 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognition, recall, and retention of few-shot memories in large language models
Paper and Code
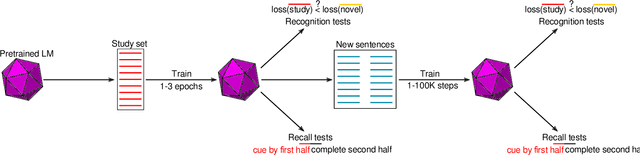
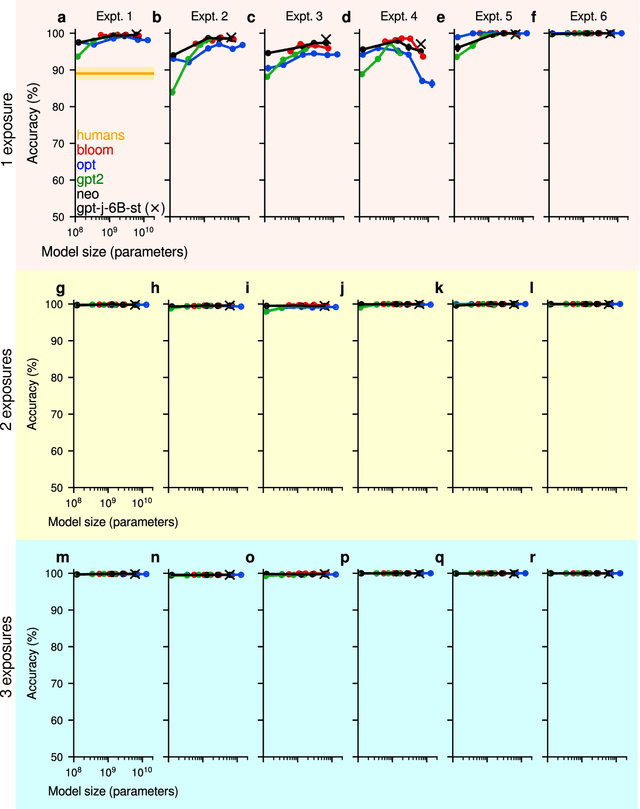
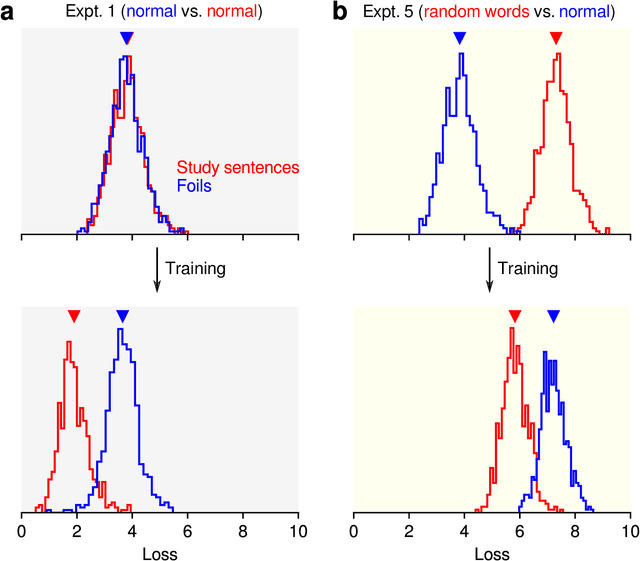
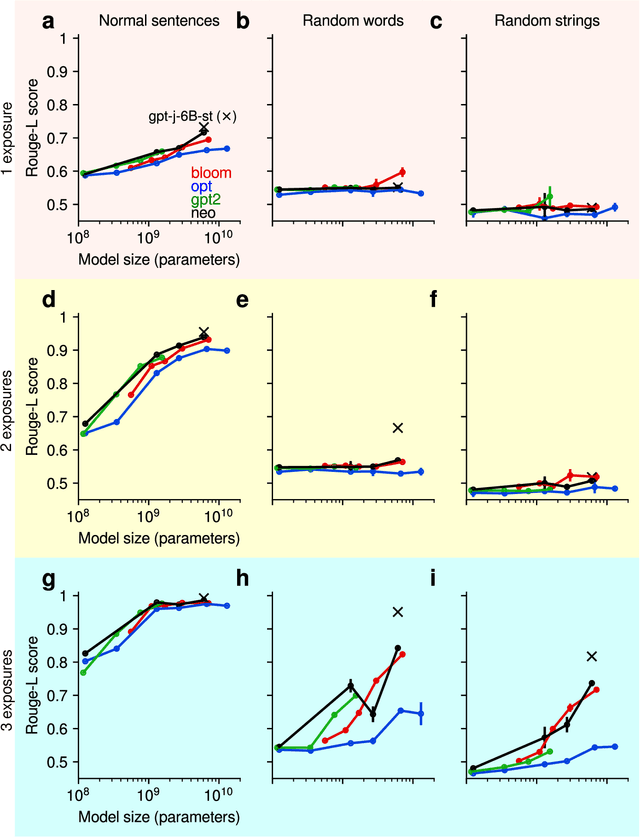
The training of modern large language models (LLMs) takes place in a regime where most training examples are seen only a few times by the model during the course of training. What does a model remember about such examples seen only a few times during training and how long does that memory persist in the face of continuous training with new examples? Here, we investigate these questions through simple recognition, recall, and retention experiments with LLMs. In recognition experiments, we ask if the model can distinguish the seen example from a novel example; in recall experiments, we ask if the model can correctly recall the seen example when cued by a part of it; and in retention experiments, we periodically probe the model's memory for the original examples as the model is trained continuously with new examples. We find that a single exposure is generally sufficient for a model to achieve near perfect accuracy even in very challenging recognition experiments. We estimate that the recognition performance of even small language models easily exceeds human recognition performance reported in similar experiments with humans (Shepard, 1967). Achieving near perfect recall takes more exposures, but most models can do it in just 3 exposures. The flip side of this remarkable capacity for fast learning is that precise memories are quickly overwritten: recall performance for the original examples drops steeply over the first 10 training updates with new examples, followed by a more gradual decline. Even after 100K updates, however, some of the original examples are still recalled near perfectly. A qualitatively similar retention pattern has been observed in human long-term memory retention studies before (Bahrick, 1984). Finally, recognition is much more robust to interference than recall and memory for natural language sentences is generally superior to memory for stimuli without structure.