 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAVIS-Ag: A Synthetic Plant Dataset for Developing Domain-Inspired Active Vision in Agricultural Robots
Mar 10, 2023



In agricultural environments, viewpoint planning can be a critical functionality for a robot with visual sensors to obtain informative observations of objects of interest (e.g., fruits) from complex structures of plant with random occlusions. Although recent studies on active vision have shown some potential for agricultural tasks, each model has been designed and validated on a unique environment that would not easily be replicated for benchmarking novel methods being developed later. In this paper, hence, we introduce a dataset for more extensive research on Domain-inspired Active VISion in Agriculture (DAVIS-Ag). To be specific, we utilized our open-source "AgML" framework and the 3D plant simulator of "Helios" to produce 502K RGB images from 30K dense spatial locations in 632 realistically synthesized orchards of strawberries, tomatoes, and grapes. In addition, useful labels are provided for each image, including (1) bounding boxes and (2) pixel-wise instance segmentations for all identifiable fruits, and also (3) pointers to other images that are reachable by an execution of action so as to simulate the active selection of viewpoint at each time step. Using DAVIS-Ag, we show the motivating examples in which performance of fruit detection for the same plant can significantly vary depending on the position and orientation of camera view primarily due to occlusions by other components such as leaves. Furthermore, we develop several baseline models to showcase the "usage" of data with one of agricultural active vision tasks--fruit search optimization--providing evaluation results against which future studies could benchmark their methodologies. For encouraging relevant research, our dataset is released online to be freely available at: https://github.com/ctyeong/DAVIS-Ag
Standardizing and Centralizing Datasets to Enable Efficient Training of Agricultural Deep Learning Models
Aug 04, 2022
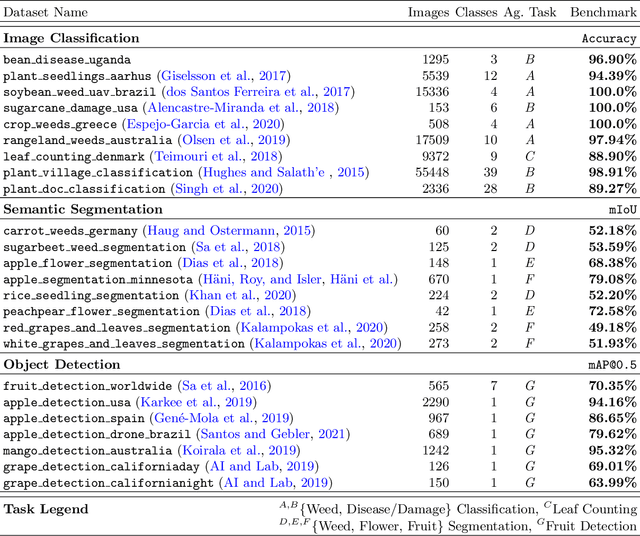
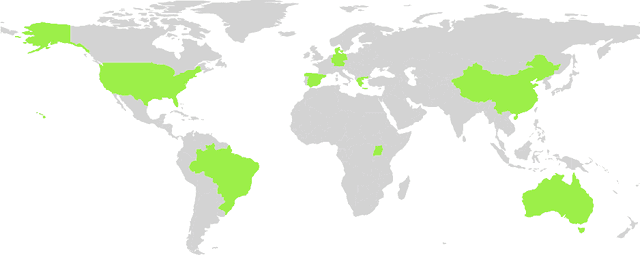

In recent years, deep learning models have become the standard for agricultural computer vision. Such models are typically fine-tuned to agricultural tasks using model weights that were originally fit to more general, non-agricultural datasets. This lack of agriculture-specific fine-tuning potentially increases training time and resource use, and decreases model performance, leading an overall decrease in data efficiency. To overcome this limitation, we collect a wide range of existing public datasets for three distinct tasks, standardize them, and construct standard training and evaluation pipelines, providing us with a set of benchmarks and pretrained models. We then conduct a number of experiments using methods which are commonly used in deep learning tasks, but unexplored in their domain-specific applications for agriculture. Our experiments guide us in developing a number of approaches to improve data efficiency when training agricultural deep learning models, without large-scale modifications to existing pipelines. Our results demonstrate that even slight training modifications, such as using agricultural pretrained model weights, or adopting specific spatial augmentations into data processing pipelines, can significantly boost model performance and result in shorter convergence time, saving training resources. Furthermore, we find that even models trained on low-quality annotations can produce comparable levels of performance to their high-quality equivalents, suggesting that datasets with poor annotations can still be used for training, expanding the pool of currently available datasets. Our methods are broadly applicable throughout agricultural deep learning, and present high potential for significant data efficiency improvements.