 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEM: Enhancing Spatial Understanding for Robust Robot Manipulation
May 22, 2025A key challenge in robot manipulation lies in developing policy models with strong spatial understanding, the ability to reason about 3D geometry, object relations, and robot embodiment. Existing methods often fall short: 3D point cloud models lack semantic abstraction, while 2D image encoders struggle with spatial reasoning. To address this, we propose SEM (Spatial Enhanced Manipulation model), a novel diffusion-based policy framework that explicitly enhances spatial understanding from two complementary perspectives. A spatial enhancer augments visual representations with 3D geometric context, while a robot state encoder captures embodiment-aware structure through graphbased modeling of joint dependencies. By integrating these modules, SEM significantly improves spatial understanding, leading to robust and generalizable manipulation across diverse tasks that outperform existing baselines.
Sphere Face Model:A 3D Morphable Model with Hypersphere Manifold Latent Space
Dec 04, 2021
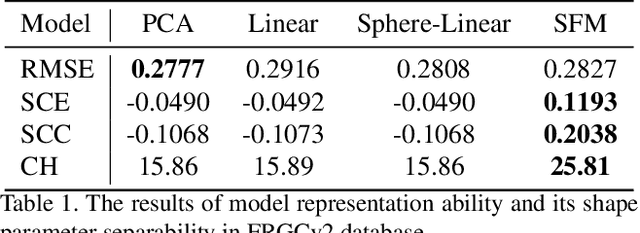


3D Morphable Models (3DMMs) are generative models for face shape and appearance. However, the shape parameters of traditional 3DMMs satisfy the multivariate Gaussian distribution while the identity embeddings satisfy the hypersphere distribution, and this conflict makes it challenging for face reconstruction models to preserve the faithfulness and the shape consistency simultaneously. To address this issue, we propose the Sphere Face Model(SFM), a novel 3DMM for monocular face reconstruction, which can preserve both shape fidelity and identity consistency. The core of our SFM is the basis matrix which can be used to reconstruct 3D face shapes, and the basic matrix is learned by adopting a two-stage training approach where 3D and 2D training data are used in the first and second stages, respectively. To resolve the distribution mismatch, we design a novel loss to make the shape parameters have a hyperspherical latent space. Extensive experiments show that SFM has high representation ability and shape parameter space's clustering performance. Moreover, it produces fidelity face shapes, and the shapes are consistent in challenging conditions in monocular face reconstruction.
Reconstructing Recognizable 3D Face Shapes based on 3D Morphable Models
Apr 08, 2021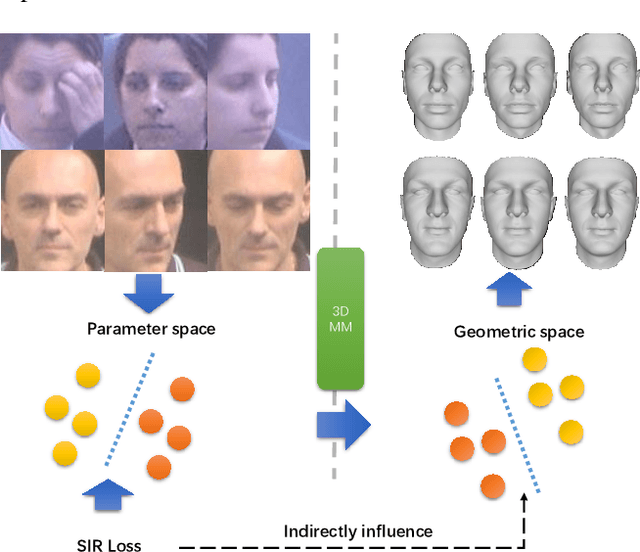


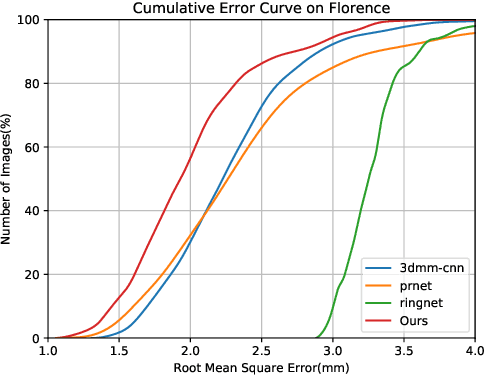
Many recent works have reconstructed distinctive 3D face shapes by aggregating shape parameters of the same identity and separating those of different people based on parametric models (e.g., 3D morphable models (3DMMs)). However, despite the high accuracy in the face recognition task using these shape parameters, the visual discrimination of face shapes reconstructed from those parameters is unsatisfactory. The following research question has not been answered in previous works: Do discriminative shape parameters guarantee visual discrimination in represented 3D face shapes? This paper analyzes the relationship between shape parameters and reconstructed shape geometry and proposes a novel shape identity-aware regularization(SIR) loss for shape parameters, aiming at increasing discriminability in both the shape parameter and shape geometry domains. Moreover, to cope with the lack of training data containing both landmark and identity annotations, we propose a network structure and an associated training strategy to leverage mixed data containing either identity or landmark labels. We compare our method with existing methods in terms of the reconstruction error, visual distinguishability, and face recognition accuracy of the shape parameters. Experimental results show that our method outperforms the state-of-the-art methods.