 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-ICL: Zero-Shot In-Context Learning with Self-Generated Demonstrations
Paper and Code
May 24, 2023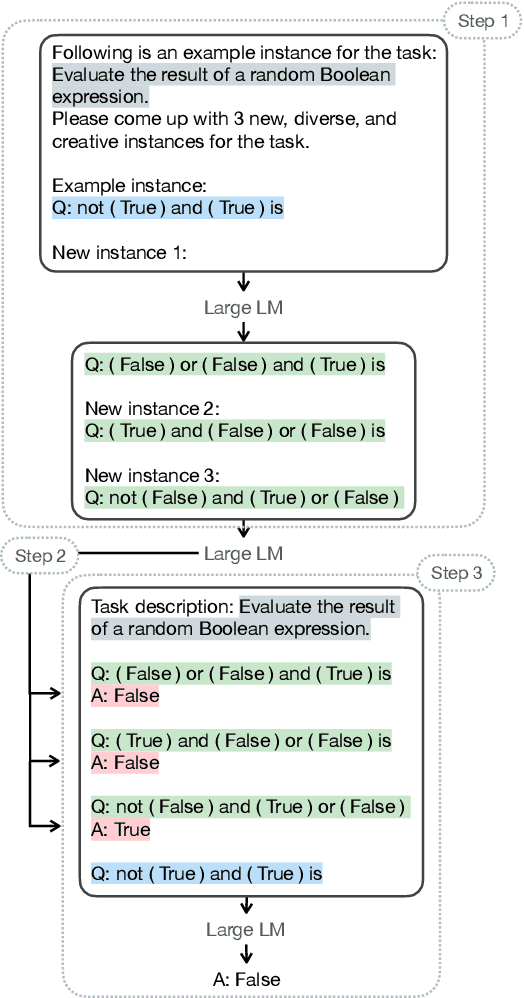


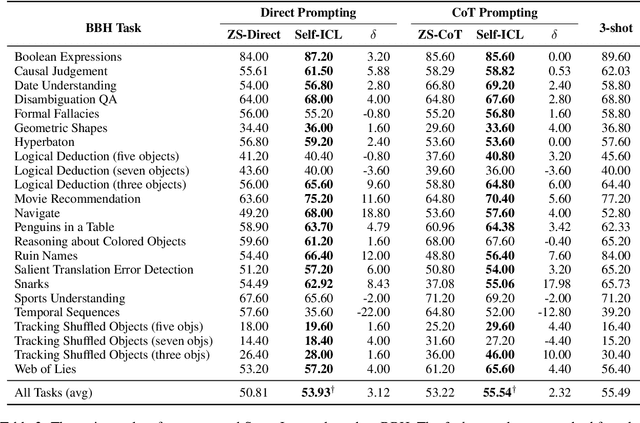
Large language models (LMs) have exhibited superior in-context learning (ICL) ability to adopt to target tasks by prompting with a few input-output demonstrations. Towards better ICL, different methods are proposed to select representative demonstrations from existing training corpora. However, such a setting is not aligned with real-world practices, as end-users usually query LMs without accesses to demonstration pools. Inspired by evidence suggesting LMs' zero-shot capabilities are underrated, and the role of demonstrations are primarily for exposing models' intrinsic functionalities, we introduce Self-ICL, a simple framework for zero-shot ICL. Given a test input, Self-ICL first prompts the model to generate pseudo-inputs. Next, the model predicts pseudo-labels for the pseudo-inputs via zero-shot prompting. Finally, we construct pseudo-demonstrations from pseudo-input-label pairs, and perform ICL for the test input. Evaluation on BIG-Bench Hard shows Self-ICL steadily surpasses zero-shot and zero-shot chain-of-thought baselines on head-to-head and all-task average performance. Our findings suggest the possibility to bootstrap LMs' intrinsic capabilities towards better zero-shot performance.