 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIoT Data Trust Evaluation via Machine Learning
Paper and Code
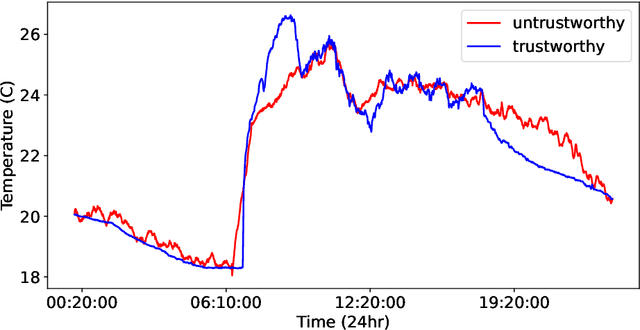
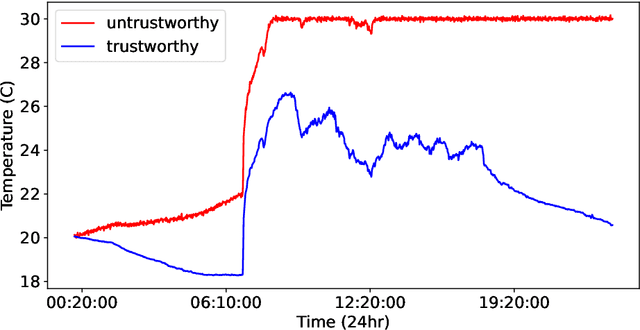
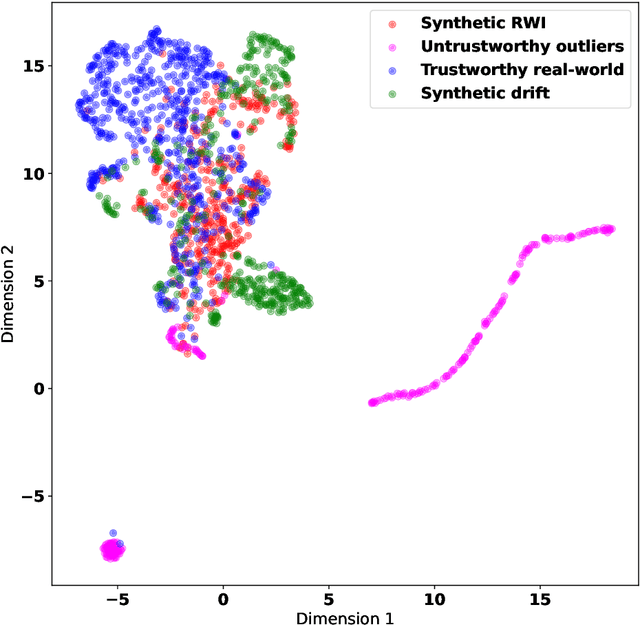
Various approaches based on supervised or unsupervised machine learning (ML) have been proposed for evaluating IoT data trust. However, assessing their real-world efficacy is hard mainly due to the lack of related publicly-available datasets that can be used for benchmarking. Since obtaining such datasets is challenging, we propose a data synthesis method, called random walk infilling (RWI), to augment IoT time-series datasets by synthesizing untrustworthy data from existing trustworthy data. Thus, RWI enables us to create labeled datasets that can be used to develop and validate ML models for IoT data trust evaluation. We also extract new features from IoT time-series sensor data that effectively capture its auto-correlation as well as its cross-correlation with the data of the neighboring (peer) sensors. These features can be used to learn ML models for recognizing the trustworthiness of IoT sensor data. Equipped with our synthesized ground-truth-labeled datasets and informative correlation-based feature, we conduct extensive experiments to critically examine various approaches to evaluating IoT data trust via ML. The results reveal that commonly used ML-based approaches to IoT data trust evaluation, which rely on unsupervised cluster analysis to assign trust labels to unlabeled data, perform poorly. This poor performance can be attributed to the underlying unsubstantiated assumption that clustering provides reliable labels for data trust, a premise that is found to be untenable. The results also show that the ML models learned from datasets augmented via RWI while using the proposed features generalize well to unseen data and outperform existing related approaches. Moreover, we observe that a semi-supervised ML approach that requires only about 10% of the data labeled offers competitive performance while being practically more appealing compared to the fully-supervised approaches.