 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-resolution Lung Nodule Segmentation from Chest X-ray Images using Residual Encoder-Decoder Networks
Jul 13, 2023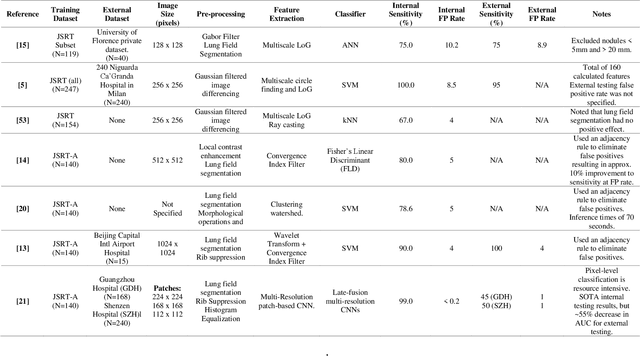
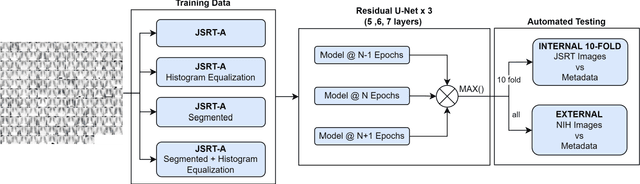
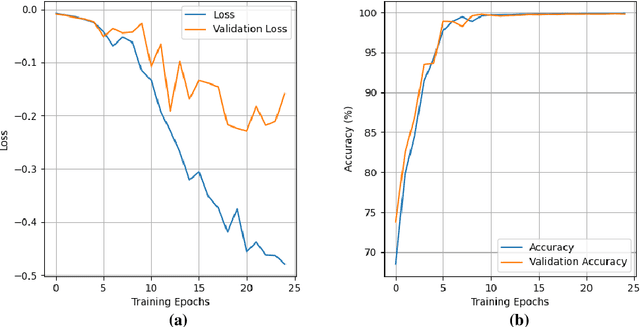

Lung cancer is the leading cause of cancer death and early diagnosis is associated with a positive prognosis. Chest X-ray (CXR) provides an inexpensive imaging mode for lung cancer diagnosis. Suspicious nodules are difficult to distinguish from vascular and bone structures using CXR. Computer vision has previously been proposed to assist human radiologists in this task, however, leading studies use down-sampled images and computationally expensive methods with unproven generalization. Instead, this study localizes lung nodules using efficient encoder-decoder neural networks that process full resolution images to avoid any signal loss resulting from down-sampling. Encoder-decoder networks are trained and tested using the JSRT lung nodule dataset. The networks are used to localize lung nodules from an independent external CXR dataset. Sensitivity and false positive rates are measured using an automated framework to eliminate any observer subjectivity. These experiments allow for the determination of the optimal network depth, image resolution and pre-processing pipeline for generalized lung nodule localization. We find that nodule localization is influenced by subtlety, with more subtle nodules being detected in earlier training epochs. Therefore, we propose a novel self-ensemble model from three consecutive epochs centered on the validation optimum. This ensemble achieved a sensitivity of 85% in 10-fold internal testing with false positives of 8 per image. A sensitivity of 81% is achieved at a false positive rate of 6 following morphological false positive reduction. This result is comparable to more computationally complex systems based on linear and spatial filtering, but with a sub-second inference time that is faster than other methods. The proposed algorithm achieved excellent generalization results against an external dataset with sensitivity of 77% at a false positive rate of 7.6.
2-speed network ensemble for efficient classification of incremental land-use/land-cover satellite image chips
Mar 15, 2022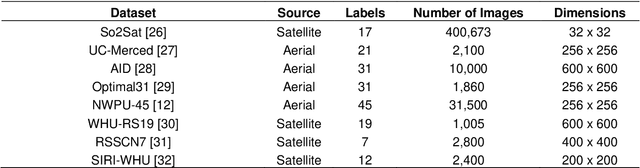
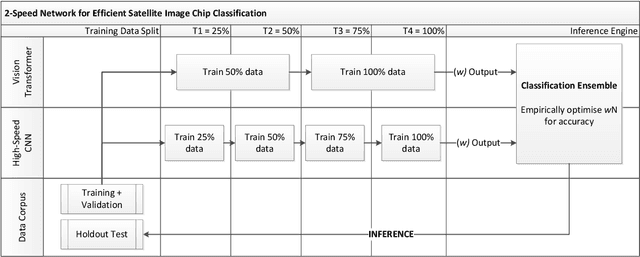


The ever-growing volume of satellite imagery data presents a challenge for industry and governments making data-driven decisions based on the timely analysis of very large data sets. Commonly used deep learning algorithms for automatic classification of satellite images are time and resource-intensive to train. The cost of retraining in the context of Big Data presents a practical challenge when new image data and/or classes are added to a training corpus. Recognizing the need for an adaptable, accurate, and scalable satellite image chip classification scheme, in this research we present an ensemble of: i) a slow to train but high accuracy vision transformer; and ii) a fast to train, low-parameter convolutional neural network. The vision transformer model provides a scalable and accurate foundation model. The high-speed CNN provides an efficient means of incorporating newly labelled data into analysis, at the expense of lower accuracy. To simulate incremental data, the very large (~400,000 images) So2Sat LCZ42 satellite image chip dataset is divided into four intervals, with the high-speed CNN retrained every interval and the vision transformer trained every half interval. This experimental setup mimics an increase in data volume and diversity over time. For the task of automated land-cover/land-use classification, the ensemble models for each data increment outperform each of the component models, with best accuracy of 65% against a holdout test partition of the So2Sat dataset. The proposed ensemble and staggered training schedule provide a scalable and cost-effective satellite image classification scheme that is optimized to process very large volumes of satellite data.