 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Neural Text-to-Speech
Paper and Code
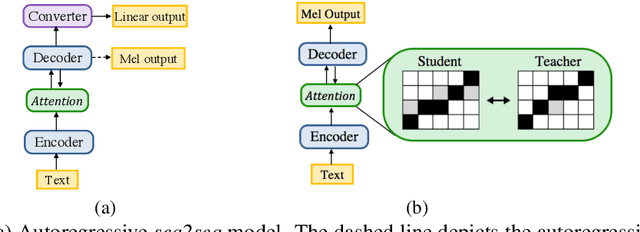
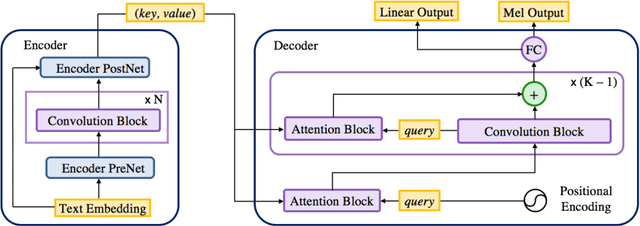

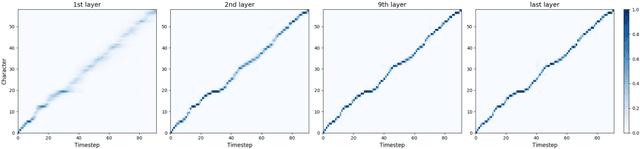
In this work, we propose a non-autoregressive seq2seq model that converts text to spectrogram. It is fully convolutional and obtains about 46.7 times speed-up over Deep Voice 3 at synthesis while maintaining comparable speech quality using a WaveNet vocoder. Interestingly, it has even fewer attention errors than the autoregressive model on the challenging test sentences. Furthermore, we build the first fully parallel neural text-to-speech system by applying the inverse autoregressive flow~(IAF) as the parallel neural vocoder. Our system can synthesize speech from text through a single feed-forward pass. We also explore a novel approach to train the IAF from scratch as a generative model for raw waveform, which avoids the need for distillation from a separately trained WaveNet.