 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Model Sharing Improves Byzantine Resilience in Federated Conformal Prediction
May 12, 2026We propose a Byzantine-resilient federated conformal prediction (FCP) method that leverages partial model sharing, where only a subset of model parameters is exchanged each round. Unlike existing robust FCP approaches that primarily harden the calibration stage, our method protects both the federated training and conformal calibration phases. During training, partial sharing inherently restricts the attack surface and attenuates poisoned updates while reducing communication. During calibration, clients compress their non-conformity scores into histogram-based characterization vectors, enabling the server to detect Byzantine clients via distance-based maliciousness scores and to estimate the conformal quantile using only benign contributors. Experiments across diverse Byzantine attack scenarios show that the proposed method achieves closer-to-nominal coverage with substantially tighter prediction intervals than standard FCP, establishing a robust and communication-efficient approach to federated uncertainty quantification.
Backdoor Mitigation in Object Detection via Adversarial Fine-Tuning
May 07, 2026Backdoor attacks can implant malicious behaviours into deep models while preserving performance on clean data, posing a serious threat to safety-critical vision systems. Although backdoor mitigation has been studied extensively for image classification, defenses for object detection remain comparatively underdeveloped. Adversarial fine-tuning is a common backdoor mitigation approach in classification, but adapting it to detection is nontrivial as classification-oriented adversarial generation does not match the detection attack space, where attacks may cause object misclassification or disappearance, and standard detection losses can dilute the repair signal across many predictions. We address these challenges through a detection-aware adversarial fine-tuning framework for mitigating object-detection backdoors when the defender has access only to a compromised detector and a small clean dataset, without knowing the attack objective. For adversarial generation that does not require knowledge of the attack objective, we introduce soft-branch minimisation, which uses a soft gate to combine objectives aligned with misclassification and disappearance attacks, together with a detection-aware classification-loss maximisation. For targeted repair, we introduce a dual-objective fine-tuning loss applied to target-matched predictions, concentrating the defensive update on predictions most relevant to the backdoor behaviour. Experiments across CNN- and Transformer-based detectors show that our approach more effectively reduces attack success while preserving true detections, compared with classification-oriented baselines, and maintains competitive clean detection performance.
BadDet+: Robust Backdoor Attacks for Object Detection
Jan 28, 2026Backdoor attacks pose a severe threat to deep learning, yet their impact on object detection remains poorly understood compared to image classification. While attacks have been proposed, we identify critical weaknesses in existing detection-based methods, specifically their reliance on unrealistic assumptions and a lack of physical validation. To bridge this gap, we introduce BadDet+, a penalty-based framework that unifies Region Misclassification Attacks (RMA) and Object Disappearance Attacks (ODA). The core mechanism utilizes a log-barrier penalty to suppress true-class predictions for triggered inputs, resulting in (i) position and scale invariance, and (ii) enhanced physical robustness. On real-world benchmarks, BadDet+ achieves superior synthetic-to-physical transfer compared to existing RMA and ODA baselines while preserving clean performance. Theoretical analysis confirms the proposed penalty acts within a trigger-specific feature subspace, reliably inducing attacks without degrading standard inference. These results highlight significant vulnerabilities in object detection and the necessity for specialized defenses.
SA-PEF: Step-Ahead Partial Error Feedback for Efficient Federated Learning
Jan 28, 2026Biased gradient compression with error feedback (EF) reduces communication in federated learning (FL), but under non-IID data, the residual error can decay slowly, causing gradient mismatch and stalled progress in the early rounds. We propose step-ahead partial error feedback (SA-PEF), which integrates step-ahead (SA) correction with partial error feedback (PEF). SA-PEF recovers EF when the step-ahead coefficient $α=0$ and step-ahead EF (SAEF) when $α=1$. For non-convex objectives and $δ$-contractive compressors, we establish a second-moment bound and a residual recursion that guarantee convergence to stationarity under heterogeneous data and partial client participation. The resulting rates match standard non-convex Fed-SGD guarantees up to constant factors, achieving $O((η,η_0TR)^{-1})$ convergence to a variance/heterogeneity floor with a fixed inner step size. Our analysis reveals a step-ahead-controlled residual contraction $ρ_r$ that explains the observed acceleration in the early training phase. To balance SAEF's rapid warm-up with EF's long-term stability, we select $α$ near its theory-predicted optimum. Experiments across diverse architectures and datasets show that SA-PEF consistently reaches target accuracy faster than EF.
Efficient Incremental SLAM via Information-Guided and Selective Optimization
Jan 13, 2026We present an efficient incremental SLAM back-end that achieves the accuracy of full batch optimization while substantially reducing computational cost. The proposed approach combines two complementary ideas: information-guided gating (IGG) and selective partial optimization (SPO). IGG employs an information-theoretic criterion based on the log-determinant of the information matrix to quantify the contribution of new measurements, triggering global optimization only when a significant information gain is observed. This avoids unnecessary relinearization and factorization when incoming data provide little additional information. SPO executes multi-iteration Gauss-Newton (GN) updates but restricts each iteration to the subset of variables most affected by the new measurements, dynamically refining this active set until convergence. Together, these mechanisms retain all measurements to preserve global consistency while focusing computation on parts of the graph where it yields the greatest benefit. We provide theoretical analysis showing that the proposed approach maintains the convergence guarantees of full GN. Extensive experiments on benchmark SLAM datasets show that our approach consistently matches the estimation accuracy of batch solvers, while achieving significant computational savings compared to conventional incremental approaches. The results indicate that the proposed approach offers a principled balance between accuracy and efficiency, making it a robust and scalable solution for real-time operation in dynamic data-rich environments.
Backdoor Mitigation via Invertible Pruning Masks
Sep 19, 2025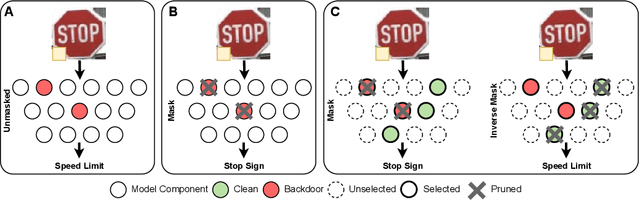
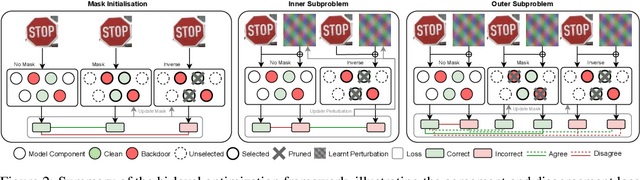

Model pruning has gained traction as a promising defense strategy against backdoor attacks in deep learning. However, existing pruning-based approaches often fall short in accurately identifying and removing the specific parameters responsible for inducing backdoor behaviors. Despite the dominance of fine-tuning-based defenses in recent literature, largely due to their superior performance, pruning remains a compelling alternative, offering greater interpretability and improved robustness in low-data regimes. In this paper, we propose a novel pruning approach featuring a learned \emph{selection} mechanism to identify parameters critical to both main and backdoor tasks, along with an \emph{invertible} pruning mask designed to simultaneously achieve two complementary goals: eliminating the backdoor task while preserving it through the inverse mask. We formulate this as a bi-level optimization problem that jointly learns selection variables, a sparse invertible mask, and sample-specific backdoor perturbations derived from clean data. The inner problem synthesizes candidate triggers using the inverse mask, while the outer problem refines the mask to suppress backdoor behavior without impairing clean-task accuracy. Extensive experiments demonstrate that our approach outperforms existing pruning-based backdoor mitigation approaches, maintains strong performance under limited data conditions, and achieves competitive results compared to state-of-the-art fine-tuning approaches. Notably, the proposed approach is particularly effective in restoring correct predictions for compromised samples after successful backdoor mitigation.
Countering Backdoor Attacks in Image Recognition: A Survey and Evaluation of Mitigation Strategies
Nov 17, 2024
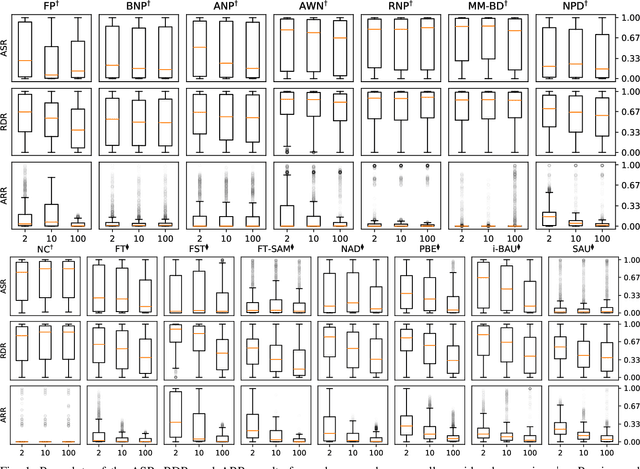
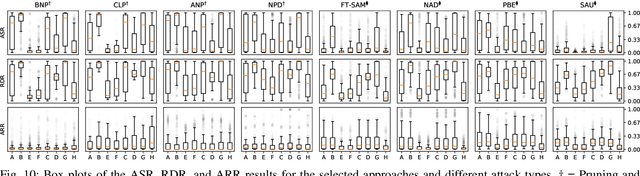

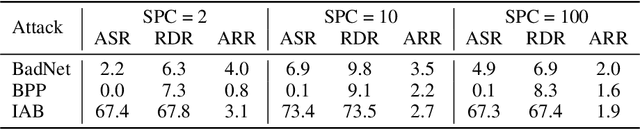
The widespread adoption of deep learning across various industries has introduced substantial challenges, particularly in terms of model explainability and security. The inherent complexity of deep learning models, while contributing to their effectiveness, also renders them susceptible to adversarial attacks. Among these, backdoor attacks are especially concerning, as they involve surreptitiously embedding specific triggers within training data, causing the model to exhibit aberrant behavior when presented with input containing the triggers. Such attacks often exploit vulnerabilities in outsourced processes, compromising model integrity without affecting performance on clean (trigger-free) input data. In this paper, we present a comprehensive review of existing mitigation strategies designed to counter backdoor attacks in image recognition. We provide an in-depth analysis of the theoretical foundations, practical efficacy, and limitations of these approaches. In addition, we conduct an extensive benchmarking of sixteen state-of-the-art approaches against eight distinct backdoor attacks, utilizing three datasets, four model architectures, and three poisoning ratios. Our results, derived from 122,236 individual experiments, indicate that while many approaches provide some level of protection, their performance can vary considerably. Furthermore, when compared to two seminal approaches, most newer approaches do not demonstrate substantial improvements in overall performance or consistency across diverse settings. Drawing from these findings, we propose potential directions for developing more effective and generalizable defensive mechanisms in the future.
Unlearning Backdoor Attacks through Gradient-Based Model Pruning
May 07, 2024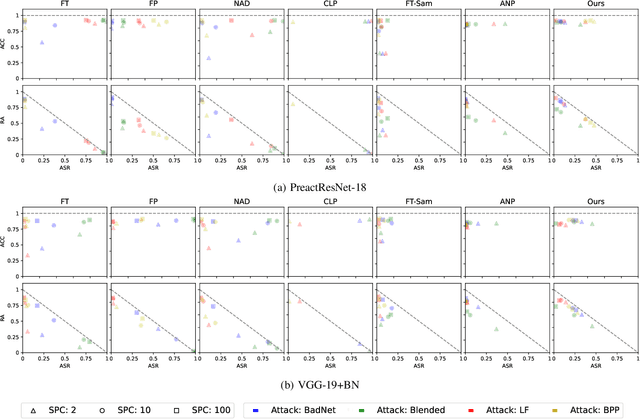
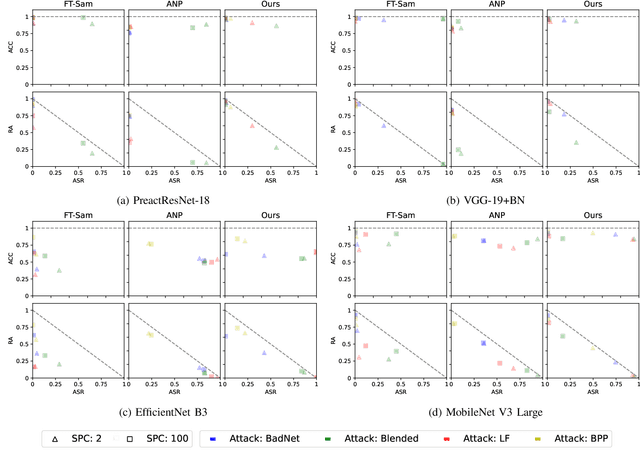
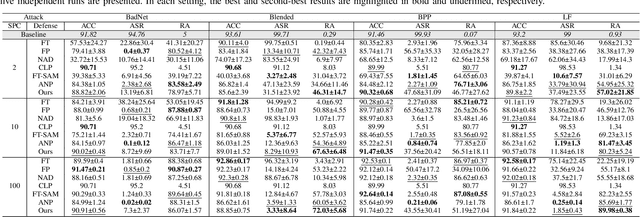
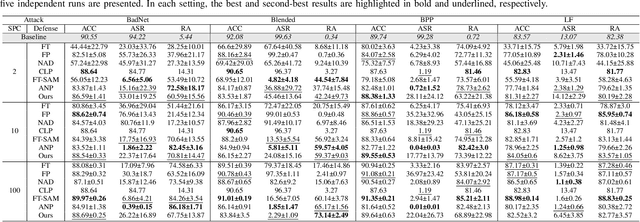
In the era of increasing concerns over cybersecurity threats, defending against backdoor attacks is paramount in ensuring the integrity and reliability of machine learning models. However, many existing approaches require substantial amounts of data for effective mitigation, posing significant challenges in practical deployment. To address this, we propose a novel approach to counter backdoor attacks by treating their mitigation as an unlearning task. We tackle this challenge through a targeted model pruning strategy, leveraging unlearning loss gradients to identify and eliminate backdoor elements within the model. Built on solid theoretical insights, our approach offers simplicity and effectiveness, rendering it well-suited for scenarios with limited data availability. Our methodology includes formulating a suitable unlearning loss and devising a model-pruning technique tailored for convolutional neural networks. Comprehensive evaluations demonstrate the efficacy of our proposed approach compared to state-of-the-art approaches, particularly in realistic data settings.
Distributed Maximum Consensus over Noisy Links
Mar 27, 2024



We introduce a distributed algorithm, termed noise-robust distributed maximum consensus (RD-MC), for estimating the maximum value within a multi-agent network in the presence of noisy communication links. Our approach entails redefining the maximum consensus problem as a distributed optimization problem, allowing a solution using the alternating direction method of multipliers. Unlike existing algorithms that rely on multiple sets of noise-corrupted estimates, RD-MC employs a single set, enhancing both robustness and efficiency. To further mitigate the effects of link noise and improve robustness, we apply moving averaging to the local estimates. Through extensive simulations, we demonstrate that RD-MC is significantly more robust to communication link noise compared to existing maximum-consensus algorithms.
Privacy-Preserving Distributed Nonnegative Matrix Factorization
Mar 27, 2024
Nonnegative matrix factorization (NMF) is an effective data representation tool with numerous applications in signal processing and machine learning. However, deploying NMF in a decentralized manner over ad-hoc networks introduces privacy concerns due to the conventional approach of sharing raw data among network agents. To address this, we propose a privacy-preserving algorithm for fully-distributed NMF that decomposes a distributed large data matrix into left and right matrix factors while safeguarding each agent's local data privacy. It facilitates collaborative estimation of the left matrix factor among agents and enables them to estimate their respective right factors without exposing raw data. To ensure data privacy, we secure information exchanges between neighboring agents utilizing the Paillier cryptosystem, a probabilistic asymmetric algorithm for public-key cryptography that allows computations on encrypted data without decryption. Simulation results conducted on synthetic and real-world datasets demonstrate the effectiveness of the proposed algorithm in achieving privacy-preserving distributed NMF over ad-hoc networks.