 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePotential Features of ICU Admission in X-ray Images of COVID-19 Patients
Paper and Code
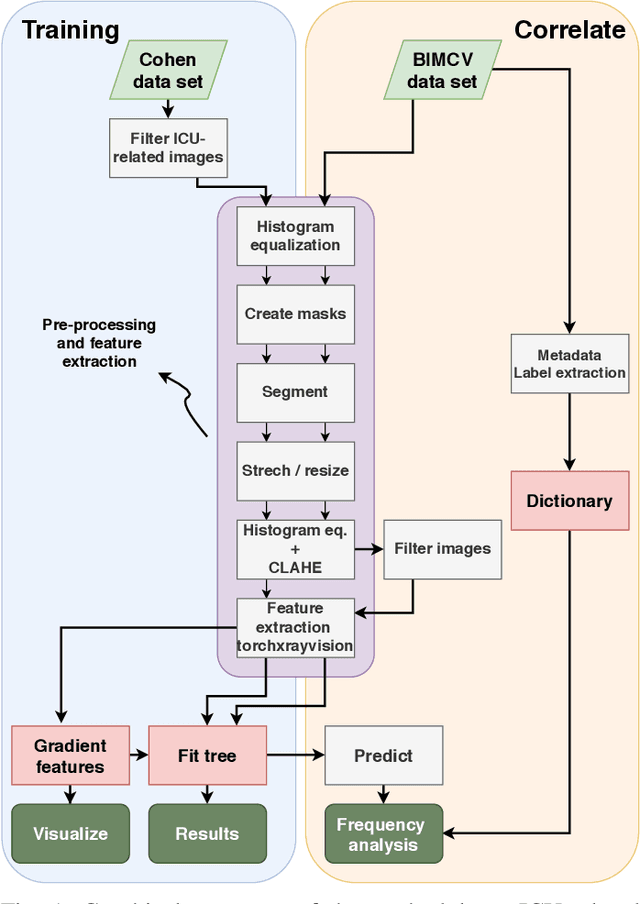
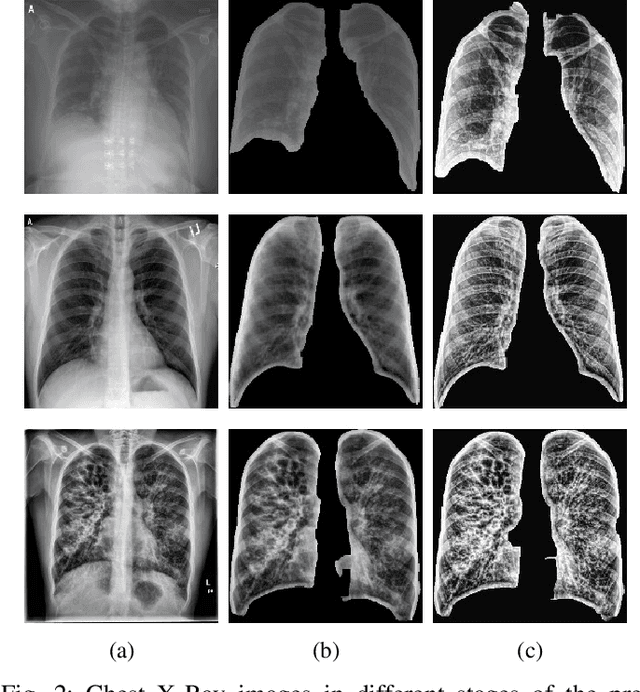
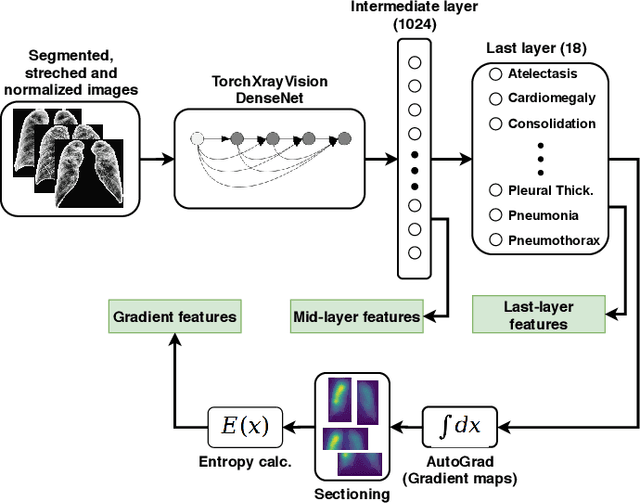

X-ray images may present non-trivial features with predictive information of patients that develop severe symptoms of COVID-19. If true, this hypothesis may have practical value in allocating resources to particular patients while using a relatively inexpensive imaging technique. The difficulty of testing such a hypothesis comes from the need for large sets of labelled data, which not only need to be well-annotated but also should contemplate the post-imaging severity outcome. On this account, this paper presents a methodology for extracting features from a limited data set with outcome label (patient required ICU admission or not) and correlating its significance to an additional, larger data set with hundreds of images. The methodology employs a neural network trained to recognise lung pathologies to extract the semantic features, which are then analysed with a shallow decision tree to limit overfitting while increasing interpretability. This analysis points out that only a few features explain most of the variance between patients that developed severe symptoms. When applied to an unrelated, larger data set with labels extracted from clinical notes, the method classified distinct sets of samples where there was a much higher frequency of labels such as `Consolidation', `Effusion', and `alveolar'. A further brief analysis on the locations of such labels also showed a significant increase in the frequency of words like `bilateral', `middle', and `lower' in patients classified as with higher chances of going severe. The methodology for dealing with the lack of specific ICU label data while attesting correlations with a data set containing text notes is novel; its results suggest that some pathologies should receive higher weights when assessing disease severity.