 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebAnchor: Anchoring Agent Planning to Stabilize Long-Horizon Web Reasoning
Jan 07, 2026Large Language Model(LLM)-based agents have shown strong capabilities in web information seeking, with reinforcement learning (RL) becoming a key optimization paradigm. However, planning remains a bottleneck, as existing methods struggle with long-horizon strategies. Our analysis reveals a critical phenomenon, plan anchor, where the first reasoning step disproportionately impacts downstream behavior in long-horizon web reasoning tasks. Current RL algorithms, fail to account for this by uniformly distributing rewards across the trajectory. To address this, we propose Anchor-GRPO, a two-stage RL framework that decouples planning and execution. In Stage 1, the agent optimizes its first-step planning using fine-grained rubrics derived from self-play experiences and human calibration. In Stage 2, execution is aligned with the initial plan through sparse rewards, ensuring stable and efficient tool usage. We evaluate Anchor-GRPO on four benchmarks: BrowseComp, BrowseComp-Zh, GAIA, and XBench-DeepSearch. Across models from 3B to 30B, Anchor-GRPO outperforms baseline GRPO and First-step GRPO, improving task success and tool efficiency. Notably, WebAnchor-30B achieves 46.0% pass@1 on BrowseComp and 76.4% on GAIA. Anchor-GRPO also demonstrates strong scalability, getting higher accuracy as model size and context length increase.
IOCC: Aligning Semantic and Cluster Centers for Few-shot Short Text Clustering
Aug 08, 2025In clustering tasks, it is essential to structure the feature space into clear, well-separated distributions. However, because short text representations have limited expressiveness, conventional methods struggle to identify cluster centers that truly capture each category's underlying semantics, causing the representations to be optimized in suboptimal directions. To address this issue, we propose IOCC, a novel few-shot contrastive learning method that achieves alignment between the cluster centers and the semantic centers. IOCC consists of two key modules: Interaction-enhanced Optimal Transport (IEOT) and Center-aware Contrastive Learning (CACL). Specifically, IEOT incorporates semantic interactions between individual samples into the conventional optimal transport problem, and generate pseudo-labels. Based on these pseudo-labels, we aggregate high-confidence samples to construct pseudo-centers that approximate the semantic centers. Next, CACL optimizes text representations toward their corresponding pseudo-centers. As training progresses, the collaboration between the two modules gradually reduces the gap between cluster centers and semantic centers. Therefore, the model will learn a high-quality distribution, improving clustering performance. Extensive experiments on eight benchmark datasets show that IOCC outperforms previous methods, achieving up to 7.34\% improvement on challenging Biomedical dataset and also excelling in clustering stability and efficiency. The code is available at: https://anonymous.4open.science/r/IOCC-C438.
Cross-Lingual Text-Rich Visual Comprehension: An Information Theory Perspective
Dec 23, 2024



Recent Large Vision-Language Models (LVLMs) have shown promising reasoning capabilities on text-rich images from charts, tables, and documents. However, the abundant text within such images may increase the model's sensitivity to language. This raises the need to evaluate LVLM performance on cross-lingual text-rich visual inputs, where the language in the image differs from the language of the instructions. To address this, we introduce XT-VQA (Cross-Lingual Text-Rich Visual Question Answering), a benchmark designed to assess how LVLMs handle language inconsistency between image text and questions. XT-VQA integrates five existing text-rich VQA datasets and a newly collected dataset, XPaperQA, covering diverse scenarios that require faithful recognition and comprehension of visual information despite language inconsistency. Our evaluation of prominent LVLMs on XT-VQA reveals a significant drop in performance for cross-lingual scenarios, even for models with multilingual capabilities. A mutual information analysis suggests that this performance gap stems from cross-lingual questions failing to adequately activate relevant visual information. To mitigate this issue, we propose MVCL-MI (Maximization of Vision-Language Cross-Lingual Mutual Information), where a visual-text cross-lingual alignment is built by maximizing mutual information between the model's outputs and visual information. This is achieved by distilling knowledge from monolingual to cross-lingual settings through KL divergence minimization, where monolingual output logits serve as a teacher. Experimental results on the XT-VQA demonstrate that MVCL-MI effectively reduces the visual-text cross-lingual performance disparity while preserving the inherent capabilities of LVLMs, shedding new light on the potential practice for improving LVLMs. Codes are available at: https://github.com/Stardust-y/XTVQA.git
Tree-Planner: Efficient Close-loop Task Planning with Large Language Models
Oct 12, 2023This paper studies close-loop task planning, which refers to the process of generating a sequence of skills (a plan) to accomplish a specific goal while adapting the plan based on real-time observations. Recently, prompting Large Language Models (LLMs) to generate actions iteratively has become a prevalent paradigm due to its superior performance and user-friendliness. However, this paradigm is plagued by two inefficiencies: high token consumption and redundant error correction, both of which hinder its scalability for large-scale testing and applications. To address these issues, we propose Tree-Planner, which reframes task planning with LLMs into three distinct phases: plan sampling, action tree construction, and grounded deciding. Tree-Planner starts by using an LLM to sample a set of potential plans before execution, followed by the aggregation of them to form an action tree. Finally, the LLM performs a top-down decision-making process on the tree, taking into account real-time environmental information. Experiments show that Tree-Planner achieves state-of-the-art performance while maintaining high efficiency. By decomposing LLM queries into a single plan-sampling call and multiple grounded-deciding calls, a considerable part of the prompt are less likely to be repeatedly consumed. As a result, token consumption is reduced by 92.2% compared to the previously best-performing model. Additionally, by enabling backtracking on the action tree as needed, the correction process becomes more flexible, leading to a 40.5% decrease in error corrections. Project page: https://tree-planner.github.io/
Improved Visual Story Generation with Adaptive Context Modeling
May 26, 2023
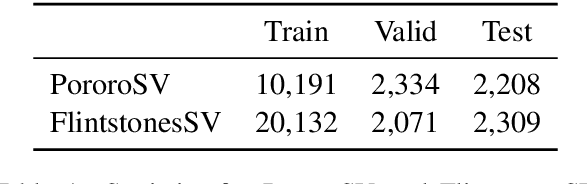
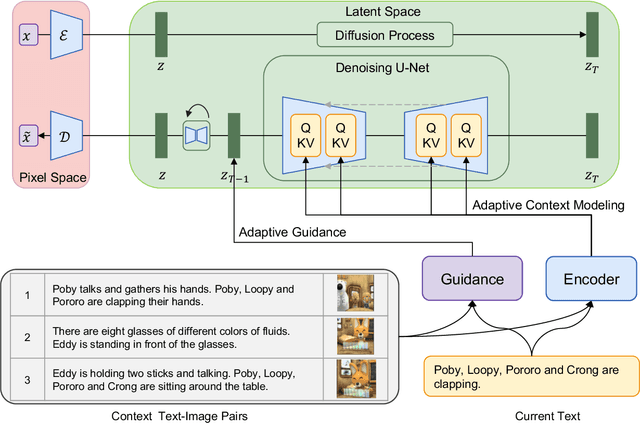
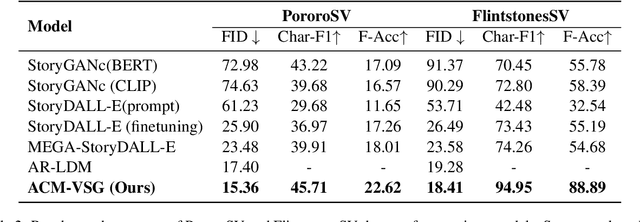
Diffusion models developed on top of powerful text-to-image generation models like Stable Diffusion achieve remarkable success in visual story generation. However, the best-performing approach considers historically generated results as flattened memory cells, ignoring the fact that not all preceding images contribute equally to the generation of the characters and scenes at the current stage. To address this, we present a simple method that improves the leading system with adaptive context modeling, which is not only incorporated in the encoder but also adopted as additional guidance in the sampling stage to boost the global consistency of the generated story. We evaluate our model on PororoSV and FlintstonesSV datasets and show that our approach achieves state-of-the-art FID scores on both story visualization and continuation scenarios. We conduct detailed model analysis and show that our model excels at generating semantically consistent images for stories.
Causal Coupled Mechanisms: A Control Method with Cooperation and Competition for Complex System
Sep 15, 2022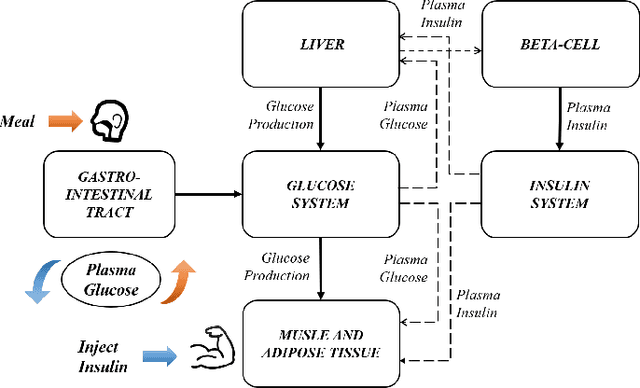

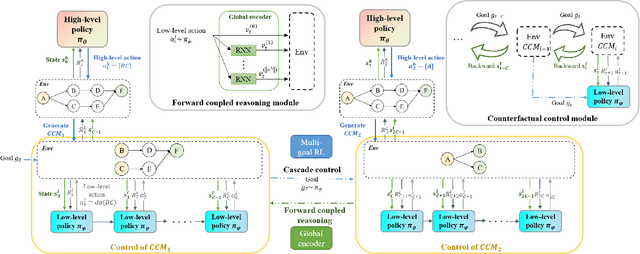
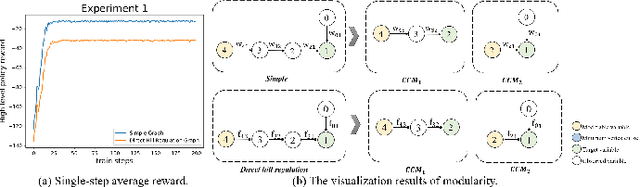
Complex systems are ubiquitous in the real world and tend to have complicated and poorly understood dynamics. For their control issues, the challenge is to guarantee accuracy, robustness, and generalization in such bloated and troubled environments. Fortunately, a complex system can be divided into multiple modular structures that human cognition appears to exploit. Inspired by this cognition, a novel control method, Causal Coupled Mechanisms (CCMs), is proposed that explores the cooperation in division and competition in combination. Our method employs the theory of hierarchical reinforcement learning (HRL), in which 1) the high-level policy with competitive awareness divides the whole complex system into multiple functional mechanisms, and 2) the low-level policy finishes the control task of each mechanism. Specifically for cooperation, a cascade control module helps the series operation of CCMs, and a forward coupled reasoning module is used to recover the coupling information lost in the division process. On both synthetic systems and a real-world biological regulatory system, the CCM method achieves robust and state-of-the-art control results even with unpredictable random noise. Moreover, generalization results show that reusing prepared specialized CCMs helps to perform well in environments with different confounders and dynamics.