 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised video pretraining yields strong image representations
Paper and Code
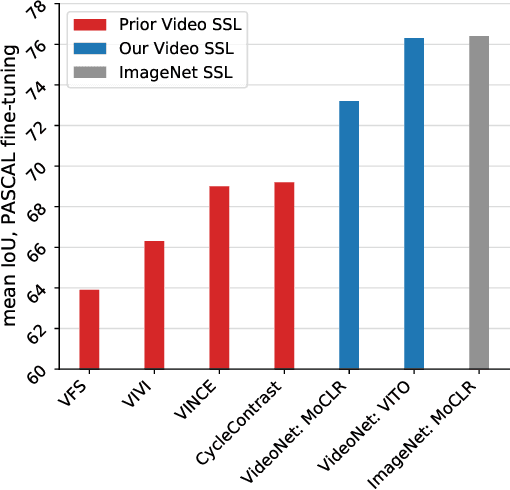
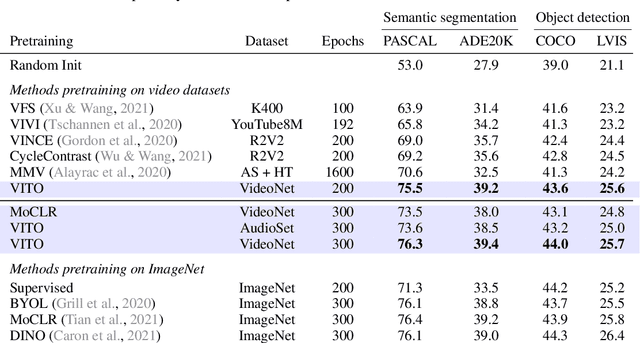
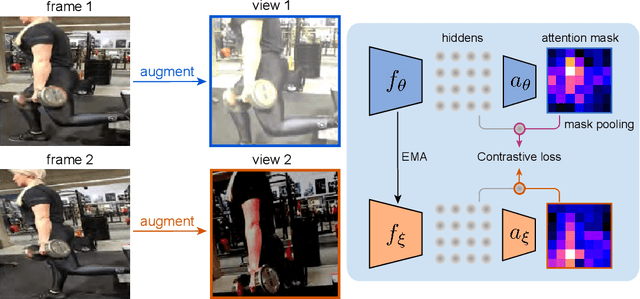
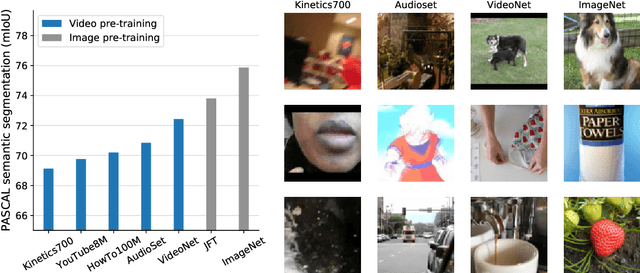
Videos contain far more information than still images and hold the potential for learning rich representations of the visual world. Yet, pretraining on image datasets has remained the dominant paradigm for learning representations that capture spatial information, and previous attempts at video pretraining have fallen short on image understanding tasks. In this work we revisit self-supervised learning of image representations from the dynamic evolution of video frames. To that end, we propose a dataset curation procedure that addresses the domain mismatch between video and image datasets, and develop a contrastive learning framework which handles the complex transformations present in natural videos. This simple paradigm for distilling knowledge from videos to image representations, called VITO, performs surprisingly well on a variety of image-based transfer learning tasks. For the first time, our video-pretrained model closes the gap with ImageNet pretraining on semantic segmentation on PASCAL and ADE20K and object detection on COCO and LVIS, suggesting that video-pretraining could become the new default for learning image representations.