 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowR: Flowing from Sparse to Dense 3D Reconstructions
Apr 02, 2025



3D Gaussian splatting enables high-quality novel view synthesis (NVS) at real-time frame rates. However, its quality drops sharply as we depart from the training views. Thus, dense captures are needed to match the high-quality expectations of some applications, e.g. Virtual Reality (VR). However, such dense captures are very laborious and expensive to obtain. Existing works have explored using 2D generative models to alleviate this requirement by distillation or generating additional training views. These methods are often conditioned only on a handful of reference input views and thus do not fully exploit the available 3D information, leading to inconsistent generation results and reconstruction artifacts. To tackle this problem, we propose a multi-view, flow matching model that learns a flow to connect novel view renderings from possibly sparse reconstructions to renderings that we expect from dense reconstructions. This enables augmenting scene captures with novel, generated views to improve reconstruction quality. Our model is trained on a novel dataset of 3.6M image pairs and can process up to 45 views at 540x960 resolution (91K tokens) on one H100 GPU in a single forward pass. Our pipeline consistently improves NVS in sparse- and dense-view scenarios, leading to higher-quality reconstructions than prior works across multiple, widely-used NVS benchmarks.
AirObject: A Temporally Evolving Graph Embedding for Object Identification
Nov 30, 2021
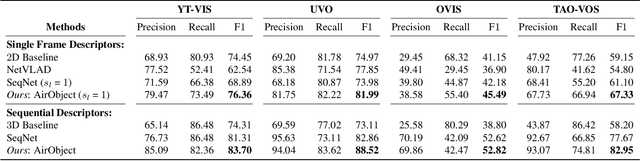
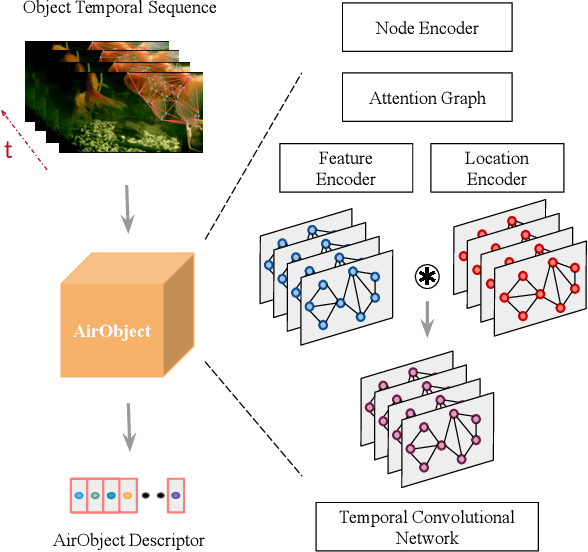
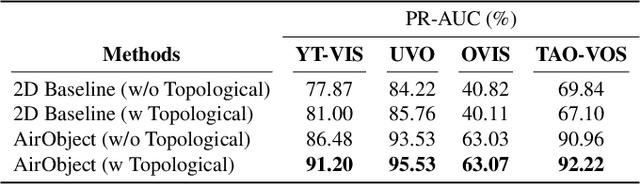
Object encoding and identification are vital for robotic tasks such as autonomous exploration, semantic scene understanding, and re-localization. Previous approaches have attempted to either track objects or generate descriptors for object identification. However, such systems are limited to a "fixed" partial object representation from a single viewpoint. In a robot exploration setup, there is a requirement for a temporally "evolving" global object representation built as the robot observes the object from multiple viewpoints. Furthermore, given the vast distribution of unknown novel objects in the real world, the object identification process must be class-agnostic. In this context, we propose a novel temporal 3D object encoding approach, dubbed AirObject, to obtain global keypoint graph-based embeddings of objects. Specifically, the global 3D object embeddings are generated using a temporal convolutional network across structural information of multiple frames obtained from a graph attention-based encoding method. We demonstrate that AirObject achieves the state-of-the-art performance for video object identification and is robust to severe occlusion, perceptual aliasing, viewpoint shift, deformation, and scale transform, outperforming the state-of-the-art single-frame and sequential descriptors. To the best of our knowledge, AirObject is one of the first temporal object encoding methods.
A Hierarchical Dual Model of Environment- and Place-Specific Utility for Visual Place Recognition
Jul 06, 2021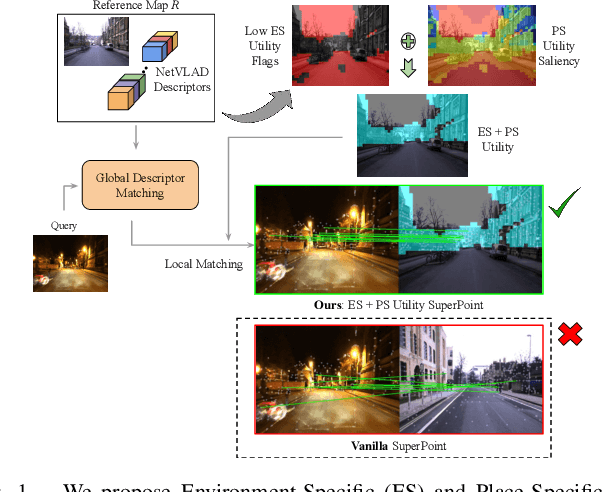
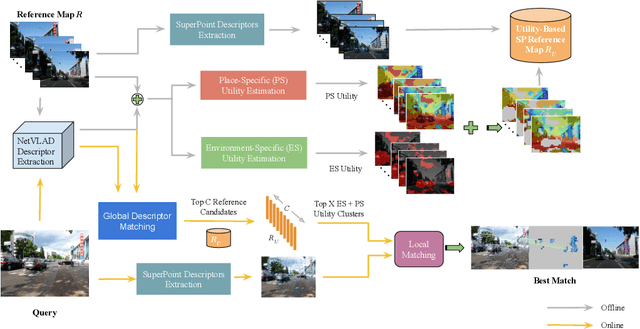
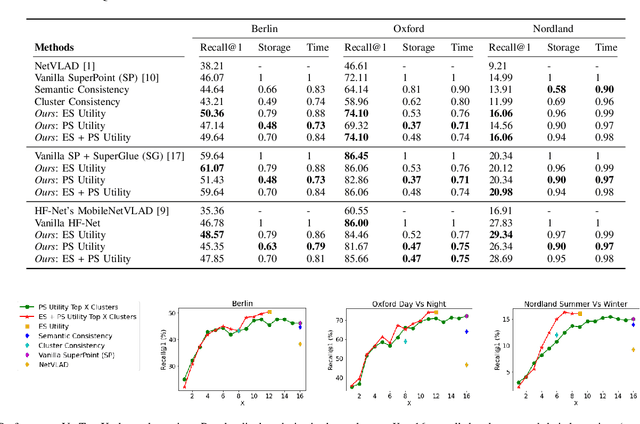
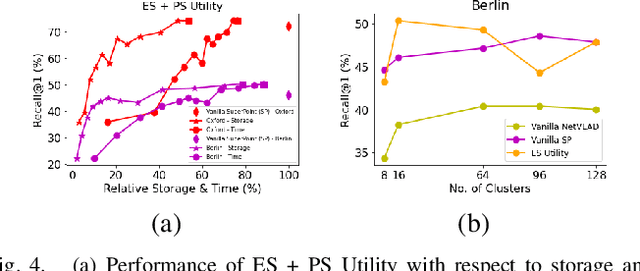
Visual Place Recognition (VPR) approaches have typically attempted to match places by identifying visual cues, image regions or landmarks that have high ``utility'' in identifying a specific place. But this concept of utility is not singular - rather it can take a range of forms. In this paper, we present a novel approach to deduce two key types of utility for VPR: the utility of visual cues `specific' to an environment, and to a particular place. We employ contrastive learning principles to estimate both the environment- and place-specific utility of Vector of Locally Aggregated Descriptors (VLAD) clusters in an unsupervised manner, which is then used to guide local feature matching through keypoint selection. By combining these two utility measures, our approach achieves state-of-the-art performance on three challenging benchmark datasets, while simultaneously reducing the required storage and compute time. We provide further analysis demonstrating that unsupervised cluster selection results in semantically meaningful results, that finer grained categorization often has higher utility for VPR than high level semantic categorization (e.g. building, road), and characterise how these two utility measures vary across different places and environments. Source code is made publicly available at https://github.com/Nik-V9/HEAPUtil.
U-Det: A Modified U-Net architecture with bidirectional feature network for lung nodule segmentation
Mar 20, 2020
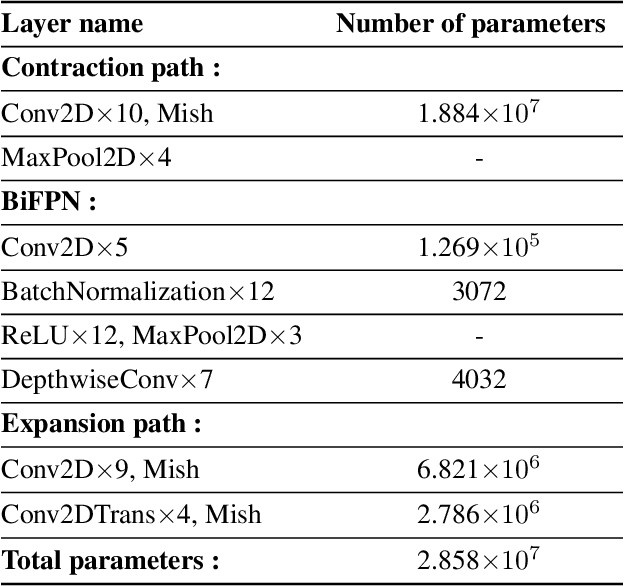

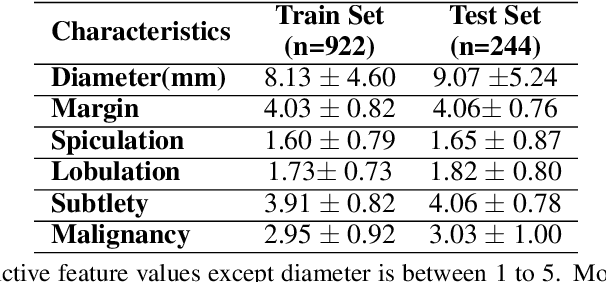
Early diagnosis and analysis of lung cancer involve a precise and efficient lung nodule segmentation in computed tomography (CT) images. However, the anonymous shapes, visual features, and surroundings of the nodule in the CT image pose a challenging problem to the robust segmentation of the lung nodules. This article proposes U-Det, a resource-efficient model architecture, which is an end to end deep learning approach to solve the task at hand. It incorporates a Bi-FPN (bidirectional feature network) between the encoder and decoder. Furthermore, it uses Mish activation function and class weights of masks to enhance segmentation efficiency. The proposed model is extensively trained and evaluated on the publicly available LUNA-16 dataset consisting of 1186 lung nodules. The U-Det architecture outperforms the existing U-Net model with the Dice similarity coefficient (DSC) of 82.82% and achieves results comparable to human experts.