 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-ARC: A Robust Estimate of Human Performance on the Abstraction and Reasoning Corpus Benchmark
Paper and Code
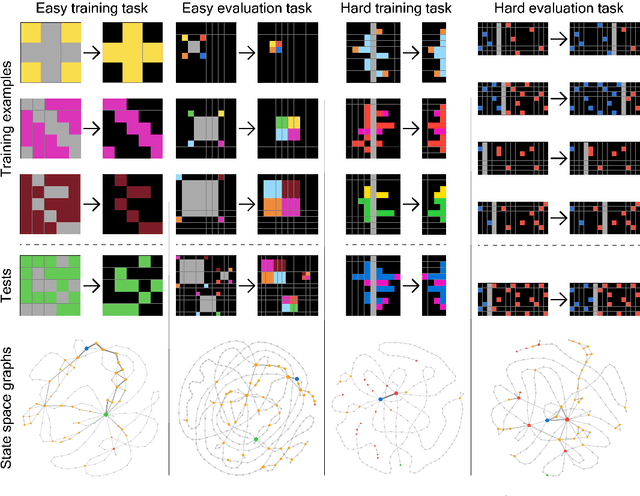
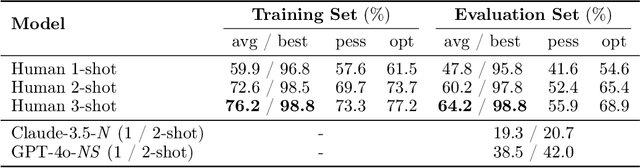
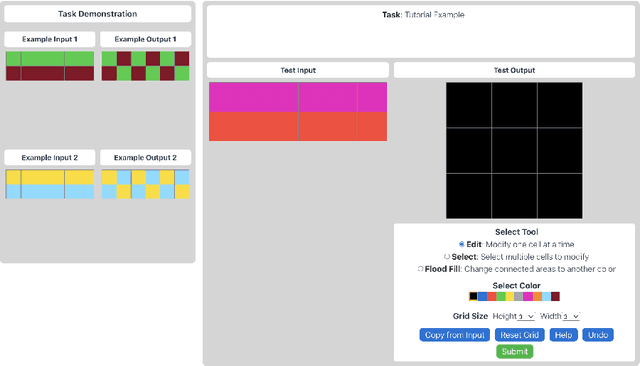
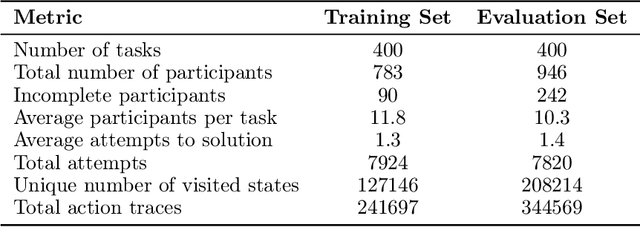
The Abstraction and Reasoning Corpus (ARC) is a visual program synthesis benchmark designed to test challenging out-of-distribution generalization in humans and machines. Since 2019, limited progress has been observed on the challenge using existing artificial intelligence methods. Comparing human and machine performance is important for the validity of the benchmark. While previous work explored how well humans can solve tasks from the ARC benchmark, they either did so using only a subset of tasks from the original dataset, or from variants of ARC, and therefore only provided a tentative estimate of human performance. In this work, we obtain a more robust estimate of human performance by evaluating 1729 humans on the full set of 400 training and 400 evaluation tasks from the original ARC problem set. We estimate that average human performance lies between 73.3% and 77.2% correct with a reported empirical average of 76.2% on the training set, and between 55.9% and 68.9% correct with a reported empirical average of 64.2% on the public evaluation set. However, we also find that 790 out of the 800 tasks were solvable by at least one person in three attempts, suggesting that the vast majority of the publicly available ARC tasks are in principle solvable by typical crowd-workers recruited over the internet. Notably, while these numbers are slightly lower than earlier estimates, human performance still greatly exceeds current state-of-the-art approaches for solving ARC. To facilitate research on ARC, we publicly release our dataset, called H-ARC (human-ARC), which includes all of the submissions and action traces from human participants.