 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaveFlow: A Compact Flow-based Model for Raw Audio
Paper and Code
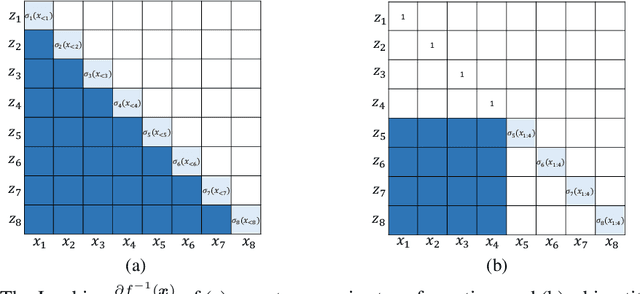



In this work, we propose WaveFlow, a small-footprint generative flow for raw audio, which is directly trained with maximum likelihood. WaveFlow handles the long-range structure of waveform with a dilated 2-D convolutional architecture, while modeling the local variations using compact autoregressive functions. It provides a unified view of likelihood-based models for raw audio, including WaveNet and WaveGlow as special cases. WaveFlow can generate high-fidelity speech as WaveNet, while synthesizing several orders of magnitude faster as it only requires a few sequential steps to generate waveforms with hundreds of thousands of time-steps. Furthermore, it can close the significant likelihood gap that has existed between autoregressive models and flow-based models for efficient synthesis. Finally, our small-footprint WaveFlow has 15$\times$ fewer parameters than WaveGlow and can generate 22.05 kHz high-fidelity audio 42.6$\times$ faster than real-time on a V100 GPU without engineered inference kernels.