 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-Centric Transformers: Concept Transformers with Object-Centric Concept Learning for Interpretability
Paper and Code
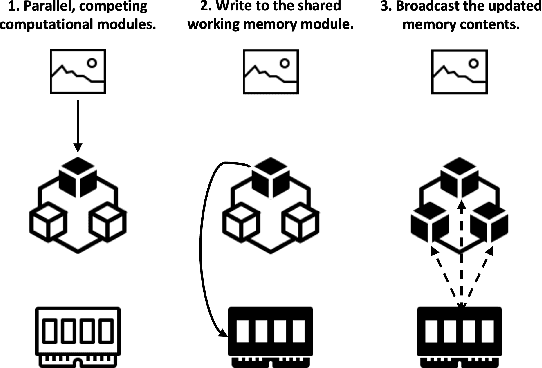
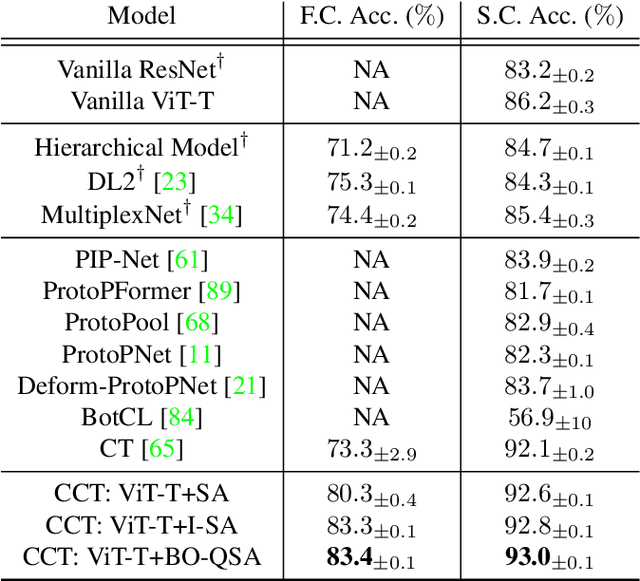
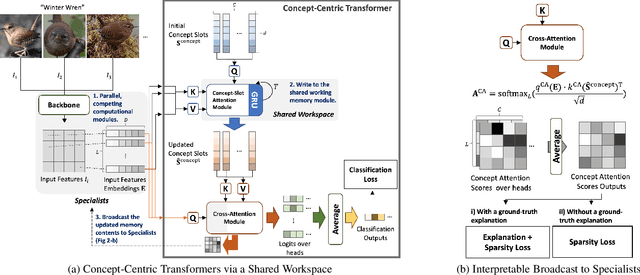

Attention mechanisms have greatly improved the performance of deep-learning models on visual, NLP, and multimodal tasks while also providing tools to aid in the model's interpretability. In particular, attention scores over input regions or concrete image features can be used to measure how much the attended elements contribute to the model inference. The recently proposed Concept Transformer (CT) generalizes the Transformer attention mechanism from such low-level input features to more abstract, intermediate-level latent concepts that better allow human analysts to more directly assess an explanation for the reasoning of the model about any particular output classification. However, the concept learning employed by CT implicitly assumes that across every image in a class, each image patch makes the same contribution to concepts that characterize membership in that class. Instead of using the CT's image-patch-centric concepts, object-centric concepts could lead to better classification performance as well as better explainability. Thus, we propose Concept-Centric Transformers (CCT), a new family of concept transformers that provides more robust explanations and performance by integrating a novel concept-extraction module based on object-centric learning. We test our proposed CCT against the CT and several other existing approaches on classification problems for MNIST (odd/even), CIFAR100 (super-classes), and CUB-200-2011 (bird species). Our experiments demonstrate that CCT not only achieves significantly better classification accuracy than all selected benchmark classifiers across all three of our test problems, but it generates more consistent concept-based explanations of classification output when compared to CT.