 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-and-Language Training Helps Deploy Taxonomic Knowledge but Does Not Fundamentally Alter It
Jul 17, 2025Does vision-and-language (VL) training change the linguistic representations of language models in meaningful ways? Most results in the literature have shown inconsistent or marginal differences, both behaviorally and representationally. In this work, we start from the hypothesis that the domain in which VL training could have a significant effect is lexical-conceptual knowledge, in particular its taxonomic organization. Through comparing minimal pairs of text-only LMs and their VL-trained counterparts, we first show that the VL models often outperform their text-only counterparts on a text-only question-answering task that requires taxonomic understanding of concepts mentioned in the questions. Using an array of targeted behavioral and representational analyses, we show that the LMs and VLMs do not differ significantly in terms of their taxonomic knowledge itself, but they differ in how they represent questions that contain concepts in a taxonomic relation vs. a non-taxonomic relation. This implies that the taxonomic knowledge itself does not change substantially through additional VL training, but VL training does improve the deployment of this knowledge in the context of a specific task, even when the presentation of the task is purely linguistic.
A systematic investigation of learnability from single child linguistic input
Feb 12, 2024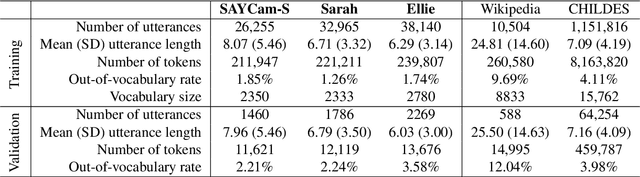
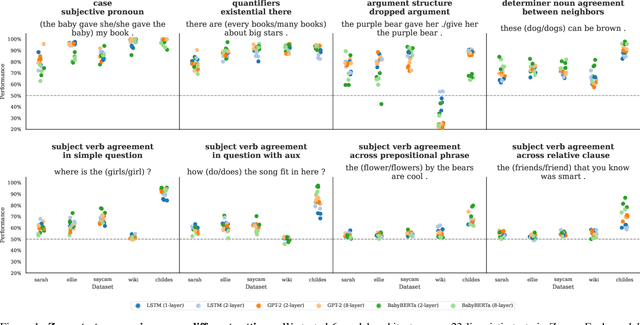


Language models (LMs) have demonstrated remarkable proficiency in generating linguistically coherent text, sparking discussions about their relevance to understanding human language learnability. However, a significant gap exists between the training data for these models and the linguistic input a child receives. LMs are typically trained on data that is orders of magnitude larger and fundamentally different from child-directed speech (Warstadt and Bowman, 2022; Warstadt et al., 2023; Frank, 2023a). Addressing this discrepancy, our research focuses on training LMs on subsets of a single child's linguistic input. Previously, Wang, Vong, Kim, and Lake (2023) found that LMs trained in this setting can form syntactic and semantic word clusters and develop sensitivity to certain linguistic phenomena, but they only considered LSTMs and simpler neural networks trained from just one single-child dataset. Here, to examine the robustness of learnability from single-child input, we systematically train six different model architectures on five datasets (3 single-child and 2 baselines). We find that the models trained on single-child datasets showed consistent results that matched with previous work, underscoring the robustness of forming meaningful syntactic and semantic representations from a subset of a child's linguistic input.