 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning for Epileptic Seizure Prediction Across Heterogeneous EEG Datasets
Aug 11, 2025Developing accurate and generalizable epileptic seizure prediction models from electroencephalography (EEG) data across multiple clinical sites is hindered by patient privacy regulations and significant data heterogeneity (non-IID characteristics). Federated Learning (FL) offers a privacy-preserving framework for collaborative training, but standard aggregation methods like Federated Averaging (FedAvg) can be biased by dominant datasets in heterogeneous settings. This paper investigates FL for seizure prediction using a single EEG channel across four diverse public datasets (Siena, CHB-MIT, Helsinki, NCH), representing distinct patient populations (adult, pediatric, neonate) and recording conditions. We implement privacy-preserving global normalization and propose a Random Subset Aggregation strategy, where each client trains on a fixed-size random subset of its data per round, ensuring equal contribution during aggregation. Our results show that locally trained models fail to generalize across sites, and standard weighted FedAvg yields highly skewed performance (e.g., 89.0% accuracy on CHB-MIT but only 50.8% on Helsinki and 50.6% on NCH). In contrast, Random Subset Aggregation significantly improves performance on under-represented clients (accuracy increases to 81.7% on Helsinki and 68.7% on NCH) and achieves a superior macro-average accuracy of 77.1% and pooled accuracy of 80.0% across all sites, demonstrating a more robust and fair global model. This work highlights the potential of balanced FL approaches for building effective and generalizable seizure prediction systems in realistic, heterogeneous multi-hospital environments while respecting data privacy.
Privacy Preserving Federated Unsupervised Domain Adaptation with Application to Age Prediction from DNA Methylation Data
Nov 26, 2024In computational biology, predictive models are widely used to address complex tasks, but their performance can suffer greatly when applied to data from different distributions. The current state-of-the-art domain adaptation method for high-dimensional data aims to mitigate these issues by aligning the input dependencies between training and test data. However, this approach requires centralized access to both source and target domain data, raising concerns about data privacy, especially when the data comes from multiple sources. In this paper, we introduce a privacy-preserving federated framework for unsupervised domain adaptation in high-dimensional settings. Our method employs federated training of Gaussian processes and weighted elastic nets to effectively address the problem of distribution shift between domains, while utilizing secure aggregation and randomized encoding to protect the local data of participating data owners. We evaluate our framework on the task of age prediction using DNA methylation data from multiple tissues, demonstrating that our approach performs comparably to existing centralized methods while maintaining data privacy, even in distributed environments where data is spread across multiple institutions. Our framework is the first privacy-preserving solution for high-dimensional domain adaptation in federated environments, offering a promising tool for fields like computational biology and medicine, where protecting sensitive data is essential.
Private, Efficient and Scalable Kernel Learning for Medical Image Analysis
Oct 21, 2024Medical imaging is key in modern medicine. From magnetic resonance imaging (MRI) to microscopic imaging for blood cell detection, diagnostic medical imaging reveals vital insights into patient health. To predict diseases or provide individualized therapies, machine learning techniques like kernel methods have been widely used. Nevertheless, there are multiple challenges for implementing kernel methods. Medical image data often originates from various hospitals and cannot be combined due to privacy concerns, and the high dimensionality of image data presents another significant obstacle. While randomised encoding offers a promising direction, existing methods often struggle with a trade-off between accuracy and efficiency. Addressing the need for efficient privacy-preserving methods on distributed image data, we introduce OKRA (Orthonormal K-fRAmes), a novel randomized encoding-based approach for kernel-based machine learning. This technique, tailored for widely used kernel functions, significantly enhances scalability and speed compared to current state-of-the-art solutions. Through experiments conducted on various clinical image datasets, we evaluated model quality, computational performance, and resource overhead. Additionally, our method outperforms comparable approaches
Privacy Preserving Data Imputation via Multi-party Computation for Medical Applications
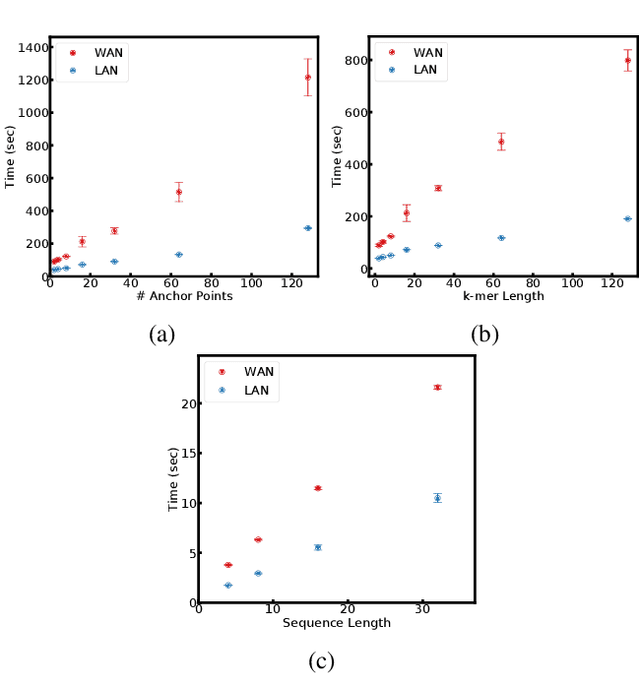
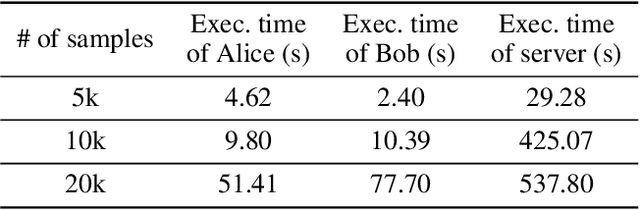
May 29, 2024Handling missing data is crucial in machine learning, but many datasets contain gaps due to errors or non-response. Unlike traditional methods such as listwise deletion, which are simple but inadequate, the literature offers more sophisticated and effective methods, thereby improving sample size and accuracy. However, these methods require accessing the whole dataset, which contradicts the privacy regulations when the data is distributed among multiple sources. Especially in the medical and healthcare domain, such access reveals sensitive information about patients. This study addresses privacy-preserving imputation methods for sensitive data using secure multi-party computation, enabling secure computations without revealing any party's sensitive information. In this study, we realized the mean, median, regression, and kNN imputation methods in a privacy-preserving way. We specifically target the medical and healthcare domains considering the significance of protection of the patient data, showcasing our methods on a diabetes dataset. Experiments on the diabetes dataset validated the correctness of our privacy-preserving imputation methods, yielding the largest error around $3 \times 10^{-3}$, closely matching plaintext methods. We also analyzed the scalability of our methods to varying numbers of samples, showing their applicability to real-world healthcare problems. Our analysis demonstrated that all our methods scale linearly with the number of samples. Except for kNN, the runtime of all our methods indicates that they can be utilized for large datasets.
Robust Representation Learning for Privacy-Preserving Machine Learning: A Multi-Objective Autoencoder Approach
Sep 08, 2023Several domains increasingly rely on machine learning in their applications. The resulting heavy dependence on data has led to the emergence of various laws and regulations around data ethics and privacy and growing awareness of the need for privacy-preserving machine learning (ppML). Current ppML techniques utilize methods that are either purely based on cryptography, such as homomorphic encryption, or that introduce noise into the input, such as differential privacy. The main criticism given to those techniques is the fact that they either are too slow or they trade off a model s performance for improved confidentiality. To address this performance reduction, we aim to leverage robust representation learning as a way of encoding our data while optimizing the privacy-utility trade-off. Our method centers on training autoencoders in a multi-objective manner and then concatenating the latent and learned features from the encoding part as the encoded form of our data. Such a deep learning-powered encoding can then safely be sent to a third party for intensive training and hyperparameter tuning. With our proposed framework, we can share our data and use third party tools without being under the threat of revealing its original form. We empirically validate our results on unimodal and multimodal settings, the latter following a vertical splitting system and show improved performance over state-of-the-art.
A Privacy-Preserving Federated Learning Approach for Kernel methods
Jun 05, 2023It is challenging to implement Kernel methods, if the data sources are distributed and cannot be joined at a trusted third party for privacy reasons. It is even more challenging, if the use case rules out privacy-preserving approaches that introduce noise. An example for such a use case is machine learning on clinical data. To realize exact privacy preserving computation of kernel methods, we propose FLAKE, a Federated Learning Approach for KErnel methods on horizontally distributed data. With FLAKE, the data sources mask their data so that a centralized instance can compute a Gram matrix without compromising privacy. The Gram matrix allows to calculate many kernel matrices, which can be used to train kernel-based machine learning algorithms such as Support Vector Machines. We prove that FLAKE prevents an adversary from learning the input data or the number of input features under a semi-honest threat model. Experiments on clinical and synthetic data confirm that FLAKE is outperforming the accuracy and efficiency of comparable methods. The time needed to mask the data and to compute the Gram matrix is several orders of magnitude less than the time a Support Vector Machine needs to be trained. Thus, FLAKE can be applied to many use cases.
CECILIA: Comprehensive Secure Machine Learning Framework
Feb 07, 2022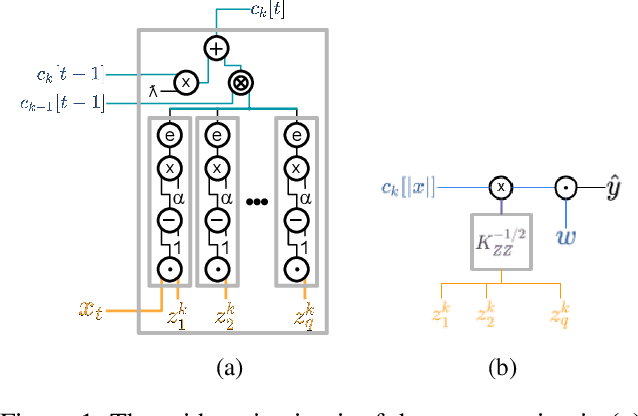

Since machine learning algorithms have proven their success in data mining tasks, the data with sensitive information enforce privacy preserving machine learning algorithms to emerge. Moreover, the increase in the number of data sources and the high computational power required by those algorithms force individuals to outsource the training and/or the inference of a machine learning model to the clouds providing such services. To address this dilemma, we propose a secure 3-party computation framework, CECILIA, offering privacy preserving building blocks to enable more complex operations privately. Among those building blocks, we have two novel methods, which are the exact exponential of a public base raised to the power of a secret value and the inverse square root of a secret Gram matrix. We employ CECILIA to realize the private inference on pre-trained recurrent kernel networks, which require more complex operations than other deep neural networks such as convolutional neural networks, on the structural classification of proteins as the first study ever accomplishing the privacy preserving inference on recurrent kernel networks. The results demonstrate that we perform the exact and fully private exponential computation, which is done by approximation in the literature so far. Moreover, we can also perform the exact inverse square root of a secret Gram matrix computation up to a certain privacy level, which has not been addressed in the literature at all. We also analyze the scalability of CECILIA to various settings on a synthetic dataset. The framework shows a great promise to make other machine learning algorithms as well as further computations privately computable by the building blocks of the framework.
ppAUC: Privacy Preserving Area Under the Curve with Secure 3-Party Computation
Feb 17, 2021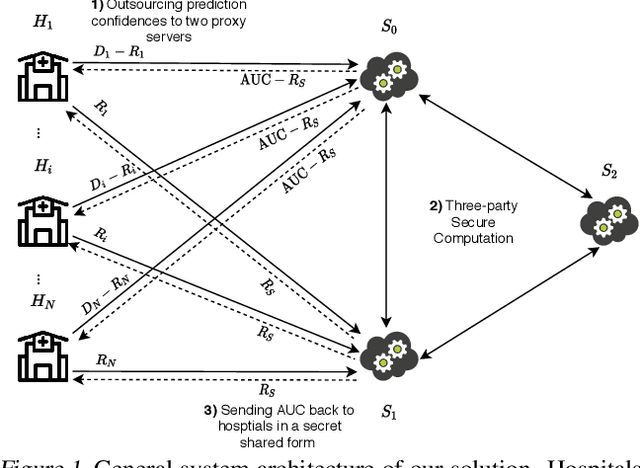
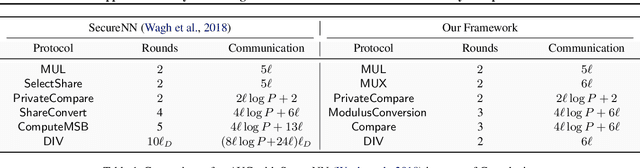
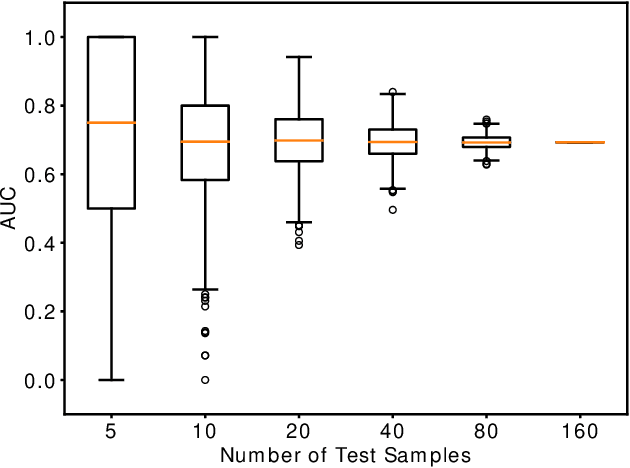
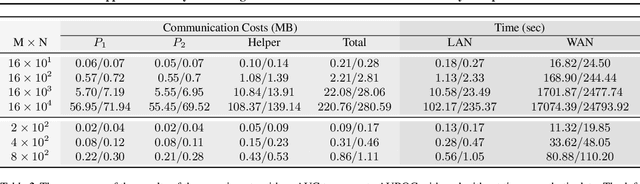
Computing an AUC as a performance measure to compare the quality of different machine learning models is one of the final steps of many research projects. Many of these methods are trained on privacy-sensitive data and there are several different approaches like $\epsilon$-differential privacy, federated machine learning and methods based on cryptographic approaches if the datasets cannot be shared or evaluated jointly at one place. In this setting, it can also be a problem to compute the global AUC, since the labels might also contain privacy-sensitive information. There have been approaches based on $\epsilon$-differential privacy to deal with this problem, but to the best of our knowledge, no exact privacy preserving solution has been introduced. In this paper, we propose an MPC-based framework, called privacy preserving AUC (ppAUC), with novel methods for comparing two secret-shared values, selecting between two secret-shared values, converting the modulus and performing division to compute the exact AUC as one could obtain on the pooled original test samples. We employ ppAUC in the computation of the exact area under precision-recall curve and receiver operating characteristic curve even for ties between prediction confidence values. To prove the correctness of ppAUC, we apply it to evaluate a model trained to predict acute myeloid leukemia therapy response and we also assess its scalability via experiments on synthetic data. The experiments show that we efficiently compute exactly the same AUC with both evaluation metrics in a privacy preserving manner as one can obtain on the pooled test samples in the plaintext domain. Our solution provides security against semi-honest corruption of at most one of the servers performing the secure computation.
ESCAPED: Efficient Secure and Private Dot Product Framework for Kernel-based Machine Learning Algorithms with Applications in Healthcare
Dec 04, 2020
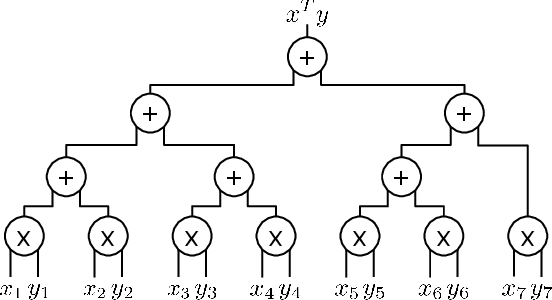
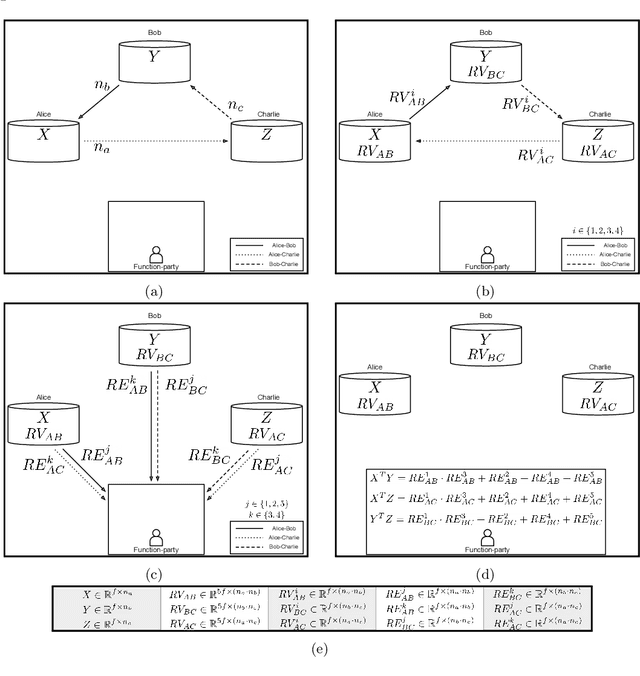
To train sophisticated machine learning models one usually needs many training samples. Especially in healthcare settings these samples can be very expensive, meaning that one institution alone usually does not have enough on its own. Merging privacy-sensitive data from different sources is usually restricted by data security and data protection measures. This can lead to approaches that reduce data quality by putting noise onto the variables (e.g., in $\epsilon$-differential privacy) or omitting certain values (e.g., for $k$-anonymity). Other measures based on cryptographic methods can lead to very time-consuming computations, which is especially problematic for larger multi-omics data. We address this problem by introducing ESCAPED, which stands for Efficient SeCure And PrivatE Dot product framework, enabling the computation of the dot product of vectors from multiple sources on a third-party, which later trains kernel-based machine learning algorithms, while neither sacrificing privacy nor adding noise. We evaluated our framework on drug resistance prediction for HIV-infected people and multi-omics dimensionality reduction and clustering problems in precision medicine. In terms of execution time, our framework significantly outperforms the best-fitting existing approaches without sacrificing the performance of the algorithm. Even though we only show the benefit for kernel-based algorithms, our framework can open up new research opportunities for further machine learning models that require the dot product of vectors from multiple sources.
Privacy Preserving Gaze Estimation using Synthetic Images via a Randomized Encoding Based Framework
Nov 06, 2019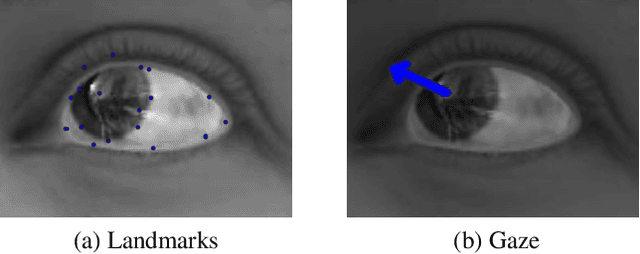
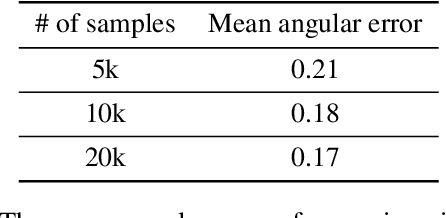
Eye tracking is handled as one of the key technologies for applications which assess and evaluate human attention, behavior and biometrics, especially using gaze, pupillary and blink behaviors. One of the main challenges with regard to the social acceptance of eye-tracking technology is however the preserving of sensitive and personal information. To tackle this challenge, we employed a privacy-preserving framework based on randomized encoding to train a Support Vector Regression model on synthetic eye images privately to estimate human gaze. During the computation, none of the parties learns about the data or the result that any other party has. Furthermore, the party that trains the model cannot reconstruct pupil, blink or visual scanpath. The experimental results showed that our privacy preserving framework is also capable of working in real-time, as accurate as a non-private version of it and could be extended to other eye-tracking related problems.