 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Waiting Thresholds Within A State Machine
Paper and Code

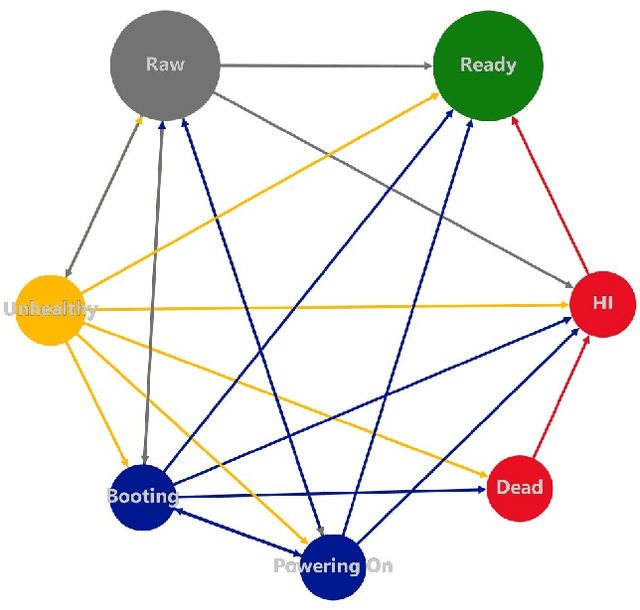
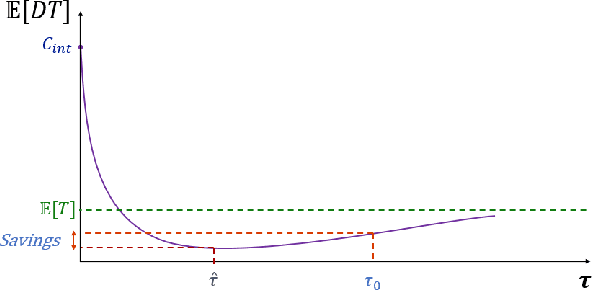

Azure (the cloud service provided by Microsoft) is composed of physical computing units which are called nodes. These nodes are controlled by a software component called Fabric Controller (FC), which can consider the nodes to be in one of many different states such as Ready, Unhealthy, Booting, etc. Some of these states correspond to a node being unresponsive to FCs requests. When a node goes unresponsive for more than a set threshold, FC intervenes and reboots the node. We minimized the downtime caused by the intervention threshold when a node switches to the Unhealthy state by fitting various heavy-tail probability distributions. We consider using features of the node to customize the organic recovery model to the individual nodes that go unhealthy. This regression approach allows us to use information about the node like hardware, software versions, historical performance indicators, etc. to inform the organic recovery model and hence the optimal threshold. In another direction, we consider generalizing this to an arbitrary number of thresholds within the node state machine (or Markov chain). When the states become intertwined in ways that different thresholds start affecting each other, we can't simply optimize each of them in isolation. For best results, we must consider this as an optimization problem in many variables (the number of thresholds). We no longer have a nice closed form solution for this more complex problem like we did with one threshold, but we can still use numerical techniques (gradient descent) to solve it.