 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced User Interaction in Operating Systems through Machine Learning Language Models
Feb 24, 2024With the large language model showing human-like logical reasoning and understanding ability, whether agents based on the large language model can simulate the interaction behavior of real users, so as to build a reliable virtual recommendation A/B test scene to help the application of recommendation research is an urgent, important and economic value problem. The combination of interaction design and machine learning can provide a more efficient and personalized user experience for products and services. This personalized service can meet the specific needs of users and improve user satisfaction and loyalty. Second, the interactive system can understand the user's views and needs for the product by providing a good user interface and interactive experience, and then use machine learning algorithms to improve and optimize the product. This iterative optimization process can continuously improve the quality and performance of the product to meet the changing needs of users. At the same time, designers need to consider how these algorithms and tools can be combined with interactive systems to provide a good user experience. This paper explores the potential applications of large language models, machine learning and interaction design for user interaction in recommendation systems and operating systems. By integrating these technologies, more intelligent and personalized services can be provided to meet user needs and promote continuous improvement and optimization of products. This is of great value for both recommendation research and user experience applications.
Enhancing Cloud-Based Large Language Model Processing with Elasticsearch and Transformer Models
Feb 24, 2024



Large Language Models (LLMs) are a class of generative AI models built using the Transformer network, capable of leveraging vast datasets to identify, summarize, translate, predict, and generate language. LLMs promise to revolutionize society, yet training these foundational models poses immense challenges. Semantic vector search within large language models is a potent technique that can significantly enhance search result accuracy and relevance. Unlike traditional keyword-based search methods, semantic search utilizes the meaning and context of words to grasp the intent behind queries and deliver more precise outcomes. Elasticsearch emerges as one of the most popular tools for implementing semantic search an exceptionally scalable and robust search engine designed for indexing and searching extensive datasets. In this article, we delve into the fundamentals of semantic search and explore how to harness Elasticsearch and Transformer models to bolster large language model processing paradigms. We gain a comprehensive understanding of semantic search principles and acquire practical skills for implementing semantic search in real-world model application scenarios.
Data Pipeline Training: Integrating AutoML to Optimize the Data Flow of Machine Learning Models
Feb 20, 2024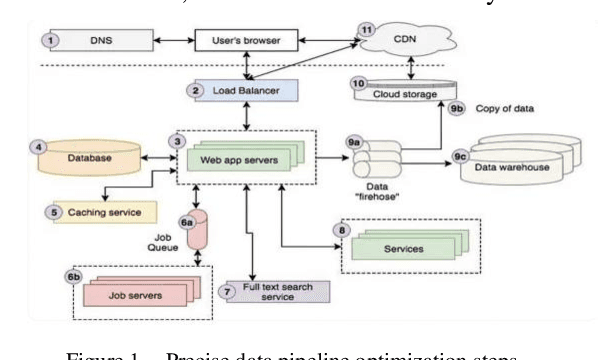
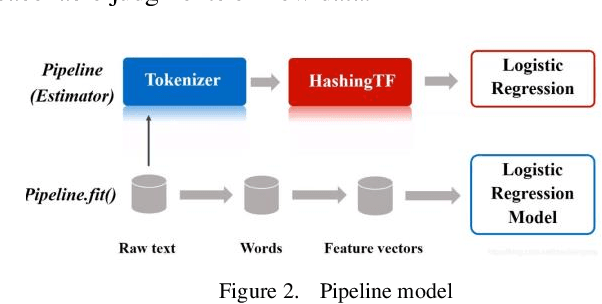
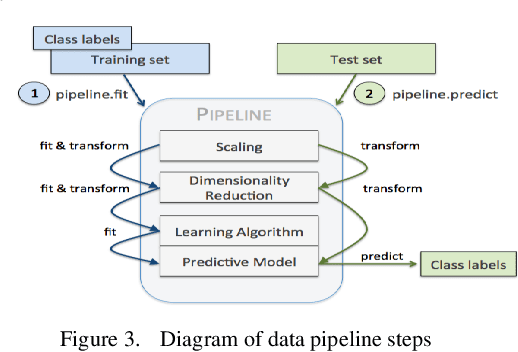
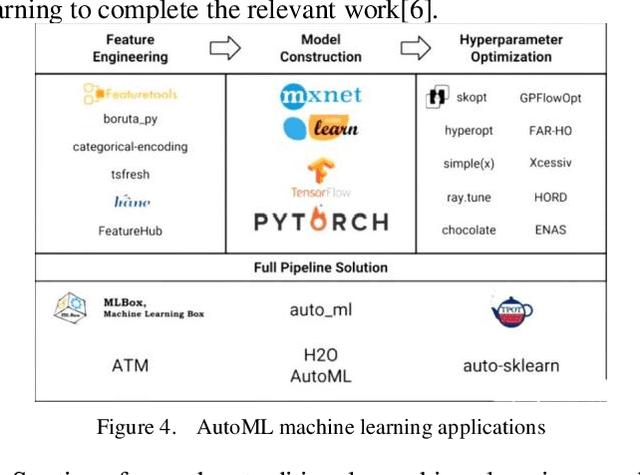
Data Pipeline plays an indispensable role in tasks such as modeling machine learning and developing data products. With the increasing diversification and complexity of Data sources, as well as the rapid growth of data volumes, building an efficient Data Pipeline has become crucial for improving work efficiency and solving complex problems. This paper focuses on exploring how to optimize data flow through automated machine learning methods by integrating AutoML with Data Pipeline. We will discuss how to leverage AutoML technology to enhance the intelligence of Data Pipeline, thereby achieving better results in machine learning tasks. By delving into the automation and optimization of Data flows, we uncover key strategies for constructing efficient data pipelines that can adapt to the ever-changing data landscape. This not only accelerates the modeling process but also provides innovative solutions to complex problems, enabling more significant outcomes in increasingly intricate data domains. Keywords- Data Pipeline Training;AutoML; Data environment; Machine learning