 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd to end hyperspectral imaging system with coded compression imaging process
Sep 06, 2021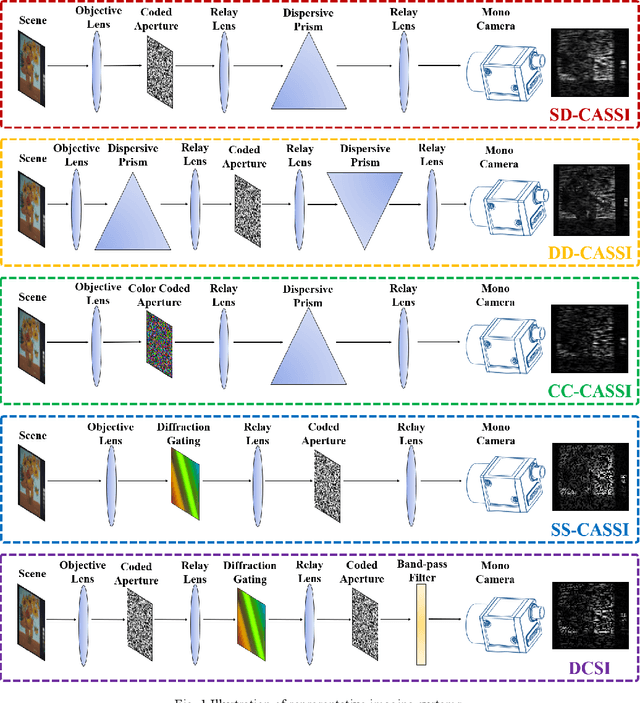

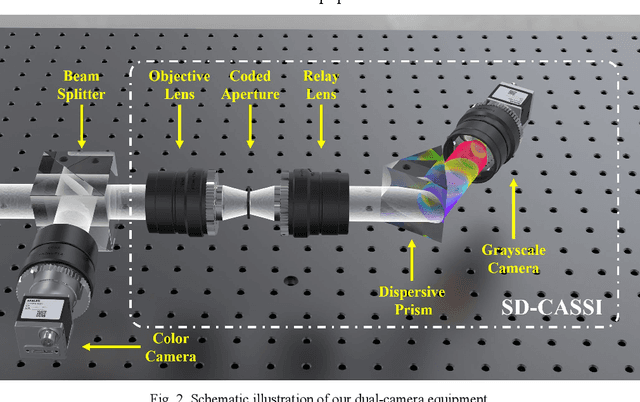

Hyperspectral images (HSIs) can provide rich spatial and spectral information with extensive application prospects. Recently, several methods using convolutional neural networks (CNNs) to reconstruct HSIs have been developed. However, most deep learning methods fit a brute-force mapping relationship between the compressive and standard HSIs. Thus, the learned mapping would be invalid when the observation data deviate from the training data. To recover the three-dimensional HSIs from two-dimensional compressive images, we present dual-camera equipment with a physics-informed self-supervising CNN method based on a coded aperture snapshot spectral imaging system. Our method effectively exploits the spatial-spectral relativization from the coded spectral information and forms a self-supervising system based on the camera quantum effect model. The experimental results show that our method can be adapted to a wide imaging environment with good performance. In addition, compared with most of the network-based methods, our system does not require a dedicated dataset for pre-training. Therefore, it has greater scenario adaptability and better generalization ability. Meanwhile, our system can be constantly fine-tuned and self-improved in real-life scenarios.
Learning-based real-time method to looking through scattering medium beyond the memory effect
Nov 04, 2019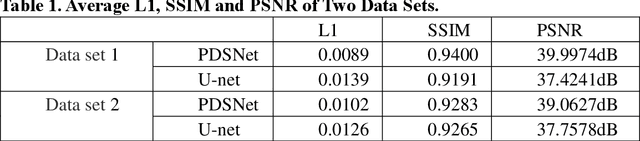


Strong scattering medium brings great difficulties to optical imaging, which is also a problem in medical imaging and many other fields. Optical memory effect makes it possible to image through strong random scattering medium. However, this method also has the limitation of limited angle field-of-view (FOV), which prevents it from being applied in practice. In this paper, a kind of practical convolutional neural network called PDSNet is proposed, which effectively breaks through the limitation of optical memory effect on FOV. Experiments is conducted to prove that the scattered pattern can be reconstructed accurately in real-time by PDSNet, and it is widely applicable to retrieve complex objects of random scales and different scattering media.
High Sensitivity Snapshot Spectrometer Based on Deep Network Unmixing
Jun 29, 2019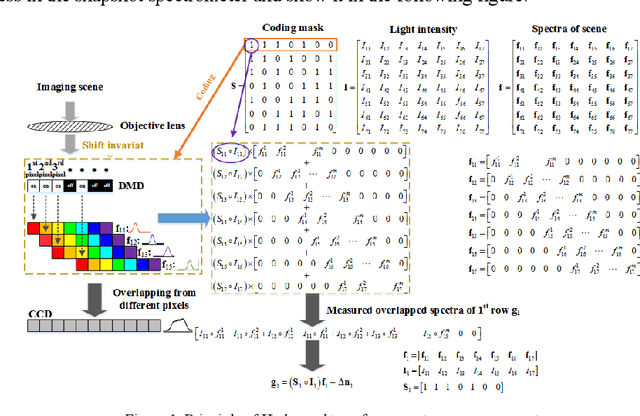
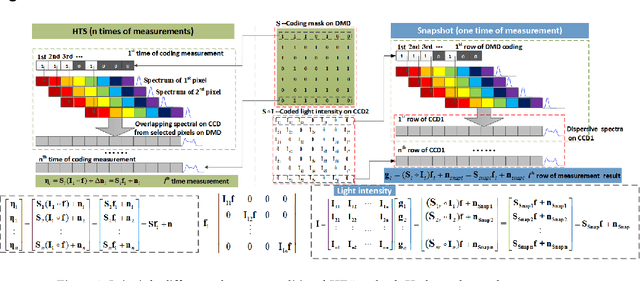
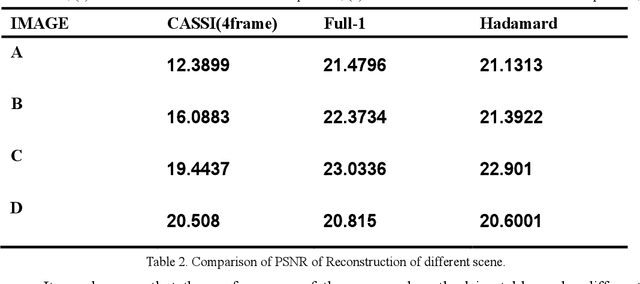
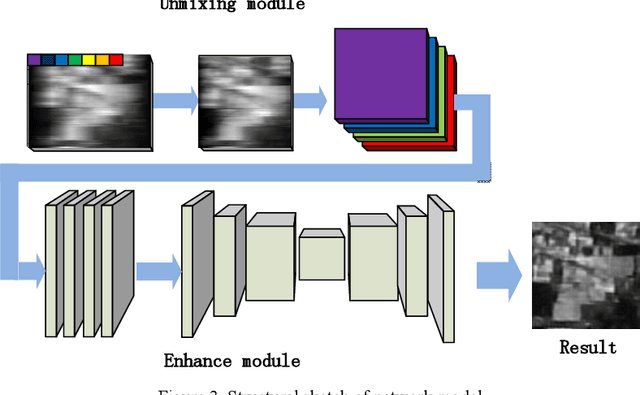
In this paper, we present a convolution neural network based method to recover the light intensity distribution from the overlapped dispersive spectra instead of adding an extra light path to capture it directly for the first time. Then, we construct a single-path sub-Hadamard snapshot spectrometer based on our previous dual-path snapshot spectrometer. In the proposed single-path spectrometer, we use the reconstructed light intensity as the original light intensity and recover high signal-to-noise ratio spectra successfully. Compared with dual-path snapshot spectrometer, the network based single-path spectrometer has a more compact structure and maintains snapshot and high sensitivity. Abundant simulated and experimental results have demonstrated that the proposed method can obtain a better reconstructed signal-to-noise ratio spectrum than the dual-path sub-Hadamard spectrometer because of its higher light throughput.
Residual Pyramid Learning for Single-Shot Semantic Segmentation
Mar 23, 2019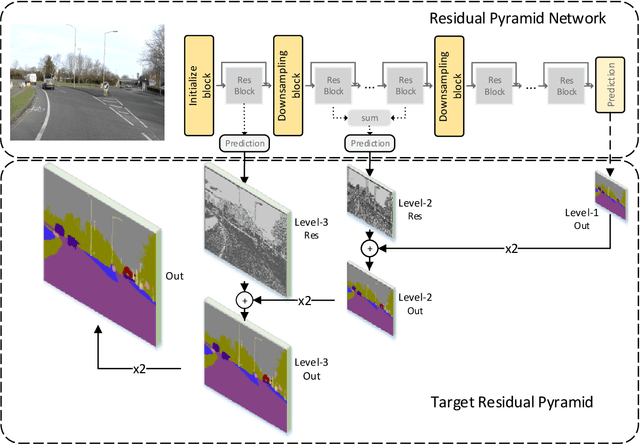
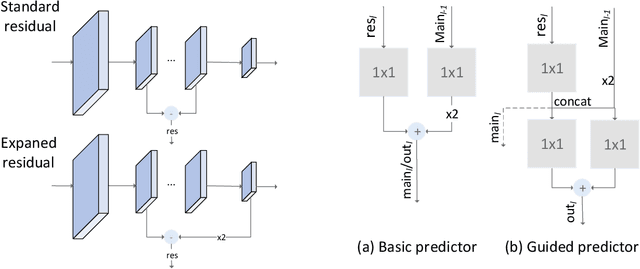
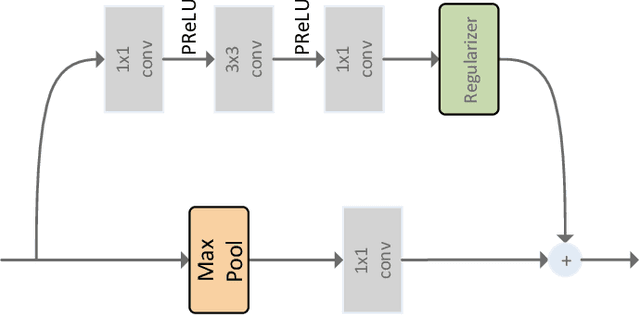
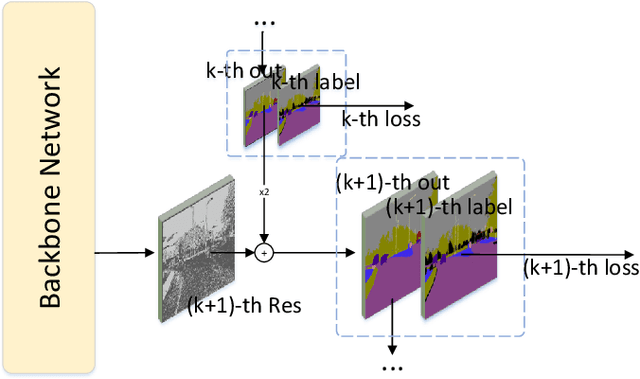
Pixel-level semantic segmentation is a challenging task with a huge amount of computation, especially if the size of input is large. In the segmentation model, apart from the feature extraction, the extra decoder structure is often employed to recover spatial information. In this paper, we put forward a method for single-shot segmentation in a feature residual pyramid network (RPNet), which learns the main and residuals of segmentation by decomposing the label at different levels of residual blocks. Specifically speaking, we use the residual features to learn the edges and details, and the identity features to learn the main part of targets. At testing time, the predicted residuals are used to enhance the details of the top-level prediction. Residual learning blocks split the network into several shallow sub-networks which facilitates the training of the RPNet. We then evaluate the proposed method and compare it with recent state-of-the-art methods on CamVid and Cityscapes. The proposed single-shot segmentation based on RPNet achieves impressive results with high efficiency on pixel-level segmentation.