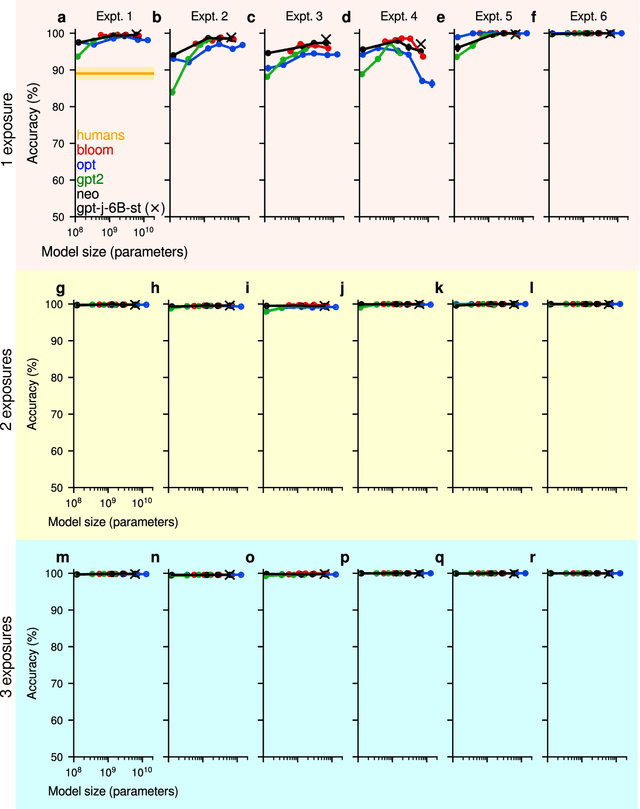
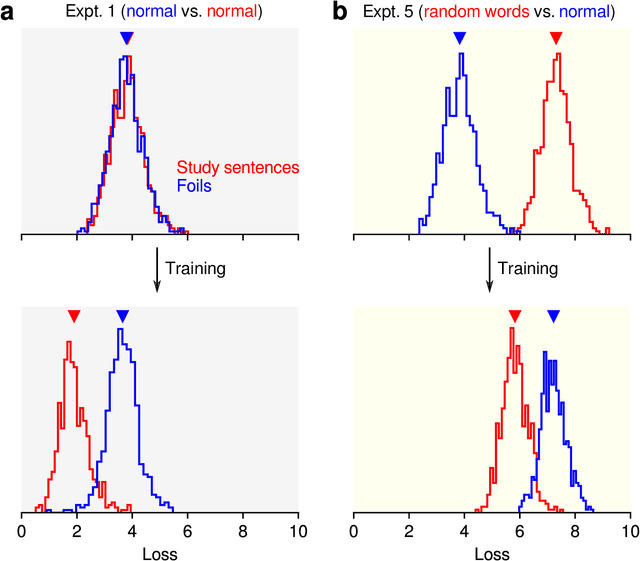
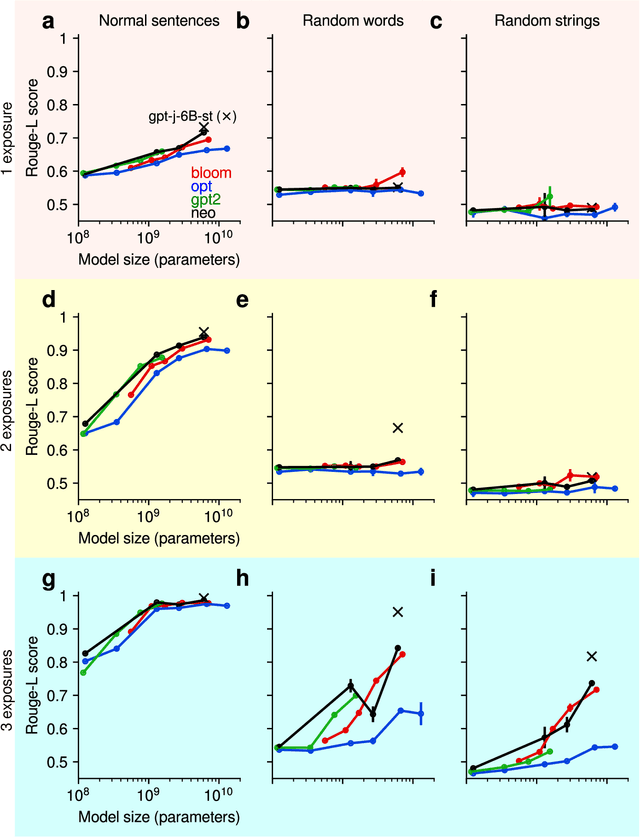
The training of modern large language models (LLMs) takes place in a regime where most training examples are seen only a few times by the model during the course of training. What does a model remember about such examples seen only a few times during training and how long does that memory persist in the face of continuous training with new examples? Here, we investigate these questions through simple recognition, recall, and retention experiments with LLMs. In recognition experiments, we ask if the model can distinguish the seen example from a novel example; in recall experiments, we ask if the model can correctly recall the seen example when cued by a part of it; and in retention experiments, we periodically probe the model's memory for the original examples as the model is trained continuously with new examples. We find that a single exposure is generally sufficient for a model to achieve near perfect accuracy even in very challenging recognition experiments. We estimate that the recognition performance of even small language models easily exceeds human recognition performance reported in similar experiments with humans (Shepard, 1967). Achieving near perfect recall takes more exposures, but most models can do it in just 3 exposures. The flip side of this remarkable capacity for fast learning is that precise memories are quickly overwritten: recall performance for the original examples drops steeply over the first 10 training updates with new examples, followed by a more gradual decline. Even after 100K updates, however, some of the original examples are still recalled near perfectly. A qualitatively similar retention pattern has been observed in human long-term memory retention studies before (Bahrick, 1984). Finally, recognition is much more robust to interference than recall and memory for natural language sentences is generally superior to memory for stimuli without structure.
Can deep learning match the efficiency of human visual long-term memory in storing object details?
Apr 28, 2022
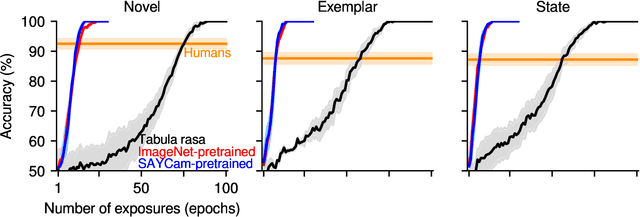


Humans have a remarkably large capacity to store detailed visual information in long-term memory even after a single exposure, as demonstrated by classic experiments in psychology. For example, Standing (1973) showed that humans could recognize with high accuracy thousands of pictures that they had seen only once a few days prior to a recognition test. In deep learning, the primary mode of incorporating new information into a model is through gradient descent in the model's parameter space. This paper asks whether deep learning via gradient descent can match the efficiency of human visual long-term memory to incorporate new information in a rigorous, head-to-head, quantitative comparison. We answer this in the negative: even in the best case, models learning via gradient descent appear to require approximately 10 exposures to the same visual materials in order to reach a recognition memory performance humans achieve after only a single exposure. Prior knowledge induced via pretraining and bigger model sizes improve performance, but these improvements are not very visible after a single exposure (it takes a few exposures for the improvements to become apparent), suggesting that simply scaling up the pretraining data size or model size might not be enough for the model to reach human-level memory efficiency.
Compositional generalization in semantic parsing with pretrained transformers
Oct 05, 2021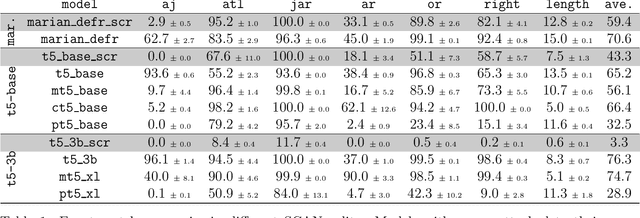
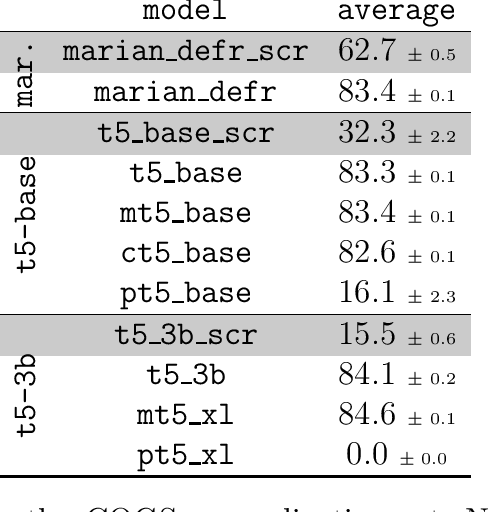
Large-scale pretraining instills large amounts of knowledge in deep neural networks. This, in turn, improves the generalization behavior of these models in downstream tasks. What exactly are the limits to the generalization benefits of large-scale pretraining? Here, we report observations from some simple experiments aimed at addressing this question in the context of two semantic parsing tasks involving natural language, SCAN and COGS. We show that language models pretrained exclusively with non-English corpora, or even with programming language corpora, significantly improve out-of-distribution generalization in these benchmarks, compared with models trained from scratch, even though both benchmarks are English-based. This demonstrates the surprisingly broad transferability of pretrained representations and knowledge. Pretraining with a large-scale protein sequence prediction task, on the other hand, mostly deteriorates the generalization performance in SCAN and COGS, suggesting that pretrained representations do not transfer universally and that there are constraints on the similarity between the pretraining and downstream domains for successful transfer. Finally, we show that larger models are harder to train from scratch and their generalization accuracy is lower when trained up to convergence on the relatively small SCAN and COGS datasets, but the benefits of large-scale pretraining become much clearer with larger models.
How much "human-like" visual experience do current self-supervised learning algorithms need to achieve human-level object recognition?
Sep 27, 2021

This paper addresses a fundamental question: how good are our current self-supervised visual representation learning algorithms relative to humans? More concretely, how much "human-like", natural visual experience would these algorithms need in order to reach human-level performance in a complex, realistic visual object recognition task such as ImageNet? Using a scaling experiment, here we estimate that the answer is on the order of a million years of natural visual experience, in other words several orders of magnitude longer than a human lifetime. However, this estimate is quite sensitive to some underlying assumptions, underscoring the need to run carefully controlled human experiments. We discuss the main caveats surrounding our estimate and the implications of this rather surprising result.
Self-supervised learning through the eyes of a child
Jul 31, 2020



Within months of birth, children have meaningful expectations about the world around them. How much of this early knowledge can be explained through generic learning mechanisms applied to sensory data, and how much of it requires more substantive innate inductive biases? Addressing this fundamental question in its full generality is currently infeasible, but we can hope to make real progress in more narrowly defined domains, such as the development of high-level visual categories, thanks to improvements in data collecting technology and recent progress in deep learning. In this paper, our goal is to achieve such progress by utilizing modern self-supervised deep learning methods and a recent longitudinal, egocentric video dataset recorded from the perspective of several young children (Sullivan et al., 2020). Our results demonstrate the emergence of powerful, high-level visual representations from developmentally realistic natural videos using generic self-supervised learning objectives.
Robustness properties of Facebook's ResNeXt WSL models
Aug 02, 2019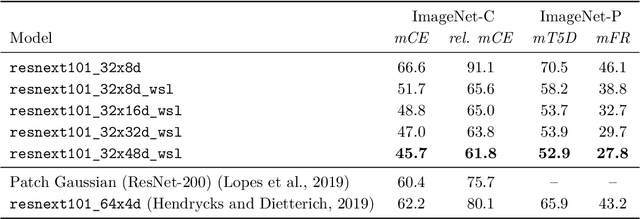
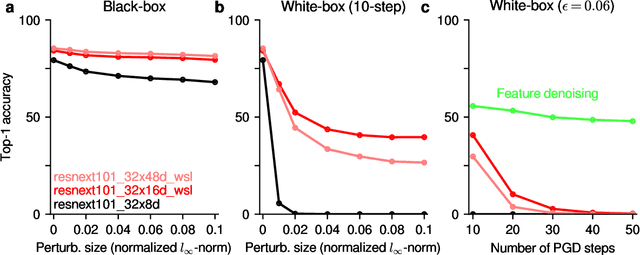
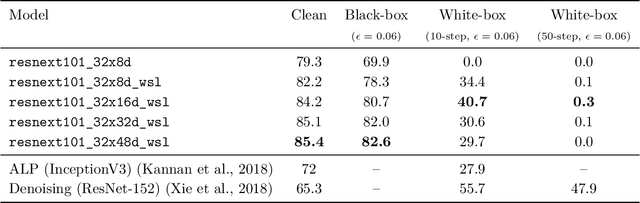

We investigate the robustness properties of ResNeXt image recognition models trained with billion scale weakly-supervised data (ResNeXt WSL models). These models, recently made public by Facebook AI, were trained on ~1B images from Instagram and fine-tuned on ImageNet. We show that these models display an unprecedented degree of robustness against common image corruptions and perturbations, as measured by the ImageNet-C and ImageNet-P benchmarks. The largest of the released models, in particular, achieves state-of-the-art results on both ImageNet-C and ImageNet-P by a large margin. The gains on ImageNet-C and ImageNet-P far outpace the gains on ImageNet validation accuracy, suggesting the former as more useful benchmarks to measure further progress in image recognition. Remarkably, the ResNeXt WSL models even achieve a limited degree of adversarial robustness against state-of-the-art white-box attacks (10-step PGD attacks). However, in contrast to adversarially trained models, the robustness of the ResNeXt WSL models rapidly declines with the number of PGD steps, suggesting that these models do not achieve genuine adversarial robustness. Visualization of the learned features also confirms this conclusion. Finally, we show that although the ResNeXt WSL models are more shape-biased than comparable ImageNet-trained models in a shape-texture cue conflict experiment, they still remain much more texture-biased than humans and their accuracy on the recently introduced "natural adversarial examples" (ImageNet-A) also remains low, suggesting that they share many of the underlying characteristics of ImageNet-trained models that make these benchmarks challenging.