 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional generalization in semantic parsing with pretrained transformers
Paper and Code
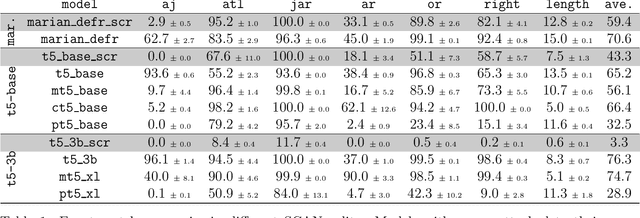
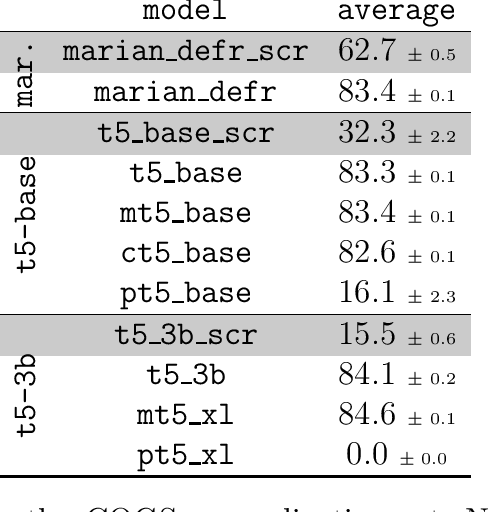
Large-scale pretraining instills large amounts of knowledge in deep neural networks. This, in turn, improves the generalization behavior of these models in downstream tasks. What exactly are the limits to the generalization benefits of large-scale pretraining? Here, we report observations from some simple experiments aimed at addressing this question in the context of two semantic parsing tasks involving natural language, SCAN and COGS. We show that language models pretrained exclusively with non-English corpora, or even with programming language corpora, significantly improve out-of-distribution generalization in these benchmarks, compared with models trained from scratch, even though both benchmarks are English-based. This demonstrates the surprisingly broad transferability of pretrained representations and knowledge. Pretraining with a large-scale protein sequence prediction task, on the other hand, mostly deteriorates the generalization performance in SCAN and COGS, suggesting that pretrained representations do not transfer universally and that there are constraints on the similarity between the pretraining and downstream domains for successful transfer. Finally, we show that larger models are harder to train from scratch and their generalization accuracy is lower when trained up to convergence on the relatively small SCAN and COGS datasets, but the benefits of large-scale pretraining become much clearer with larger models.