 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSonicBench: Dissecting the Physical Perception Bottleneck in Large Audio Language Models
Jan 16, 2026Large Audio Language Models (LALMs) excel at semantic and paralinguistic tasks, yet their ability to perceive the fundamental physical attributes of audio such as pitch, loudness, and spatial location remains under-explored. To bridge this gap, we introduce SonicBench, a psychophysically grounded benchmark that systematically evaluates 12 core physical attributes across five perceptual dimensions. Unlike previous datasets, SonicBench uses a controllable generation toolbox to construct stimuli for two complementary paradigms: recognition (absolute judgment) and comparison (relative judgment). This design allows us to probe not only sensory precision but also relational reasoning capabilities, a domain where humans typically exhibit greater proficiency. Our evaluation reveals a substantial deficiency in LALMs' foundational auditory understanding; most models perform near random guessing and, contrary to human patterns, fail to show the expected advantage on comparison tasks. Furthermore, explicit reasoning yields minimal gains. However, our linear probing analysis demonstrates crucially that frozen audio encoders do successfully capture these physical cues (accuracy at least 60%), suggesting that the primary bottleneck lies in the alignment and decoding stages, where models fail to leverage the sensory signals they have already captured.
The Few Govern the Many:Unveiling Few-Layer Dominance for Time Series Models
Nov 10, 2025Large-scale models are at the forefront of time series (TS) forecasting, dominated by two paradigms: fine-tuning text-based Large Language Models (LLM4TS) and training Time Series Foundation Models (TSFMs) from scratch. Both approaches share a foundational assumption that scaling up model capacity and data volume leads to improved performance. However, we observe a \textit{\textbf{scaling paradox}} in TS models, revealing a puzzling phenomenon that larger models do \emph{NOT} achieve better performance. Through extensive experiments on two model families across four scales (100M to 1.7B parameters) and diverse data (up to 6B observations), we rigorously confirm that the scaling paradox is a pervasive issue. We then diagnose its root cause by analyzing internal representations, identifying a phenomenon we call \textit{few-layer dominance}: only a small subset of layers are functionally important, while the majority are redundant, under-utilized, and can even distract training. Based on this discovery, we propose a practical method to automatically identify and retain only these dominant layers. In our models, retaining only 21\% of the parameters achieves up to a 12\% accuracy improvement and a 2.7$\times$ inference speedup. We validate the universality of our method on 8 prominent SOTA models (LLM4TS and TSFMs, 90M to 6B), showing that retaining less than 30\% of layers achieves comparable or superior accuracy in over 95\% of tasks.
PRISM: Preference Refinement via Implicit Scene Modeling for 3D Vision-Language Preference-Based Reinforcement Learning
Mar 13, 2025We propose PRISM, a novel framework designed to overcome the limitations of 2D-based Preference-Based Reinforcement Learning (PBRL) by unifying 3D point cloud modeling and future-aware preference refinement. At its core, PRISM adopts a 3D Point Cloud-Language Model (3D-PC-LLM) to mitigate occlusion and viewpoint biases, ensuring more stable and spatially consistent preference signals. Additionally, PRISM leverages Chain-of-Thought (CoT) reasoning to incorporate long-horizon considerations, thereby preventing the short-sighted feedback often seen in static preference comparisons. In contrast to conventional PBRL techniques, this integration of 3D perception and future-oriented reasoning leads to significant gains in preference agreement rates, faster policy convergence, and robust generalization across unseen robotic environments. Our empirical results, spanning tasks such as robotic manipulation and autonomous navigation, highlight PRISM's potential for real-world applications where precise spatial understanding and reliable long-term decision-making are critical. By bridging 3D geometric awareness with CoT-driven preference modeling, PRISM establishes a comprehensive foundation for scalable, human-aligned reinforcement learning.
Integrating Chain-of-Thought for Multimodal Alignment: A Study on 3D Vision-Language Learning
Mar 08, 2025Chain-of-Thought (CoT) reasoning has proven effective in natural language tasks but remains underexplored in multimodal alignment. This study investigates its integration into 3D vision-language learning by embedding structured reasoning into alignment training. We introduce the 3D-CoT Benchmark, a dataset with hierarchical CoT annotations covering shape recognition, functional inference, and causal reasoning. Through controlled experiments, we compare CoT-structured and standard textual annotations across large reasoning models (LRMs) and large language models (LLMs). Our evaluation employs a dual-layer framework assessing both intermediate reasoning and final inference quality. Extensive experiments demonstrate that CoT significantly improves 3D semantic grounding, with LRMs leveraging CoT more effectively than LLMs. Furthermore, we highlight that annotation structure influences performance-explicit reasoning markers aid LLMs, while unmarked CoT better aligns with LRM inference patterns. Our analyses suggest that CoT is crucial for enhancing multimodal reasoning, with implications beyond 3D tasks.
Unveiling the Key Factors for Distilling Chain-of-Thought Reasoning
Feb 25, 2025



Large Language Models (LLMs) excel in reasoning tasks through Chain-of-Thought (CoT) prompting. However, CoT prompting greatly increases computational demands, which has prompted growing interest in distilling CoT capabilities into Small Language Models (SLMs). This study systematically examines the factors influencing CoT distillation, including the choice of granularity, format and teacher model. Through experiments involving four teacher models and seven student models across seven mathematical and commonsense reasoning datasets, we uncover three key findings: (1) Unlike LLMs, SLMs exhibit a non-monotonic relationship with granularity, with stronger models benefiting from finer-grained reasoning and weaker models performing better with simpler CoT supervision; (2) CoT format significantly impacts LLMs but has minimal effect on SLMs, likely due to their reliance on supervised fine-tuning rather than pretraining preferences; (3) Stronger teacher models do NOT always produce better student models, as diversity and complexity in CoT supervision can outweigh accuracy alone. These findings emphasize the need to tailor CoT strategies to specific student model, offering actionable insights for optimizing CoT distillation in SLMs. The code and datasets are available at https://github.com/EIT-NLP/Distilling-CoT-Reasoning.
Instruction-Tuned LLMs Succeed in Document-Level MT Without Fine-Tuning -- But BLEU Turns a Blind Eye
Oct 29, 2024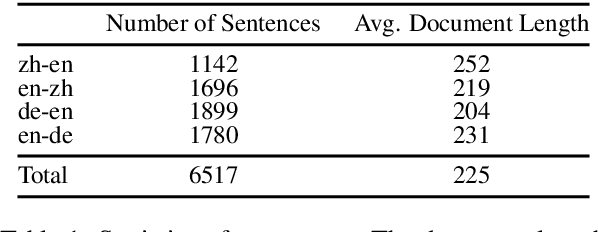
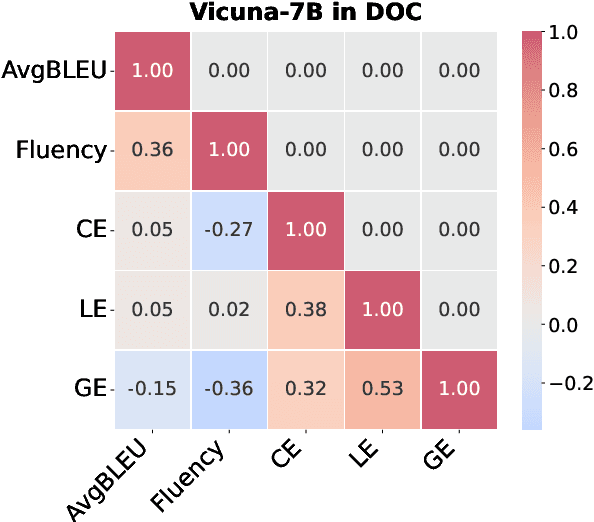
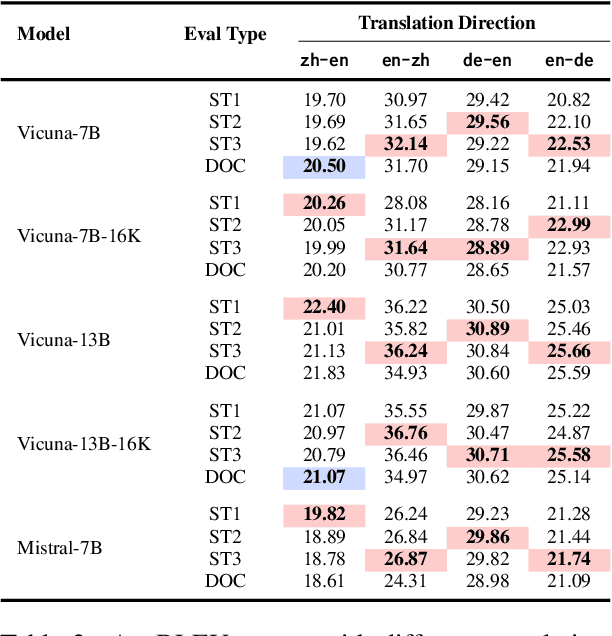
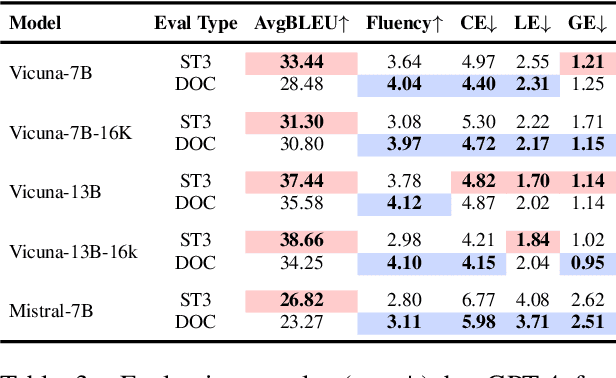
Large language models (LLMs) have excelled in various NLP tasks, including machine translation (MT), yet most studies focus on sentence-level translation. This work investigates the inherent capability of instruction-tuned LLMs for document-level translation (docMT). Unlike prior approaches that require specialized techniques, we evaluate LLMs by directly prompting them to translate entire documents in a single pass. Our results show that this method improves translation quality compared to translating sentences separately, even without document-level fine-tuning. However, this advantage is not reflected in BLEU scores, which often favor sentence-based translations. We propose using the LLM-as-a-judge paradigm for evaluation, where GPT-4 is used to assess document coherence, accuracy, and fluency in a more nuanced way than n-gram-based metrics. Overall, our work demonstrates that instruction-tuned LLMs can effectively leverage document context for translation. However, we caution against using BLEU scores for evaluating docMT, as they often provide misleading outcomes, failing to capture the quality of document-level translation. Code and data are available at https://github.com/EIT-NLP/BLEUless_DocMT
The Accuracy Paradox in RLHF: When Better Reward Models Don't Yield Better Language Models
Oct 09, 2024Reinforcement Learning from Human Feedback significantly enhances Natural Language Processing by aligning language models with human expectations. A critical factor in this alignment is the strength of reward models used during training. This study explores whether stronger reward models invariably lead to better language models. In this paper, through experiments on relevance, factuality, and completeness tasks using the QA-FEEDBACK dataset and reward models based on Longformer, we uncover a surprising paradox: language models trained with moderately accurate reward models outperform those guided by highly accurate ones. This challenges the widely held belief that stronger reward models always lead to better language models, and opens up new avenues for future research into the key factors driving model performance and how to choose the most suitable reward models. Code and additional details are available at [https://github.com/EIT-NLP/AccuracyParadox-RLHF](https://github.com/EIT-NLP/AccuracyParadox-RLHF).