 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Impact of Partial Sharing on the Resilience of Online Federated Learning Against Model Poisoning Attacks
Mar 19, 2024We scrutinize the resilience of the partial-sharing online federated learning (PSO-Fed) algorithm against model-poisoning attacks. PSO-Fed reduces the communication load by enabling clients to exchange only a fraction of their model estimates with the server at each update round. Partial sharing of model estimates also enhances the robustness of the algorithm against model-poisoning attacks. To gain better insights into this phenomenon, we analyze the performance of the PSO-Fed algorithm in the presence of Byzantine clients, malicious actors who may subtly tamper with their local models by adding noise before sharing them with the server. Through our analysis, we demonstrate that PSO-Fed maintains convergence in both mean and mean-square senses, even under the strain of model-poisoning attacks. We further derive the theoretical mean square error (MSE) of PSO-Fed, linking it to various parameters such as stepsize, attack probability, number of Byzantine clients, client participation rate, partial-sharing ratio, and noise variance. We also show that there is a non-trivial optimal stepsize for PSO-Fed when faced with model-poisoning attacks. The results of our extensive numerical experiments affirm our theoretical assertions and highlight the superior ability of PSO-Fed to counteract Byzantine attacks, outperforming other related leading algorithms.
Efficient Knowledge Deletion from Trained Models through Layer-wise Partial Machine Unlearning
Mar 12, 2024Machine unlearning has garnered significant attention due to its ability to selectively erase knowledge obtained from specific training data samples in an already trained machine learning model. This capability enables data holders to adhere strictly to data protection regulations. However, existing unlearning techniques face practical constraints, often causing performance degradation, demanding brief fine-tuning post unlearning, and requiring significant storage. In response, this paper introduces a novel class of machine unlearning algorithms. First method is partial amnesiac unlearning, integration of layer-wise pruning with amnesiac unlearning. In this method, updates made to the model during training are pruned and stored, subsequently used to forget specific data from trained model. The second method assimilates layer-wise partial-updates into label-flipping and optimization-based unlearning to mitigate the adverse effects of data deletion on model efficacy. Through a detailed experimental evaluation, we showcase the effectiveness of proposed unlearning methods. Experimental results highlight that the partial amnesiac unlearning not only preserves model efficacy but also eliminates the necessity for brief post fine-tuning, unlike conventional amnesiac unlearning. Moreover, employing layer-wise partial updates in label-flipping and optimization-based unlearning techniques demonstrates superiority in preserving model efficacy compared to their naive counterparts.
Smoothing ADMM for Sparse-Penalized Quantile Regression with Non-Convex Penalties
Sep 04, 2023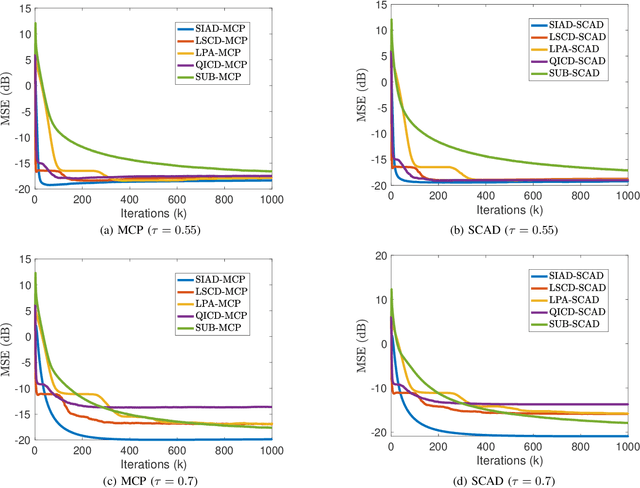
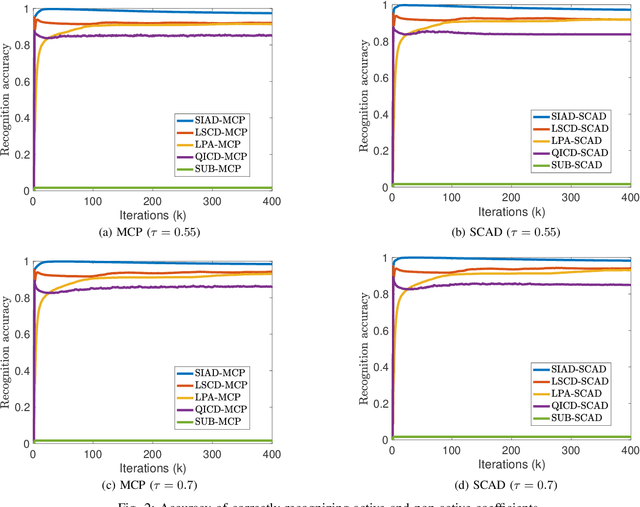
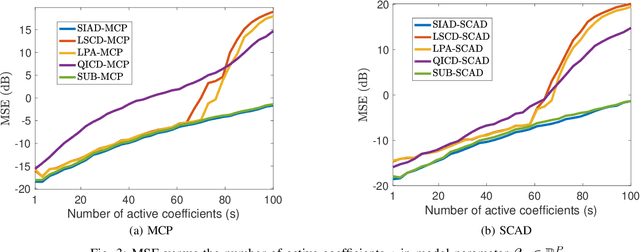
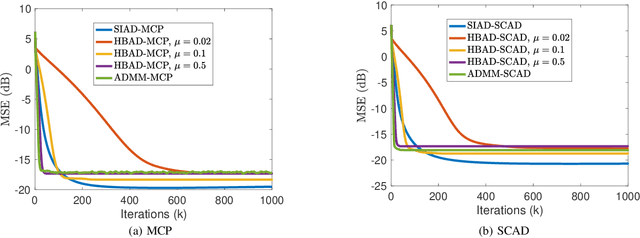
This paper investigates quantile regression in the presence of non-convex and non-smooth sparse penalties, such as the minimax concave penalty (MCP) and smoothly clipped absolute deviation (SCAD). The non-smooth and non-convex nature of these problems often leads to convergence difficulties for many algorithms. While iterative techniques like coordinate descent and local linear approximation can facilitate convergence, the process is often slow. This sluggish pace is primarily due to the need to run these approximation techniques until full convergence at each step, a requirement we term as a \emph{secondary convergence iteration}. To accelerate the convergence speed, we employ the alternating direction method of multipliers (ADMM) and introduce a novel single-loop smoothing ADMM algorithm with an increasing penalty parameter, named SIAD, specifically tailored for sparse-penalized quantile regression. We first delve into the convergence properties of the proposed SIAD algorithm and establish the necessary conditions for convergence. Theoretically, we confirm a convergence rate of $o\big({k^{-\frac{1}{4}}}\big)$ for the sub-gradient bound of augmented Lagrangian. Subsequently, we provide numerical results to showcase the effectiveness of the SIAD algorithm. Our findings highlight that the SIAD method outperforms existing approaches, providing a faster and more stable solution for sparse-penalized quantile regression.
Distributed Filtering Design with Enhanced Resilience to Coordinated Byzantine Attacks
Jul 26, 2023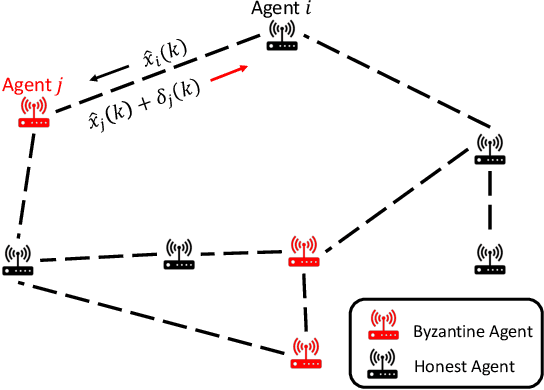
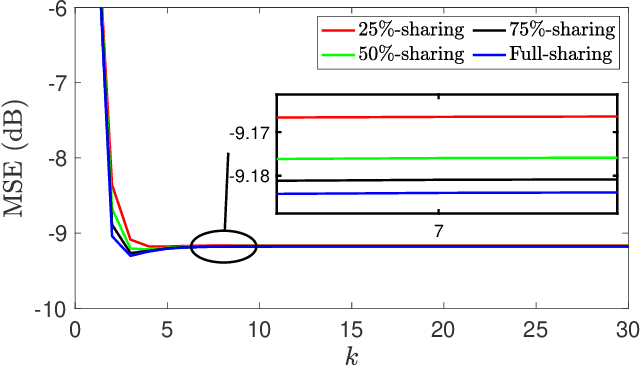
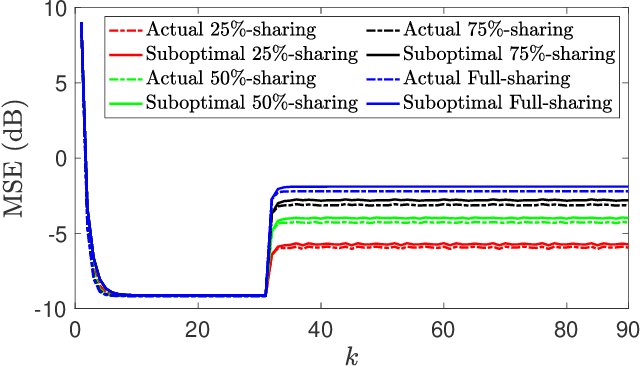
This paper proposes a Byzantine-resilient consensus-based distributed filter (BR-CDF) wherein network agents employ partial sharing of state parameters. We characterize the performance and convergence of the BR-CDF and study the impact of a coordinated data falsification attack. Our analysis shows that sharing merely a fraction of the states improves robustness against coordinated Byzantine attacks. In addition, we model the optimal attack strategy as an optimization problem where Byzantine agents design their attack covariance or the sequence of shared fractions to maximize the network-wide mean squared error (MSE). Numerical results demonstrate the accuracy of the proposed BR-CDF and its robustness against Byzantine attacks. Furthermore, the simulation results show that the influence of the covariance design is more pronounced when agents exchange larger portions of their states with neighbors. In contrast, the performance is more sensitive to the sequence of shared fractions when smaller portions are exchanged.
Personalized Graph Federated Learning with Differential Privacy
Jun 10, 2023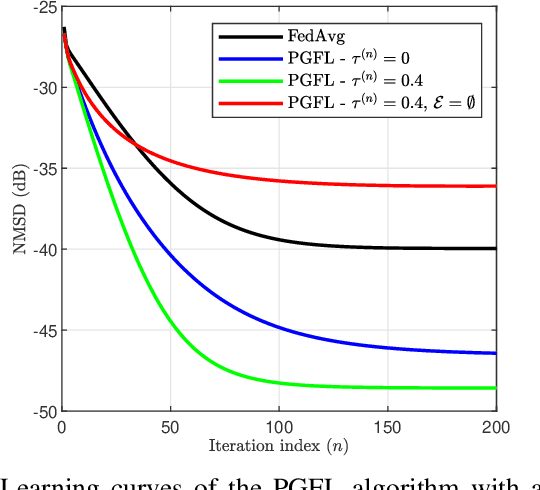
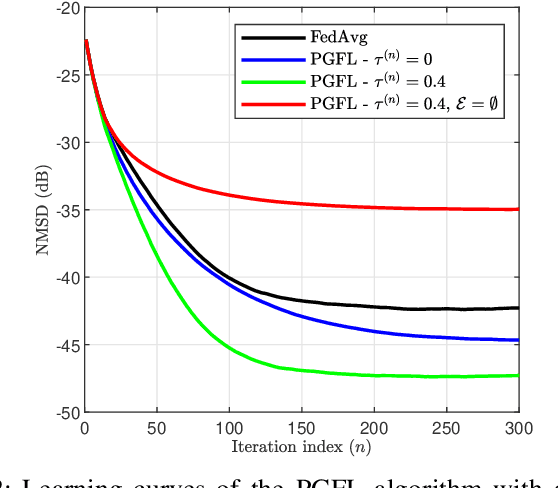
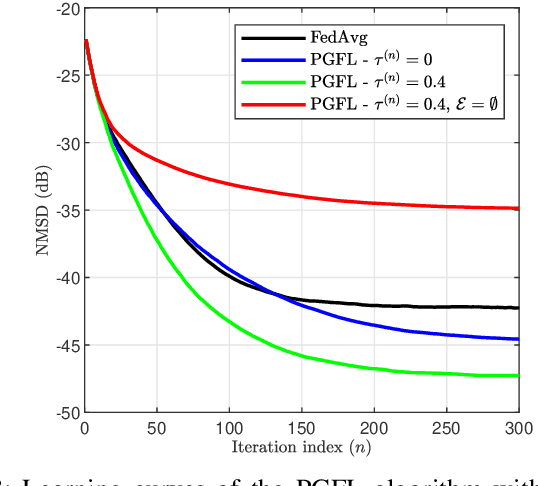
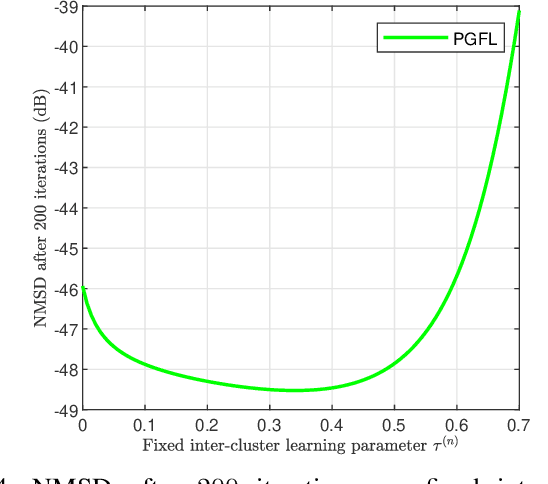
This paper presents a personalized graph federated learning (PGFL) framework in which distributedly connected servers and their respective edge devices collaboratively learn device or cluster-specific models while maintaining the privacy of every individual device. The proposed approach exploits similarities among different models to provide a more relevant experience for each device, even in situations with diverse data distributions and disproportionate datasets. Furthermore, to ensure a secure and efficient approach to collaborative personalized learning, we study a variant of the PGFL implementation that utilizes differential privacy, specifically zero-concentrated differential privacy, where a noise sequence perturbs model exchanges. Our mathematical analysis shows that the proposed privacy-preserving PGFL algorithm converges to the optimal cluster-specific solution for each cluster in linear time. It also shows that exploiting similarities among clusters leads to an alternative output whose distance to the original solution is bounded, and that this bound can be adjusted by modifying the algorithm's hyperparameters. Further, our analysis shows that the algorithm ensures local differential privacy for all clients in terms of zero-concentrated differential privacy. Finally, the performance of the proposed PGFL algorithm is examined by performing numerical experiments in the context of regression and classification using synthetic data and the MNIST dataset.
Asynchronous Online Federated Learning with Reduced Communication Requirements
Apr 11, 2023Online federated learning (FL) enables geographically distributed devices to learn a global shared model from locally available streaming data. Most online FL literature considers a best-case scenario regarding the participating clients and the communication channels. However, these assumptions are often not met in real-world applications. Asynchronous settings can reflect a more realistic environment, such as heterogeneous client participation due to available computational power and battery constraints, as well as delays caused by communication channels or straggler devices. Further, in most applications, energy efficiency must be taken into consideration. Using the principles of partial-sharing-based communications, we propose a communication-efficient asynchronous online federated learning (PAO-Fed) strategy. By reducing the communication overhead of the participants, the proposed method renders participation in the learning task more accessible and efficient. In addition, the proposed aggregation mechanism accounts for random participation, handles delayed updates and mitigates their effect on accuracy. We prove the first and second-order convergence of the proposed PAO-Fed method and obtain an expression for its steady-state mean square deviation. Finally, we conduct comprehensive simulations to study the performance of the proposed method on both synthetic and real-life datasets. The simulations reveal that in asynchronous settings, the proposed PAO-Fed is able to achieve the same convergence properties as that of the online federated stochastic gradient while reducing the communication overhead by 98 percent.
Resource-Aware Asynchronous Online Federated Learning for Nonlinear Regression
Nov 27, 2021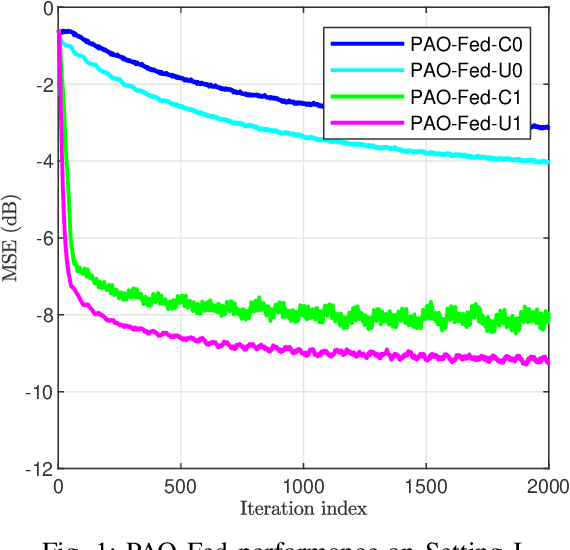

Many assumptions in the federated learning literature present a best-case scenario that can not be satisfied in most real-world applications. An asynchronous setting reflects the realistic environment in which federated learning methods must be able to operate reliably. Besides varying amounts of non-IID data at participants, the asynchronous setting models heterogeneous client participation due to available computational power and battery constraints and also accounts for delayed communications between clients and the server. To reduce the communication overhead associated with asynchronous online federated learning (ASO-Fed), we use the principles of partial-sharing-based communication. In this manner, we reduce the communication load of the participants and, therefore, render participation in the learning task more accessible. We prove the convergence of the proposed ASO-Fed and provide simulations to analyze its behavior further. The simulations reveal that, in the asynchronous setting, it is possible to achieve the same convergence as the federated stochastic gradient (Online-FedSGD) while reducing the communication tenfold.
Communication-Efficient Online Federated Learning Framework for Nonlinear Regression
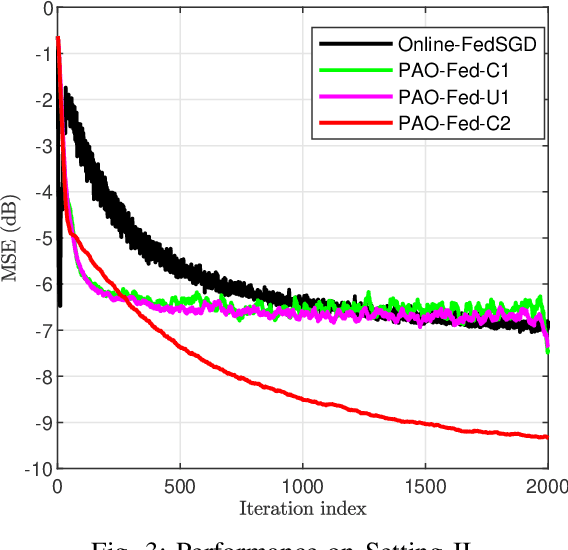
Oct 13, 2021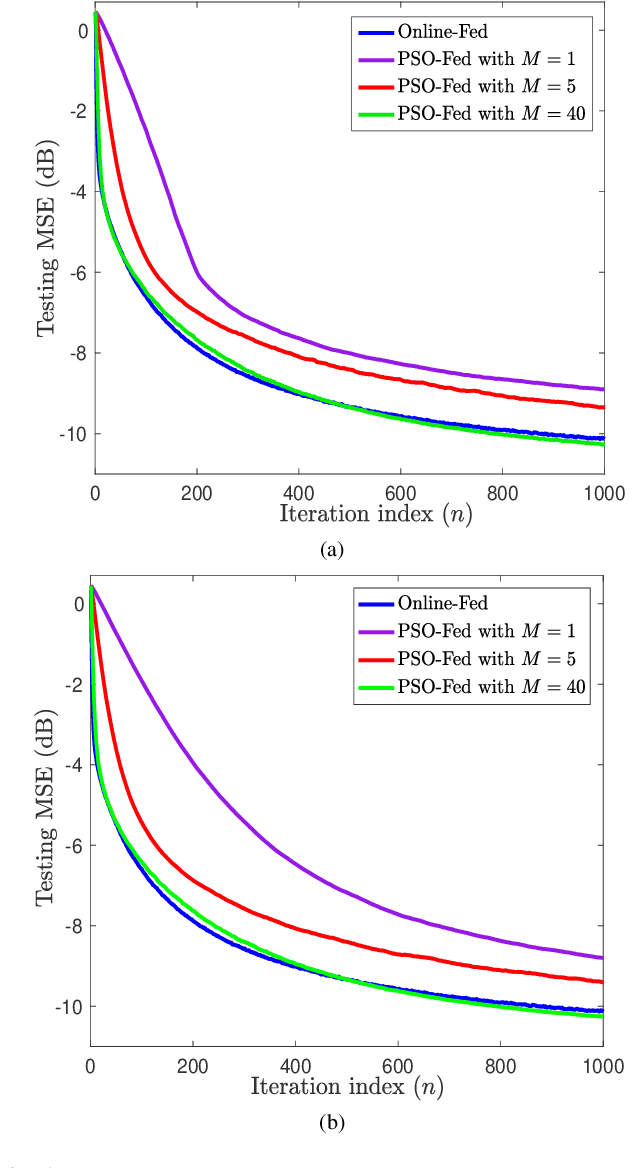
Federated learning (FL) literature typically assumes that each client has a fixed amount of data, which is unrealistic in many practical applications. Some recent works introduced a framework for online FL (Online-Fed) wherein clients perform model learning on streaming data and communicate the model to the server; however, they do not address the associated communication overhead. As a solution, this paper presents a partial-sharing-based online federated learning framework (PSO-Fed) that enables clients to update their local models using continuous streaming data and share only portions of those updated models with the server. During a global iteration of PSO-Fed, non-participant clients have the privilege to update their local models with new data. Here, we consider a global task of kernel regression, where clients use a random Fourier features-based kernel LMS on their data for local learning. We examine the mean convergence of the PSO-Fed for kernel regression. Experimental results show that PSO-Fed can achieve competitive performance with a significantly lower communication overhead than Online-Fed.
Diffusion Adaptation Over Clustered Multitask Networks Based on the Affine Projection Algorithm
Oct 01, 2015
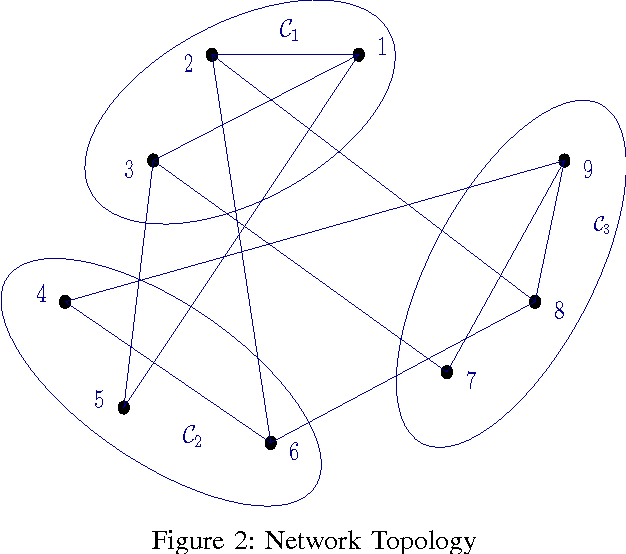
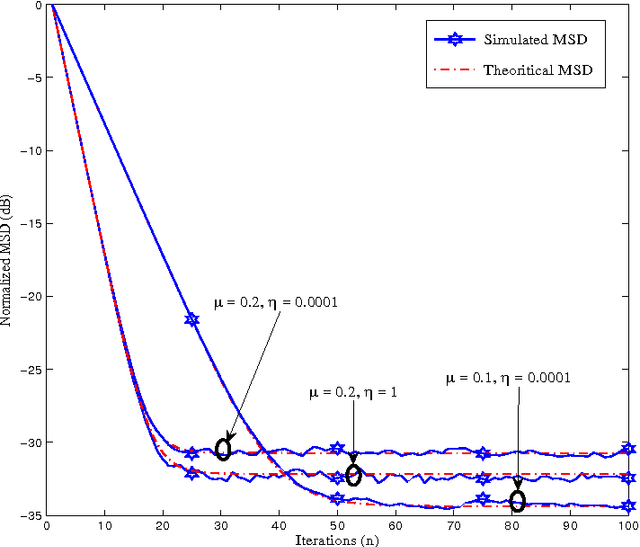
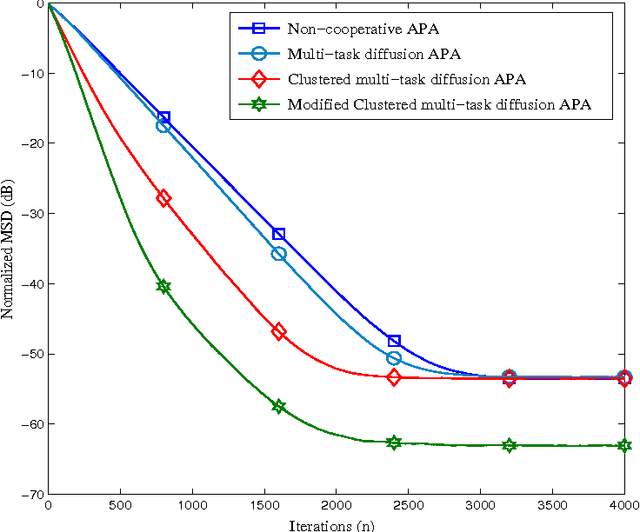
Distributed adaptive networks achieve better estimation performance by exploiting temporal and as well spatial diversity while consuming few resources. Recent works have studied the single task distributed estimation problem, in which the nodes estimate a single optimum parameter vector collaboratively. However, there are many important applications where the multiple vectors have to estimated simultaneously, in a collaborative manner. This paper presents multi-task diffusion strategies based on the Affine Projection Algorithm (APA), usage of APA makes the algorithm robust against the correlated input. The performance analysis of the proposed multi-task diffusion APA algorithm is studied in mean and mean square sense. And also a modified multi-task diffusion strategy is proposed that improves the performance in terms of convergence rate and steady state EMSE as well. Simulations are conducted to verify the analytical results.