 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHVM-1: Large-scale video models pretrained with nearly 5000 hours of human-like video data
Paper and Code
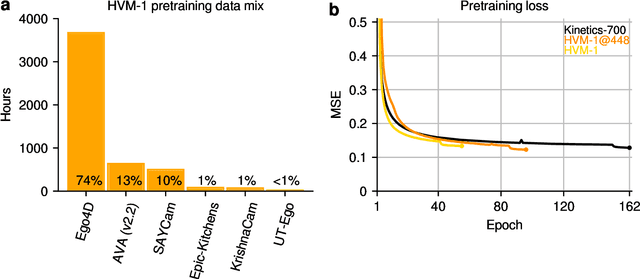
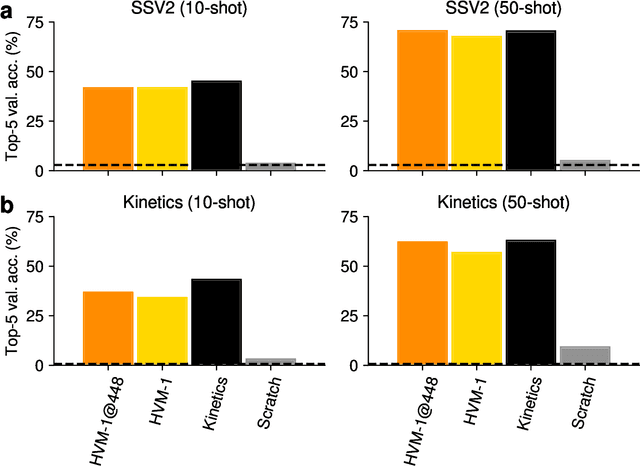
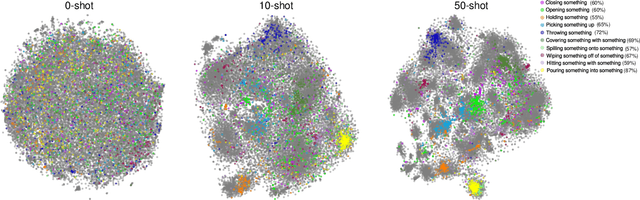
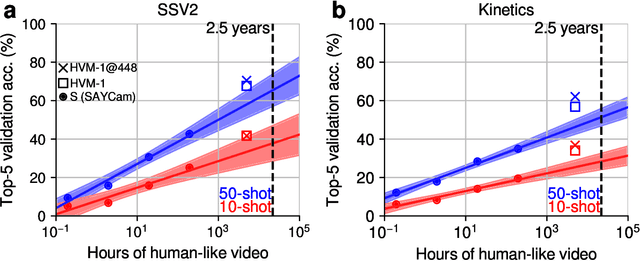
We introduce Human-like Video Models (HVM-1), large-scale video models pretrained with nearly 5000 hours of curated human-like video data (mostly egocentric, temporally extended, continuous video recordings), using the spatiotemporal masked autoencoder (ST-MAE) algorithm. We release two 633M parameter models trained at spatial resolutions of 224x224 and 448x448 pixels. We evaluate the performance of these models in downstream few-shot video and image recognition tasks and compare them against a model pretrained with 1330 hours of short action-oriented video clips from YouTube (Kinetics-700). HVM-1 models perform competitively against the Kinetics-700 pretrained model in downstream evaluations despite substantial qualitative differences between the spatiotemporal characteristics of the corresponding pretraining datasets. HVM-1 models also learn more accurate and more robust object representations compared to models pretrained with the image-based MAE algorithm on the same data, demonstrating the potential benefits of learning to predict temporal regularities in natural videos for learning better object representations.