 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort-Path Prompting in LLMs: Analyzing Reasoning Instability and Solutions for Robust Performance
Apr 13, 2025Recent years have witnessed significant progress in large language models' (LLMs) reasoning, which is largely due to the chain-of-thought (CoT) approaches, allowing models to generate intermediate reasoning steps before reaching the final answer. Building on these advances, state-of-the-art LLMs are instruction-tuned to provide long and detailed CoT pathways when responding to reasoning-related questions. However, human beings are naturally cognitive misers and will prompt language models to give rather short responses, thus raising a significant conflict with CoT reasoning. In this paper, we delve into how LLMs' reasoning performance changes when users provide short-path prompts. The results and analysis reveal that language models can reason effectively and robustly without explicit CoT prompts, while under short-path prompting, LLMs' reasoning ability drops significantly and becomes unstable, even on grade-school problems. To address this issue, we propose two approaches: an instruction-guided approach and a fine-tuning approach, both designed to effectively manage the conflict. Experimental results show that both methods achieve high accuracy, providing insights into the trade-off between instruction adherence and reasoning accuracy in current models.
On the Opportunities of Green Computing: A Survey
Nov 09, 2023



Artificial Intelligence (AI) has achieved significant advancements in technology and research with the development over several decades, and is widely used in many areas including computing vision, natural language processing, time-series analysis, speech synthesis, etc. During the age of deep learning, especially with the arise of Large Language Models, a large majority of researchers' attention is paid on pursuing new state-of-the-art (SOTA) results, resulting in ever increasing of model size and computational complexity. The needs for high computing power brings higher carbon emission and undermines research fairness by preventing small or medium-sized research institutions and companies with limited funding in participating in research. To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic. In this survey, we give a systematic overview of the technologies used in Green Computing. We propose the framework of Green Computing and devide it into four key components: (1) Measures of Greenness, (2) Energy-Efficient AI, (3) Energy-Efficient Computing Systems and (4) AI Use Cases for Sustainability. For each components, we discuss the research progress made and the commonly used techniques to optimize the AI efficiency. We conclude that this new research direction has the potential to address the conflicts between resource constraints and AI development. We encourage more researchers to put attention on this direction and make AI more environmental friendly.
One Model for All: Large Language Models are Domain-Agnostic Recommendation Systems
Oct 22, 2023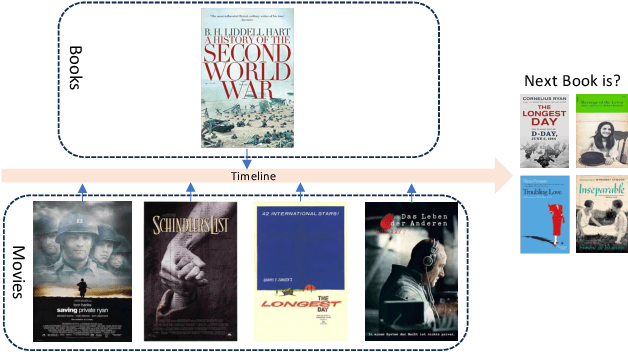

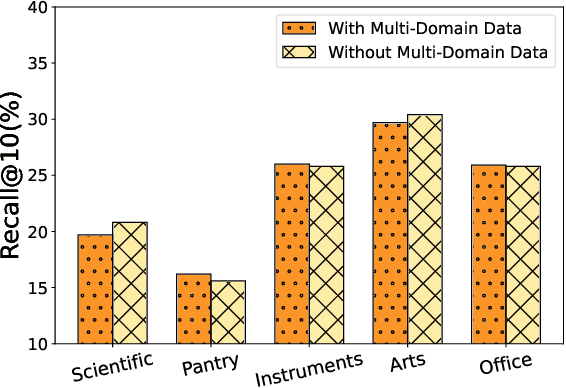

The purpose of sequential recommendation is to utilize the interaction history of a user and predict the next item that the user is most likely to interact with. While data sparsity and cold start are two challenges that most recommender systems are still facing, many efforts are devoted to utilizing data from other domains, called cross-domain methods. However, general cross-domain methods explore the relationship between two domains by designing complex model architecture, making it difficult to scale to multiple domains and utilize more data. Moreover, existing recommendation systems use IDs to represent item, which carry less transferable signals in cross-domain scenarios, and user cross-domain behaviors are also sparse, making it challenging to learn item relationship from different domains. These problems hinder the application of multi-domain methods to sequential recommendation. Recently, large language models (LLMs) exhibit outstanding performance in world knowledge learning from text corpora and general-purpose question answering. Inspired by these successes, we propose a simple but effective framework for domain-agnostic recommendation by exploiting the pre-trained LLMs (namely LLM-Rec). We mix the user's behavior across different domains, and then concatenate the title information of these items into a sentence and model the user's behaviors with a pre-trained language model. We expect that by mixing the user's behaviors across different domains, we can exploit the common knowledge encoded in the pre-trained language model to alleviate the problems of data sparsity and cold start problems. Furthermore, we are curious about whether the latest technical advances in nature language processing (NLP) can transfer to the recommendation scenarios.