 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Creative Short Story Generation in Humans and Large Language Models
Nov 04, 2024



Storytelling is a fundamental aspect of human communication, relying heavily on creativity to produce narratives that are novel, appropriate, and surprising. While large language models (LLMs) have recently demonstrated the ability to generate high-quality stories, their creative capabilities remain underexplored. Previous research has either focused on creativity tests requiring short responses or primarily compared model performance in story generation to that of professional writers. However, the question of whether LLMs exhibit creativity in writing short stories on par with the average human remains unanswered. In this work, we conduct a systematic analysis of creativity in short story generation across LLMs and everyday people. Using a five-sentence creative story task, commonly employed in psychology to assess human creativity, we automatically evaluate model- and human-generated stories across several dimensions of creativity, including novelty, surprise, and diversity. Our findings reveal that while LLMs can generate stylistically complex stories, they tend to fall short in terms of creativity when compared to average human writers.
Characterising the Creative Process in Humans and Large Language Models
May 01, 2024


Large language models appear quite creative, often performing on par with the average human on creative tasks. However, research on LLM creativity has focused solely on \textit{products}, with little attention on the creative \textit{process}. Process analyses of human creativity often require hand-coded categories or exploit response times, which do not apply to LLMs. We provide an automated method to characterise how humans and LLMs explore semantic spaces on the Alternate Uses Task, and contrast with behaviour in a Verbal Fluency Task. We use sentence embeddings to identify response categories and compute semantic similarities, which we use to generate jump profiles. Our results corroborate earlier work in humans reporting both persistent (deep search in few semantic spaces) and flexible (broad search across multiple semantic spaces) pathways to creativity, where both pathways lead to similar creativity scores. LLMs were found to be biased towards either persistent or flexible paths, that varied across tasks. Though LLMs as a population match human profiles, their relationship with creativity is different, where the more flexible models score higher on creativity. Our dataset and scripts are available on \href{https://github.com/surabhisnath/Creative_Process}{GitHub}.
Putting GPT-3's Creativity to the Test
Jun 10, 2022
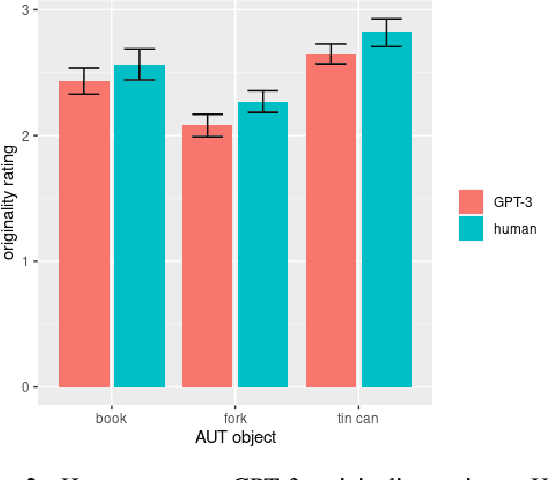
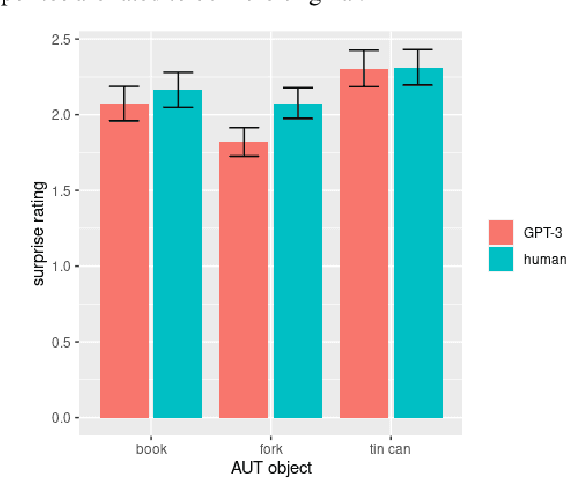
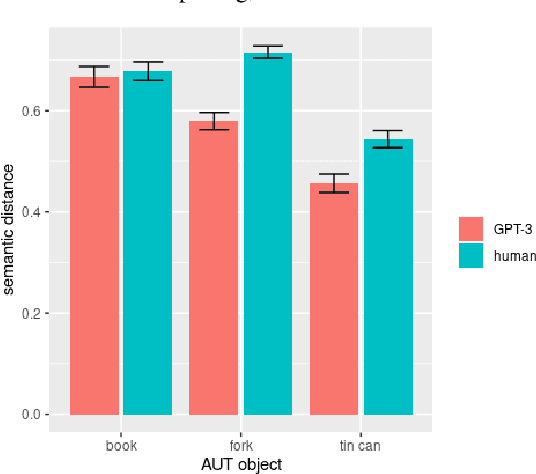
AI large language models have (co-)produced amazing written works from newspaper articles to novels and poetry. These works meet the standards of the standard definition of creativity: being original and useful, and sometimes even the additional element of surprise. But can a large language model designed to predict the next text fragment provide creative, out-of-the-box, responses that still solve the problem at hand? We put Open AI's generative natural language model, GPT-3, to the test. Can it provide creative solutions to one of the most commonly used tests in creativity research? We assessed GPT-3's creativity on Guilford's Alternative Uses Test and compared its performance to previously collected human responses on expert ratings of originality, usefulness and surprise of responses, flexibility of each set of ideas as well as an automated method to measure creativity based on the semantic distance between a response and the AUT object in question. Our results show that -- on the whole -- humans currently outperform GPT-3 when it comes to creative output. But, we believe it is only a matter of time before GPT-3 catches up on this particular task. We discuss what this work reveals about human and AI creativity, creativity testing and our definition of creativity.