 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards unlocking the mystery of adversarial fragility of neural networks
Jun 23, 2024
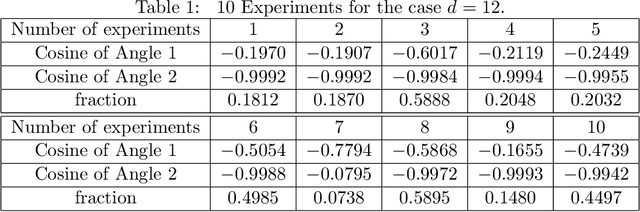
In this paper, we study the adversarial robustness of deep neural networks for classification tasks. We look at the smallest magnitude of possible additive perturbations that can change the output of a classification algorithm. We provide a matrix-theoretic explanation of the adversarial fragility of deep neural network for classification. In particular, our theoretical results show that neural network's adversarial robustness can degrade as the input dimension $d$ increases. Analytically we show that neural networks' adversarial robustness can be only $1/\sqrt{d}$ of the best possible adversarial robustness. Our matrix-theoretic explanation is consistent with an earlier information-theoretic feature-compression-based explanation for the adversarial fragility of neural networks.
Slaves to the Law of Large Numbers: An Asymptotic Equipartition Property for Perplexity in Generative Language Models
May 22, 2024We propose a new asymptotic equipartition property for the perplexity of a large piece of text generated by a language model and present theoretical arguments for this property. Perplexity, defined as a inverse likelihood function, is widely used as a performance metric for training language models. Our main result states that the logarithmic perplexity of any large text produced by a language model must asymptotically converge to the average entropy of its token distributions. This means that language models are constrained to only produce outputs from a ``typical set", which we show, is a vanishingly small subset of all possible grammatically correct outputs. We present preliminary experimental results from an open-source language model to support our theoretical claims. This work has possible practical applications for understanding and improving ``AI detection" tools and theoretical implications for the uniqueness, predictability and creative potential of generative models.
Linear Progressive Coding for Semantic Communication using Deep Neural Networks
Sep 27, 2023

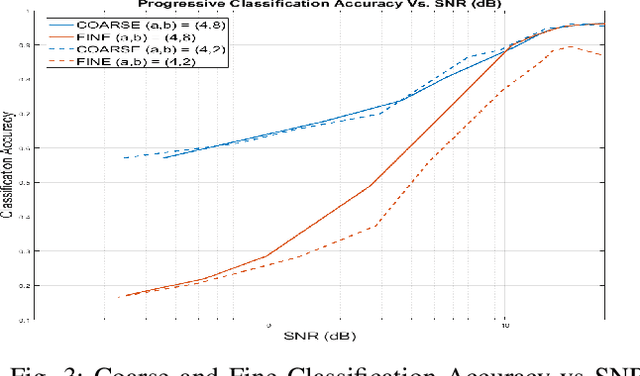

We propose a general method for semantic representation of images and other data using progressive coding. Semantic coding allows for specific pieces of information to be selectively encoded into a set of measurements that can be highly compressed compared to the size of the original raw data. We consider a hierarchical method of coding where a partial amount of semantic information is first encoded a into a coarse representation of the data, which is then refined by additional encodings that add additional semantic information. Such hierarchical coding is especially well-suited for semantic communication i.e. transferring semantic information over noisy channels. Our proposed method can be considered as a generalization of both progressive image compression and source coding for semantic communication. We present results from experiments on the MNIST and CIFAR-10 datasets that show that progressive semantic coding can provide timely previews of semantic information with a small number of initial measurements while achieving overall accuracy and efficiency comparable to non-progressive methods.
Derivation of Information-Theoretically Optimal Adversarial Attacks with Applications to Robust Machine Learning
Jul 28, 2020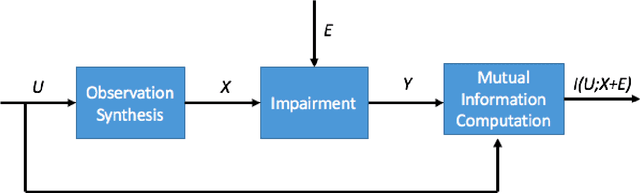
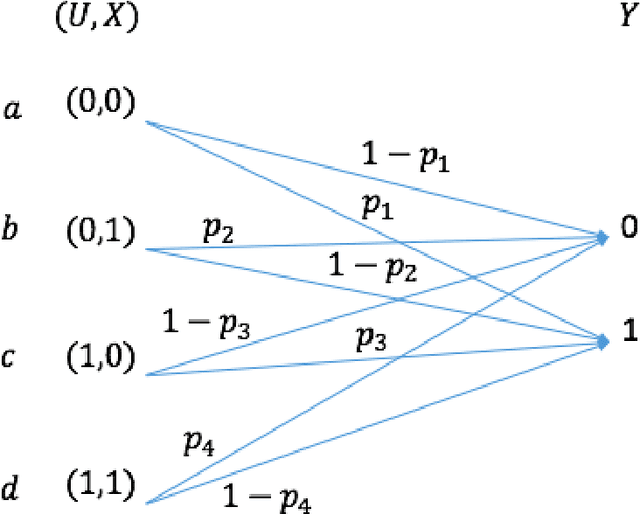
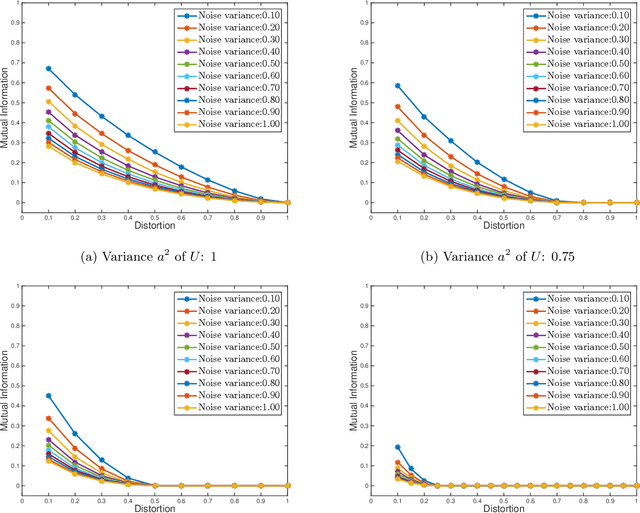
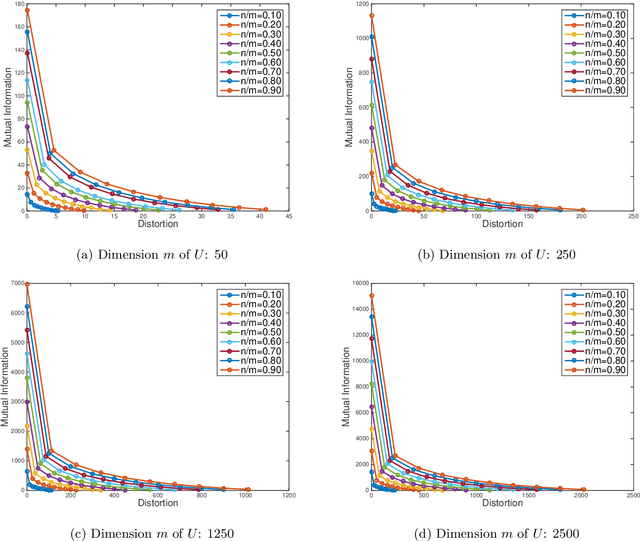
We consider the theoretical problem of designing an optimal adversarial attack on a decision system that maximally degrades the achievable performance of the system as measured by the mutual information between the degraded signal and the label of interest. This problem is motivated by the existence of adversarial examples for machine learning classifiers. By adopting an information theoretic perspective, we seek to identify conditions under which adversarial vulnerability is unavoidable i.e. even optimally designed classifiers will be vulnerable to small adversarial perturbations. We present derivations of the optimal adversarial attacks for discrete and continuous signals of interest, i.e., finding the optimal perturbation distributions to minimize the mutual information between the degraded signal and a signal following a continuous or discrete distribution. In addition, we show that it is much harder to achieve adversarial attacks for minimizing mutual information when multiple redundant copies of the input signal are available. This provides additional support to the recently proposed ``feature compression" hypothesis as an explanation for the adversarial vulnerability of deep learning classifiers. We also report on results from computational experiments to illustrate our theoretical results.
Do Deep Minds Think Alike? Selective Adversarial Attacks for Fine-Grained Manipulation of Multiple Deep Neural Networks
Mar 26, 2020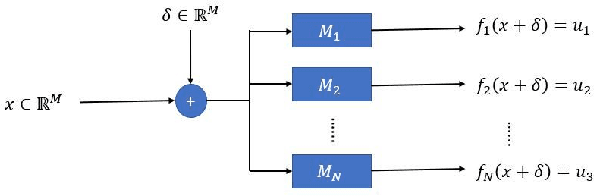

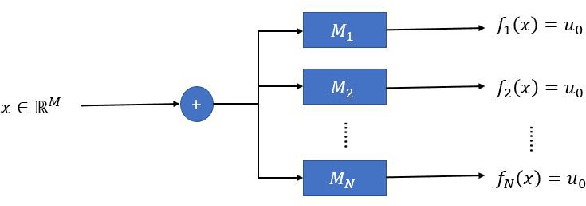
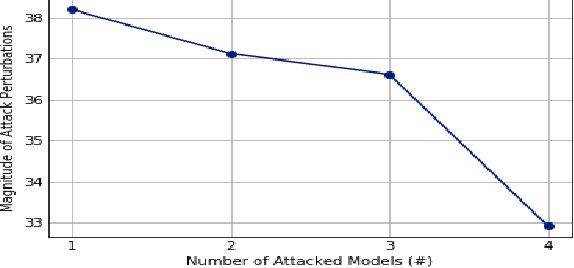
Recent works have demonstrated the existence of {\it adversarial examples} targeting a single machine learning system. In this paper we ask a simple but fundamental question of "selective fooling": given {\it multiple} machine learning systems assigned to solve the same classification problem and taking the same input signal, is it possible to construct a perturbation to the input signal that manipulates the outputs of these {\it multiple} machine learning systems {\it simultaneously} in arbitrary pre-defined ways? For example, is it possible to selectively fool a set of "enemy" machine learning systems but does not fool the other "friend" machine learning systems? The answer to this question depends on the extent to which these different machine learning systems "think alike". We formulate the problem of "selective fooling" as a novel optimization problem, and report on a series of experiments on the MNIST dataset. Our preliminary findings from these experiments show that it is in fact very easy to selectively manipulate multiple MNIST classifiers simultaneously, even when the classifiers are identical in their architectures, training algorithms and training datasets except for random initialization during training. This suggests that two nominally equivalent machine learning systems do not in fact "think alike" at all, and opens the possibility for many novel applications and deeper understandings of the working principles of deep neural networks.
An Information-Theoretic Explanation for the Adversarial Fragility of AI Classifiers
Jan 27, 2019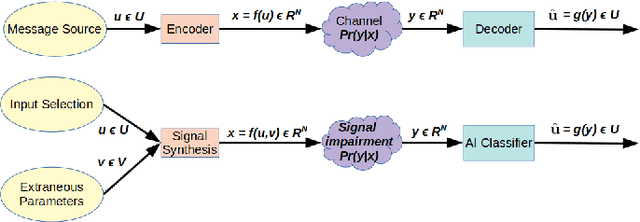
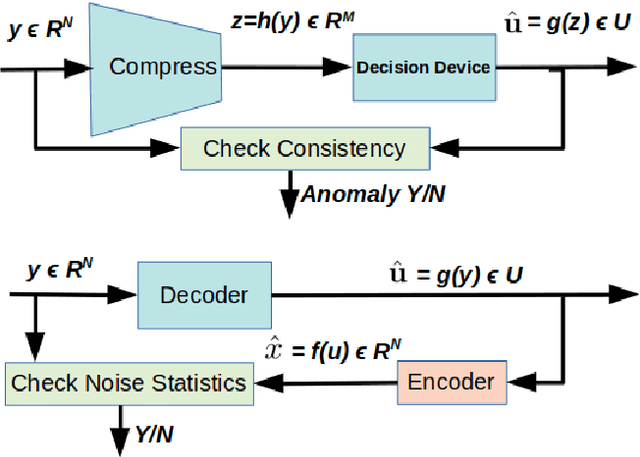
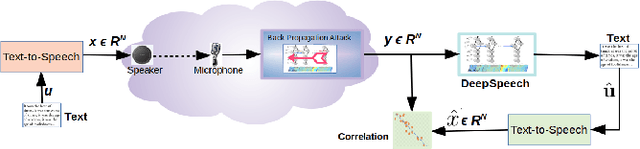
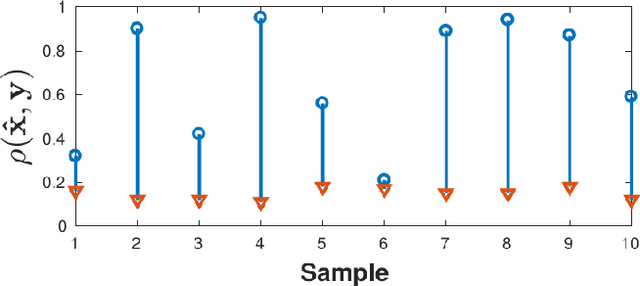
We present a simple hypothesis about a compression property of artificial intelligence (AI) classifiers and present theoretical arguments to show that this hypothesis successfully accounts for the observed fragility of AI classifiers to small adversarial perturbations. We also propose a new method for detecting when small input perturbations cause classifier errors, and show theoretical guarantees for the performance of this detection method. We present experimental results with a voice recognition system to demonstrate this method. The ideas in this paper are motivated by a simple analogy between AI classifiers and the standard Shannon model of a communication system.