 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoing Deeper into Semi-supervised Person Re-identification
Jul 24, 2021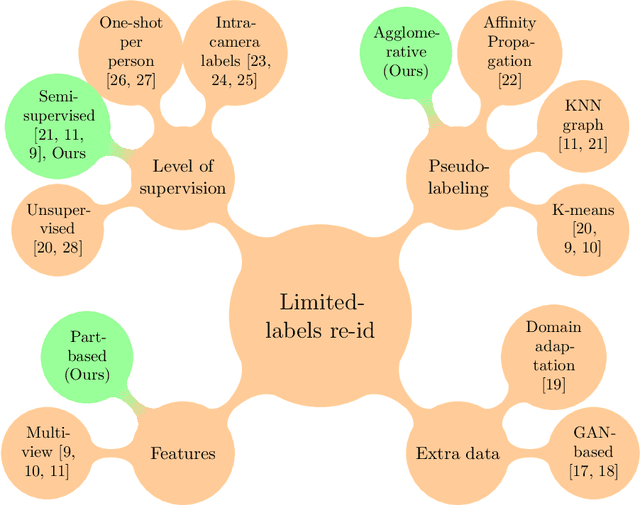
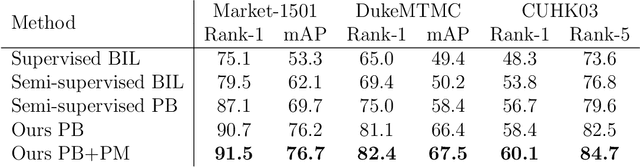
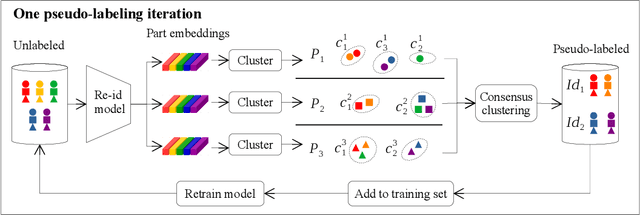

Person re-identification is the challenging task of identifying a person across different camera views. Training a convolutional neural network (CNN) for this task requires annotating a large dataset, and hence, it involves the time-consuming manual matching of people across cameras. To reduce the need for labeled data, we focus on a semi-supervised approach that requires only a subset of the training data to be labeled. We conduct a comprehensive survey in the area of person re-identification with limited labels. Existing works in this realm are limited in the sense that they utilize features from multiple CNNs and require the number of identities in the unlabeled data to be known. To overcome these limitations, we propose to employ part-based features from a single CNN without requiring the knowledge of the label space (i.e., the number of identities). This makes our approach more suitable for practical scenarios, and it significantly reduces the need for computational resources. We also propose a PartMixUp loss that improves the discriminative ability of learned part-based features for pseudo-labeling in semi-supervised settings. Our method outperforms the state-of-the-art results on three large-scale person re-id datasets and achieves the same level of performance as fully supervised methods with only one-third of labeled identities.
Semi-supervised Keypoint Localization
Jan 20, 2021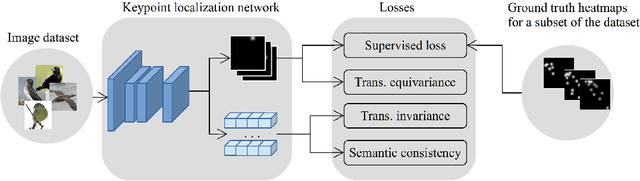
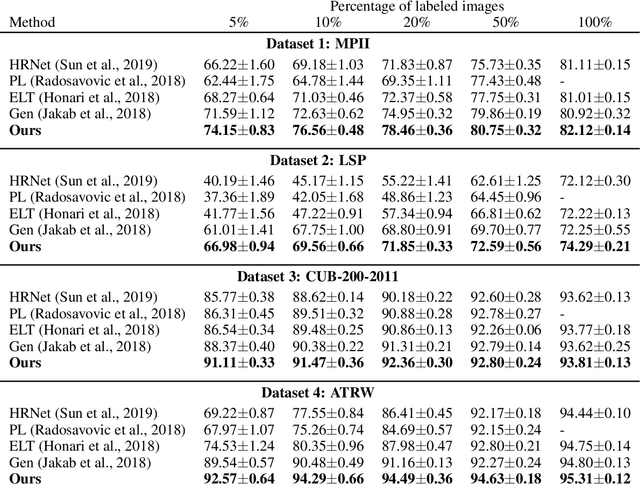
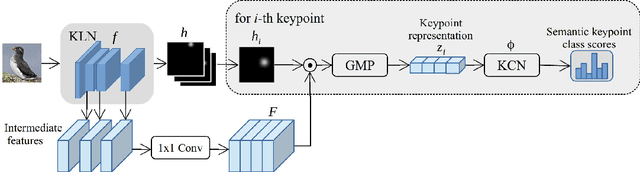
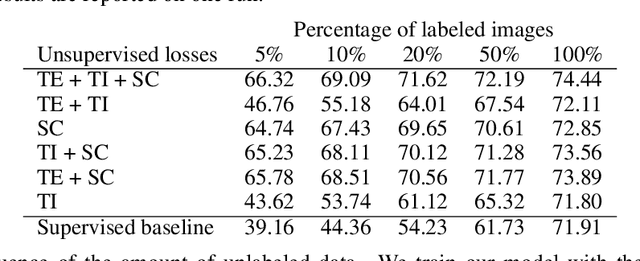
Knowledge about the locations of keypoints of an object in an image can assist in fine-grained classification and identification tasks, particularly for the case of objects that exhibit large variations in poses that greatly influence their visual appearance, such as wild animals. However, supervised training of a keypoint detection network requires annotating a large image dataset for each animal species, which is a labor-intensive task. To reduce the need for labeled data, we propose to learn simultaneously keypoint heatmaps and pose invariant keypoint representations in a semi-supervised manner using a small set of labeled images along with a larger set of unlabeled images. Keypoint representations are learnt with a semantic keypoint consistency constraint that forces the keypoint detection network to learn similar features for the same keypoint across the dataset. Pose invariance is achieved by making keypoint representations for the image and its augmented copies closer together in feature space. Our semi-supervised approach significantly outperforms previous methods on several benchmarks for human and animal body landmark localization.
Keypoint-Aligned Embeddings for Image Retrieval and Re-identification
Aug 26, 2020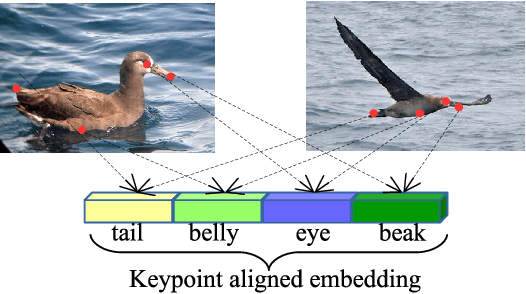

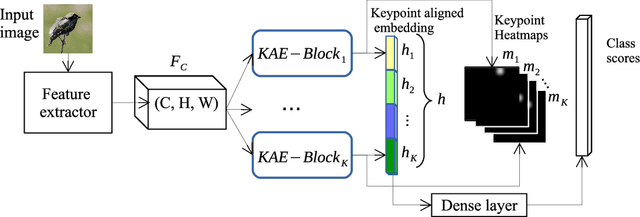
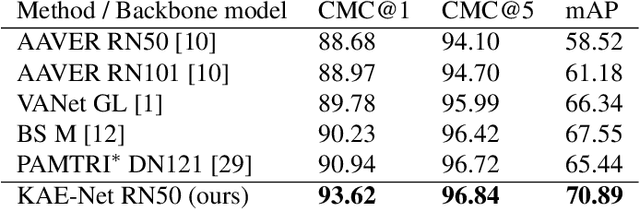
Learning embeddings that are invariant to the pose of the object is crucial in visual image retrieval and re-identification. The existing approaches for person, vehicle, or animal re-identification tasks suffer from high intra-class variance due to deformable shapes and different camera viewpoints. To overcome this limitation, we propose to align the image embedding with a predefined order of the keypoints. The proposed keypoint aligned embeddings model (KAE-Net) learns part-level features via multi-task learning which is guided by keypoint locations. More specifically, KAE-Net extracts channels from a feature map activated by a specific keypoint through learning the auxiliary task of heatmap reconstruction for this keypoint. The KAE-Net is compact, generic and conceptually simple. It achieves state of the art performance on the benchmark datasets of CUB-200-2011, Cars196 and VeRi-776 for retrieval and re-identification tasks.
Learning landmark guided embeddings for animal re-identification
Jan 09, 2020

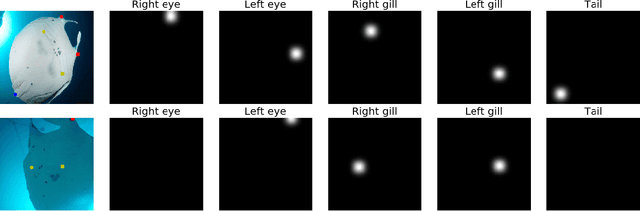
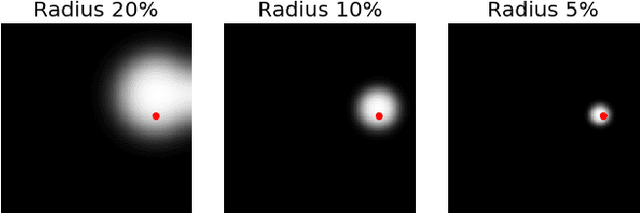
Re-identification of individual animals in images can be ambiguous due to subtle variations in body markings between different individuals and no constraints on the poses of animals in the wild. Person re-identification is a similar task and it has been approached with a deep convolutional neural network (CNN) that learns discriminative embeddings for images of people. However, learning discriminative features for an individual animal is more challenging than for a person's appearance due to the relatively small size of ecological datasets compared to labelled datasets of person's identities. We propose to improve embedding learning by exploiting body landmarks information explicitly. Body landmarks are provided to the input of a CNN as confidence heatmaps that can be obtained from a separate body landmark predictor. The model is encouraged to use heatmaps by learning an auxiliary task of reconstructing input heatmaps. Body landmarks guide a feature extraction network to learn the representation of a distinctive pattern and its position on the body. We evaluate the proposed method on a large synthetic dataset and a small real dataset. Our method outperforms the same model without body landmarks input by 26% and 18% on the synthetic and the real datasets respectively. The method is robust to noise in input coordinates and can tolerate an error in coordinates up to 10% of the image size.
Robust Re-identification of Manta Rays from Natural Markings by Learning Pose Invariant Embeddings
Feb 28, 2019
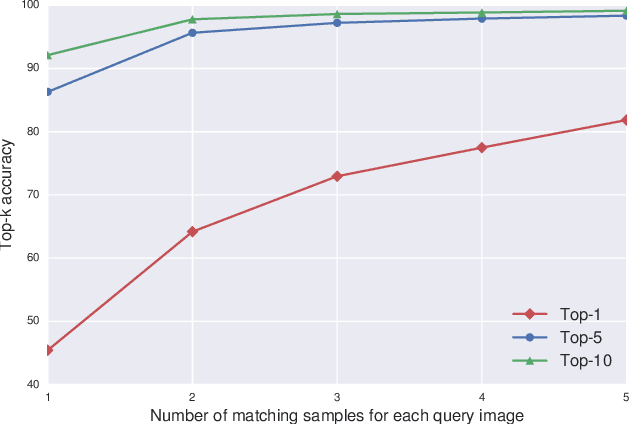


Visual identification of individual animals that bear unique natural body markings is an important task in wildlife conservation. The photo databases of animal markings grow larger and each new observation has to be matched against thousands of images. Existing photo-identification solutions have constraints on image quality and appearance of the pattern of interest in the image. These constraints limit the use of photos from citizen scientists. We present a novel system for visual re-identification based on unique natural markings that is robust to occlusions, viewpoint and illumination changes. We adapt methods developed for face re-identification and implement a deep convolutional neural network (CNN) to learn embeddings for images of natural markings. The distance between the learned embedding points provides a dissimilarity measure between the corresponding input images. The network is optimized using the triplet loss function and the online semi-hard triplet mining strategy. The proposed re-identification method is generic and not species specific. We evaluate the proposed system on image databases of manta ray belly patterns and humpback whale flukes. To be of practical value and adopted by marine biologists, a re-identification system needs to have a top-10 accuracy of at least 95%. The proposed system achieves this performance standard.