 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional learning of functions in humans and machines
Paper and Code
Mar 18, 2024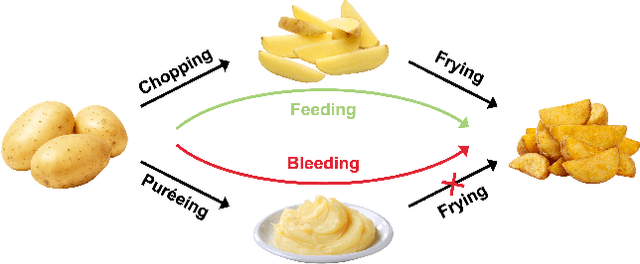
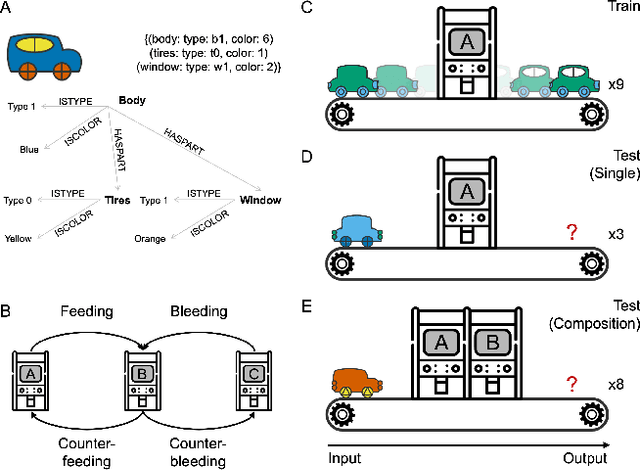
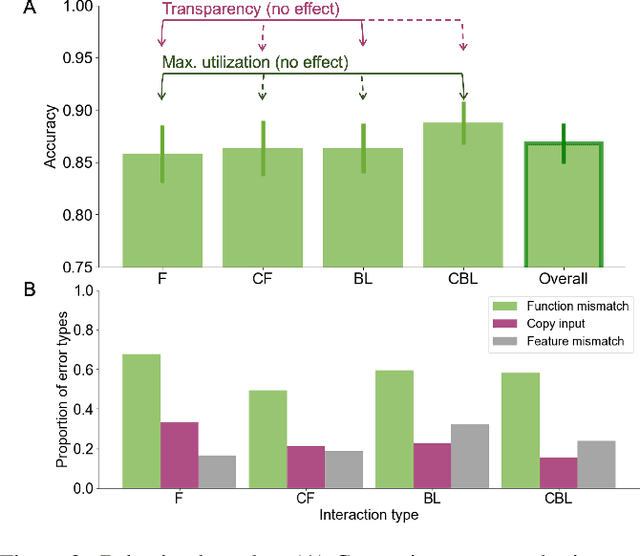
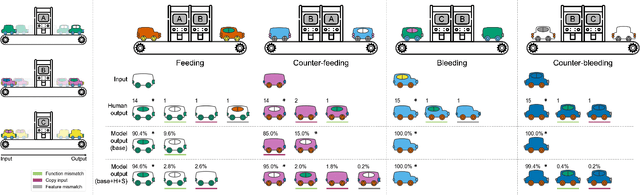
The ability to learn and compose functions is foundational to efficient learning and reasoning in humans, enabling flexible generalizations such as creating new dishes from known cooking processes. Beyond sequential chaining of functions, existing linguistics literature indicates that humans can grasp more complex compositions with interacting functions, where output production depends on context changes induced by different function orderings. Extending the investigation into the visual domain, we developed a function learning paradigm to explore the capacity of humans and neural network models in learning and reasoning with compositional functions under varied interaction conditions. Following brief training on individual functions, human participants were assessed on composing two learned functions, in ways covering four main interaction types, including instances in which the application of the first function creates or removes the context for applying the second function. Our findings indicate that humans can make zero-shot generalizations on novel visual function compositions across interaction conditions, demonstrating sensitivity to contextual changes. A comparison with a neural network model on the same task reveals that, through the meta-learning for compositionality (MLC) approach, a standard sequence-to-sequence Transformer can mimic human generalization patterns in composing functions.