 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling may be all you need for achieving human-level object recognition capacity with human-like visual experience
Paper and Code
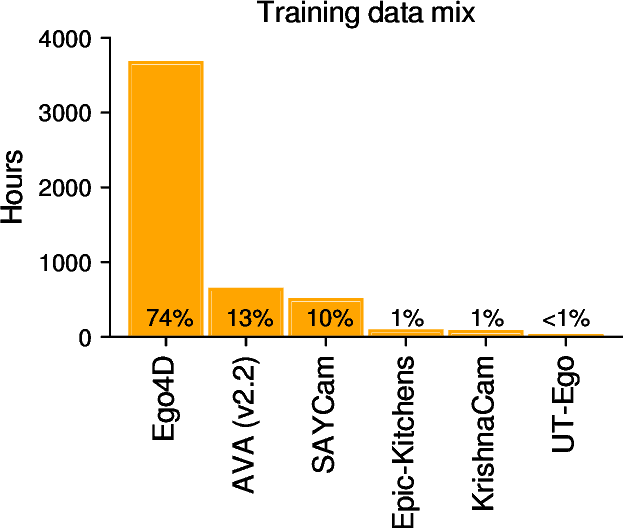

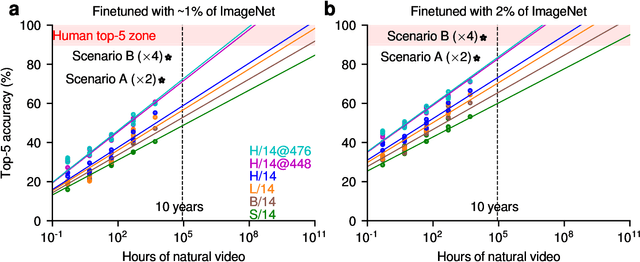
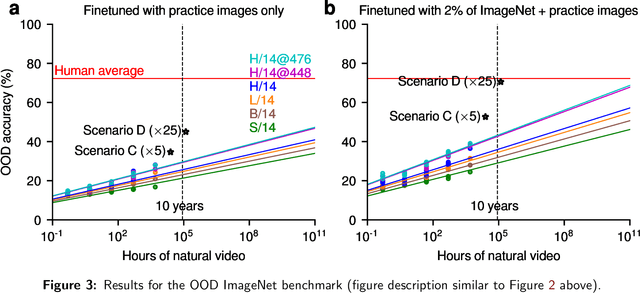
This paper asks whether current self-supervised learning methods, if sufficiently scaled up, would be able to reach human-level visual object recognition capabilities with the same type and amount of visual experience humans learn from. Previous work on this question only considered the scaling of data size. Here, we consider the simultaneous scaling of data size, model size, and image resolution. We perform a scaling experiment with vision transformers up to 633M parameters in size (ViT-H/14) trained with up to 5K hours of human-like video data (long, continuous, mostly egocentric videos) with image resolutions of up to 476x476 pixels. The efficiency of masked autoencoders (MAEs) as a self-supervised learning algorithm makes it possible to run this scaling experiment on an unassuming academic budget. We find that it is feasible to reach human-level object recognition capacity at sub-human scales of model size, data size, and image size, if these factors are scaled up simultaneously. To give a concrete example, we estimate that a 2.5B parameter ViT model trained with 20K hours (2.3 years) of human-like video data with a spatial resolution of 952x952 pixels should be able to reach roughly human-level accuracy on ImageNet. Human-level competence is thus achievable for a fundamental perceptual capability from human-like perceptual experience (human-like in both amount and type) with extremely generic learning algorithms and architectures and without any substantive inductive biases.