 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Model for All: Large Language Models are Domain-Agnostic Recommendation Systems
Paper and Code
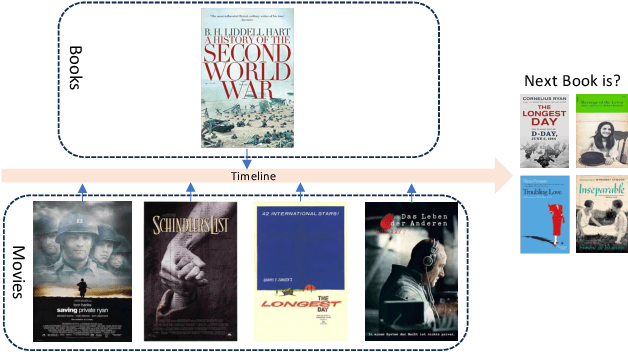

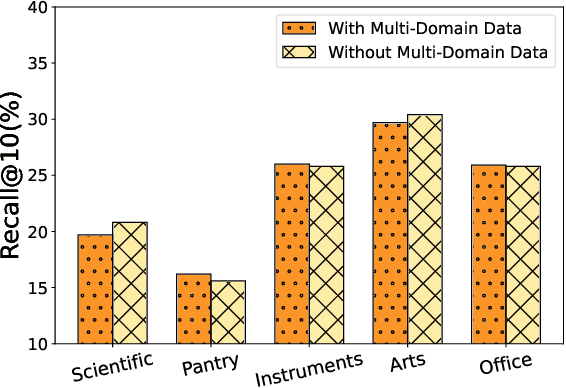

The purpose of sequential recommendation is to utilize the interaction history of a user and predict the next item that the user is most likely to interact with. While data sparsity and cold start are two challenges that most recommender systems are still facing, many efforts are devoted to utilizing data from other domains, called cross-domain methods. However, general cross-domain methods explore the relationship between two domains by designing complex model architecture, making it difficult to scale to multiple domains and utilize more data. Moreover, existing recommendation systems use IDs to represent item, which carry less transferable signals in cross-domain scenarios, and user cross-domain behaviors are also sparse, making it challenging to learn item relationship from different domains. These problems hinder the application of multi-domain methods to sequential recommendation. Recently, large language models (LLMs) exhibit outstanding performance in world knowledge learning from text corpora and general-purpose question answering. Inspired by these successes, we propose a simple but effective framework for domain-agnostic recommendation by exploiting the pre-trained LLMs (namely LLM-Rec). We mix the user's behavior across different domains, and then concatenate the title information of these items into a sentence and model the user's behaviors with a pre-trained language model. We expect that by mixing the user's behaviors across different domains, we can exploit the common knowledge encoded in the pre-trained language model to alleviate the problems of data sparsity and cold start problems. Furthermore, we are curious about whether the latest technical advances in nature language processing (NLP) can transfer to the recommendation scenarios.