 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Blockchain Framework using Image Hashing for Image Authentication
Apr 15, 2020
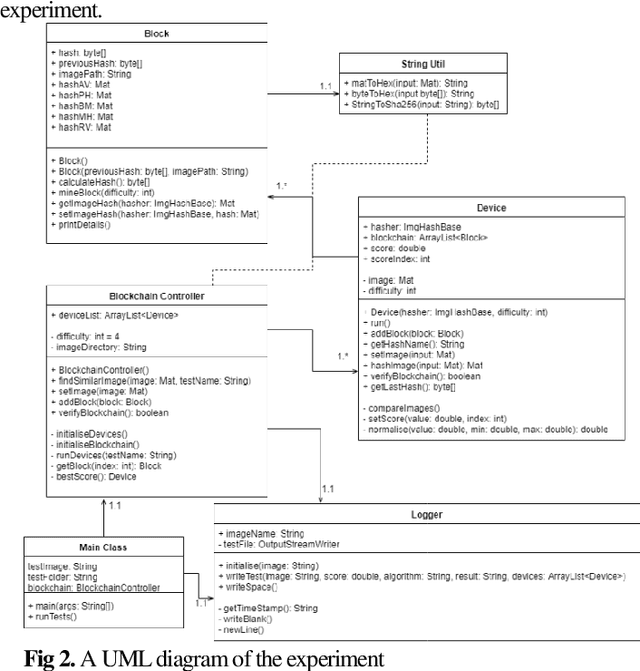
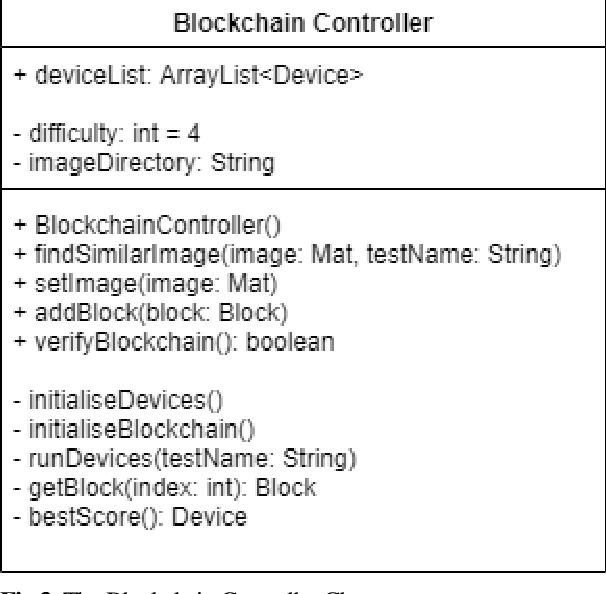
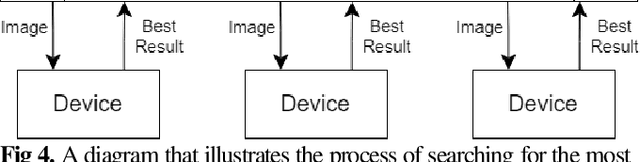
Blockchain is a relatively new technology that can be seen as a decentralised database. Blockchain systems heavily rely on cryptographic hash functions to store their data, which makes it difficult to tamper with any data stored in the system. A topic that was researched along with blockchain is image authentication. Image authentication focuses on investigating and maintaining the integrity of images. As a blockchain system can be useful for maintaining data integrity, image authentication has the potential to be enhanced by blockchain. There are many techniques that can be used to authenticate images; the technique investigated by this work is image hashing. Image hashing is a technique used to calculate how similar two different images are. This is done by converting the images into hashes and then comparing them using a distance formula. To investigate the topic, an experiment involving a simulated blockchain was created. The blockchain acted as a database for images. This blockchain was made up of devices which contained their own unique image hashing algorithms. The blockchain was tested by creating modified copies of the images contained in the database, and then submitting them to the blockchain to see if it will return the original image. Through this experiment it was discovered that it is plausible to create an image authentication system using blockchain and image hashing. However, the design proposed by this work requires refinement, as it appears to struggle in some situations. This work shows that blockchain can be a suitable approach for authenticating images, particularly via image hashing. Other observations include that using multiple image hash algorithms at the same time can increase performance in some cases, as well as that each type of test done to the blockchain has its own unique pattern to its data.
Optimizing Waiting Thresholds Within A State Machine
Oct 08, 2018
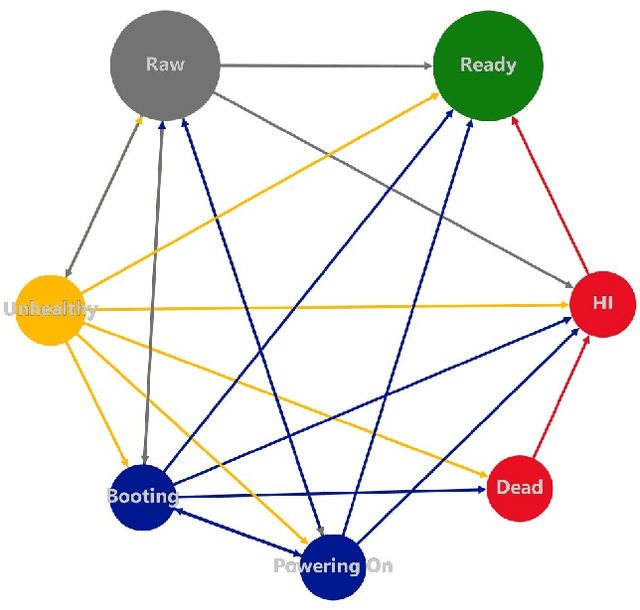
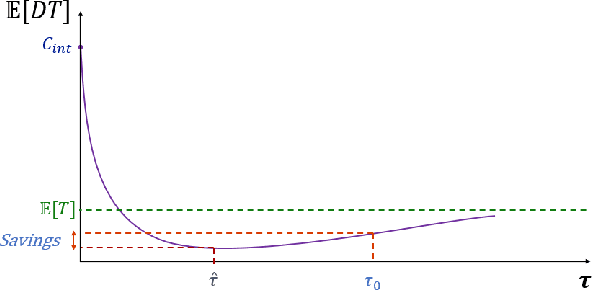

Azure (the cloud service provided by Microsoft) is composed of physical computing units which are called nodes. These nodes are controlled by a software component called Fabric Controller (FC), which can consider the nodes to be in one of many different states such as Ready, Unhealthy, Booting, etc. Some of these states correspond to a node being unresponsive to FCs requests. When a node goes unresponsive for more than a set threshold, FC intervenes and reboots the node. We minimized the downtime caused by the intervention threshold when a node switches to the Unhealthy state by fitting various heavy-tail probability distributions. We consider using features of the node to customize the organic recovery model to the individual nodes that go unhealthy. This regression approach allows us to use information about the node like hardware, software versions, historical performance indicators, etc. to inform the organic recovery model and hence the optimal threshold. In another direction, we consider generalizing this to an arbitrary number of thresholds within the node state machine (or Markov chain). When the states become intertwined in ways that different thresholds start affecting each other, we can't simply optimize each of them in isolation. For best results, we must consider this as an optimization problem in many variables (the number of thresholds). We no longer have a nice closed form solution for this more complex problem like we did with one threshold, but we can still use numerical techniques (gradient descent) to solve it.