 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Pyramid Learning for Single-Shot Semantic Segmentation
Mar 23, 2019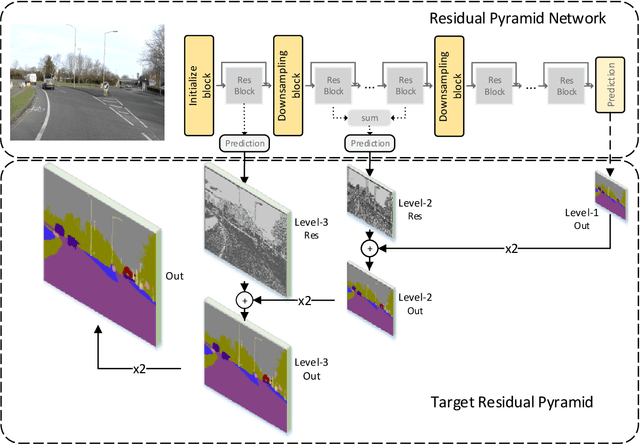
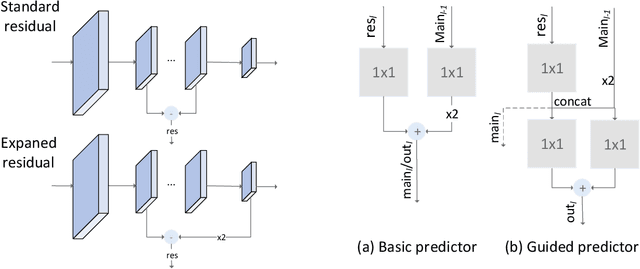
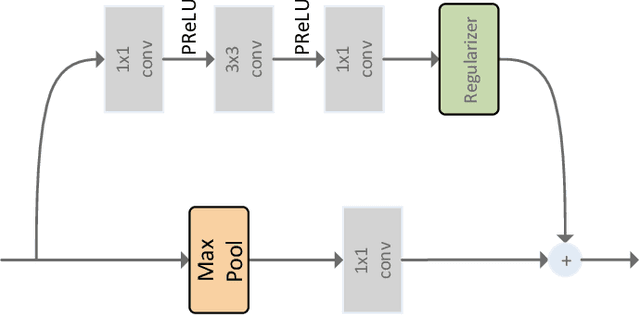
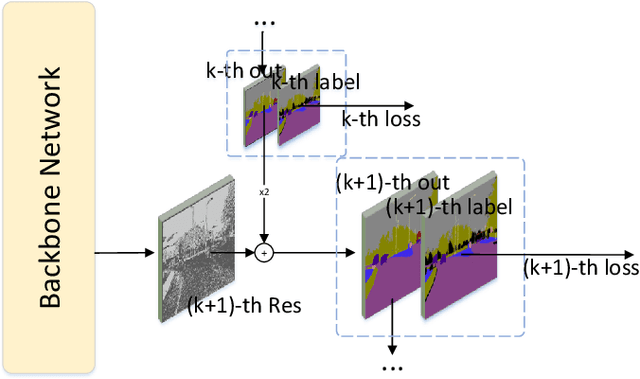
Pixel-level semantic segmentation is a challenging task with a huge amount of computation, especially if the size of input is large. In the segmentation model, apart from the feature extraction, the extra decoder structure is often employed to recover spatial information. In this paper, we put forward a method for single-shot segmentation in a feature residual pyramid network (RPNet), which learns the main and residuals of segmentation by decomposing the label at different levels of residual blocks. Specifically speaking, we use the residual features to learn the edges and details, and the identity features to learn the main part of targets. At testing time, the predicted residuals are used to enhance the details of the top-level prediction. Residual learning blocks split the network into several shallow sub-networks which facilitates the training of the RPNet. We then evaluate the proposed method and compare it with recent state-of-the-art methods on CamVid and Cityscapes. The proposed single-shot segmentation based on RPNet achieves impressive results with high efficiency on pixel-level segmentation.