 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Graph Federated Learning with Differential Privacy
Jun 10, 2023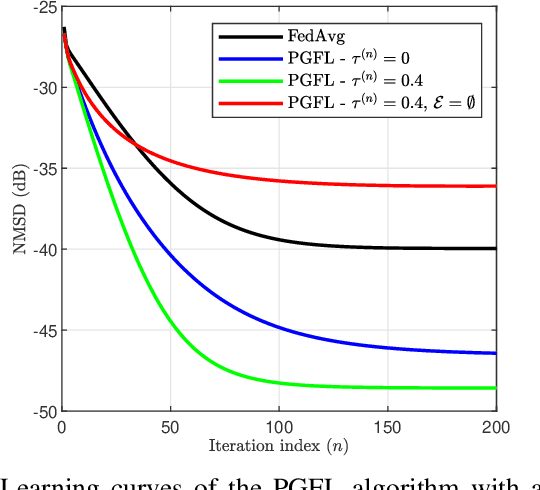
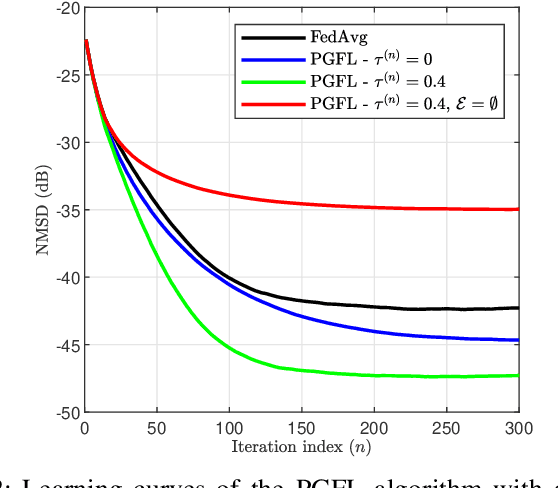
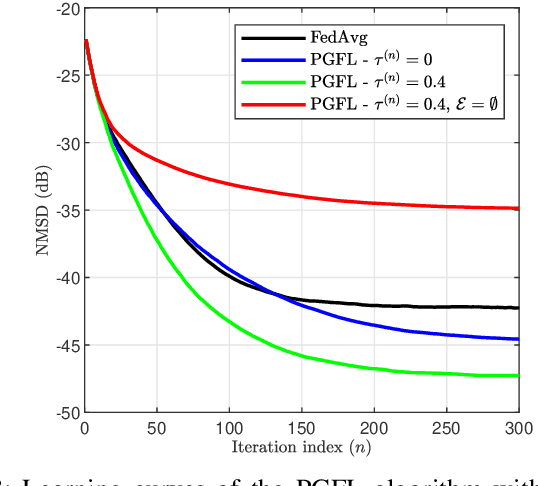
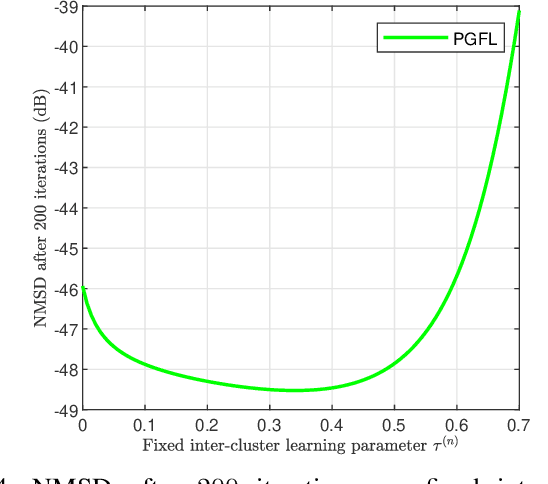
This paper presents a personalized graph federated learning (PGFL) framework in which distributedly connected servers and their respective edge devices collaboratively learn device or cluster-specific models while maintaining the privacy of every individual device. The proposed approach exploits similarities among different models to provide a more relevant experience for each device, even in situations with diverse data distributions and disproportionate datasets. Furthermore, to ensure a secure and efficient approach to collaborative personalized learning, we study a variant of the PGFL implementation that utilizes differential privacy, specifically zero-concentrated differential privacy, where a noise sequence perturbs model exchanges. Our mathematical analysis shows that the proposed privacy-preserving PGFL algorithm converges to the optimal cluster-specific solution for each cluster in linear time. It also shows that exploiting similarities among clusters leads to an alternative output whose distance to the original solution is bounded, and that this bound can be adjusted by modifying the algorithm's hyperparameters. Further, our analysis shows that the algorithm ensures local differential privacy for all clients in terms of zero-concentrated differential privacy. Finally, the performance of the proposed PGFL algorithm is examined by performing numerical experiments in the context of regression and classification using synthetic data and the MNIST dataset.
Asynchronous Online Federated Learning with Reduced Communication Requirements
Apr 11, 2023



Online federated learning (FL) enables geographically distributed devices to learn a global shared model from locally available streaming data. Most online FL literature considers a best-case scenario regarding the participating clients and the communication channels. However, these assumptions are often not met in real-world applications. Asynchronous settings can reflect a more realistic environment, such as heterogeneous client participation due to available computational power and battery constraints, as well as delays caused by communication channels or straggler devices. Further, in most applications, energy efficiency must be taken into consideration. Using the principles of partial-sharing-based communications, we propose a communication-efficient asynchronous online federated learning (PAO-Fed) strategy. By reducing the communication overhead of the participants, the proposed method renders participation in the learning task more accessible and efficient. In addition, the proposed aggregation mechanism accounts for random participation, handles delayed updates and mitigates their effect on accuracy. We prove the first and second-order convergence of the proposed PAO-Fed method and obtain an expression for its steady-state mean square deviation. Finally, we conduct comprehensive simulations to study the performance of the proposed method on both synthetic and real-life datasets. The simulations reveal that in asynchronous settings, the proposed PAO-Fed is able to achieve the same convergence properties as that of the online federated stochastic gradient while reducing the communication overhead by 98 percent.
Resource-Aware Asynchronous Online Federated Learning for Nonlinear Regression
Nov 27, 2021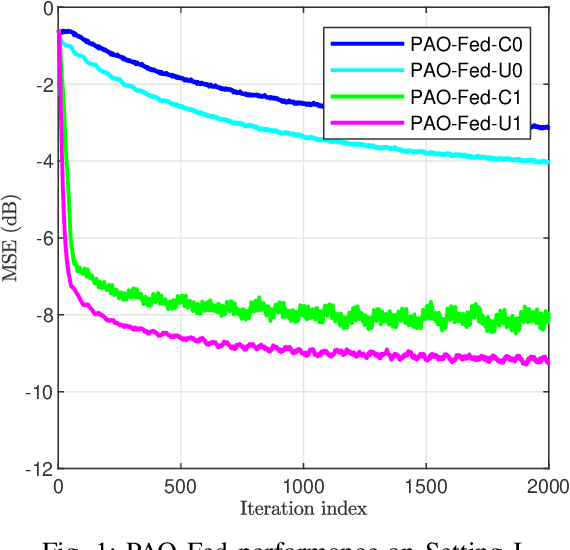

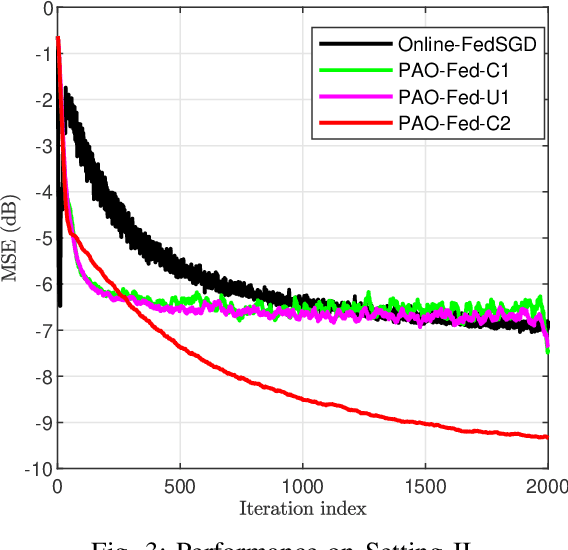
Many assumptions in the federated learning literature present a best-case scenario that can not be satisfied in most real-world applications. An asynchronous setting reflects the realistic environment in which federated learning methods must be able to operate reliably. Besides varying amounts of non-IID data at participants, the asynchronous setting models heterogeneous client participation due to available computational power and battery constraints and also accounts for delayed communications between clients and the server. To reduce the communication overhead associated with asynchronous online federated learning (ASO-Fed), we use the principles of partial-sharing-based communication. In this manner, we reduce the communication load of the participants and, therefore, render participation in the learning task more accessible. We prove the convergence of the proposed ASO-Fed and provide simulations to analyze its behavior further. The simulations reveal that, in the asynchronous setting, it is possible to achieve the same convergence as the federated stochastic gradient (Online-FedSGD) while reducing the communication tenfold.
Communication-Efficient Online Federated Learning Framework for Nonlinear Regression
Oct 13, 2021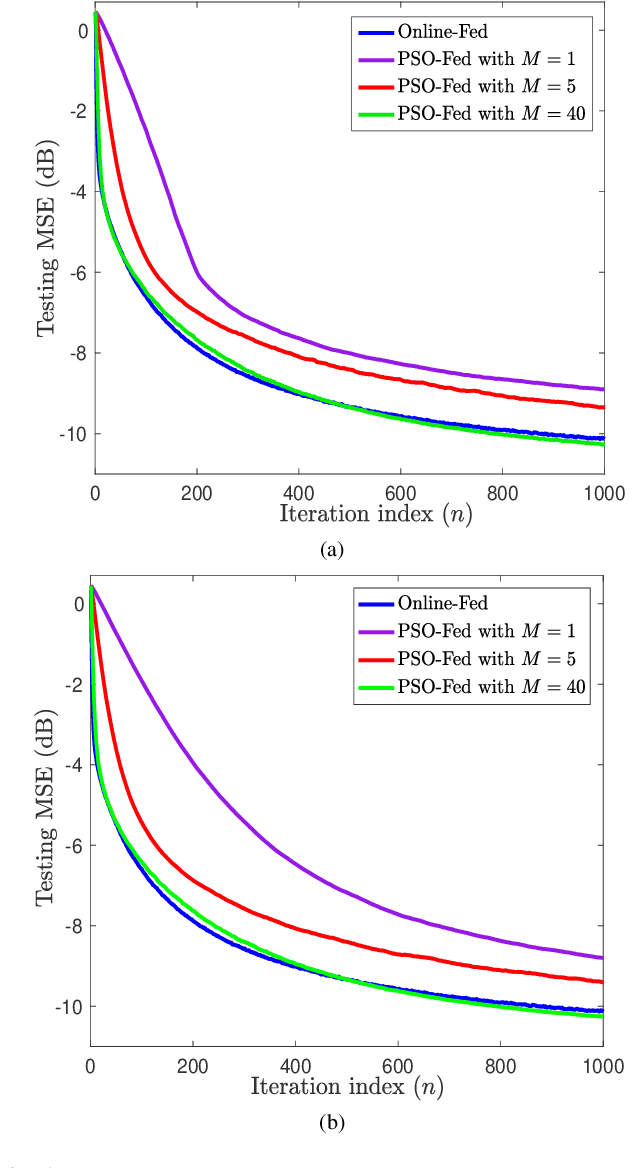
Federated learning (FL) literature typically assumes that each client has a fixed amount of data, which is unrealistic in many practical applications. Some recent works introduced a framework for online FL (Online-Fed) wherein clients perform model learning on streaming data and communicate the model to the server; however, they do not address the associated communication overhead. As a solution, this paper presents a partial-sharing-based online federated learning framework (PSO-Fed) that enables clients to update their local models using continuous streaming data and share only portions of those updated models with the server. During a global iteration of PSO-Fed, non-participant clients have the privilege to update their local models with new data. Here, we consider a global task of kernel regression, where clients use a random Fourier features-based kernel LMS on their data for local learning. We examine the mean convergence of the PSO-Fed for kernel regression. Experimental results show that PSO-Fed can achieve competitive performance with a significantly lower communication overhead than Online-Fed.
Model Approximation Using Cascade of Tree Decompositions
Aug 10, 2018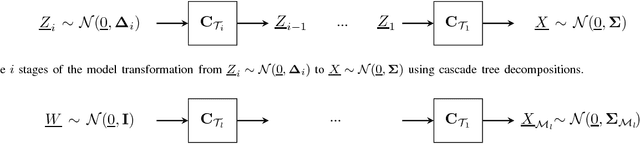
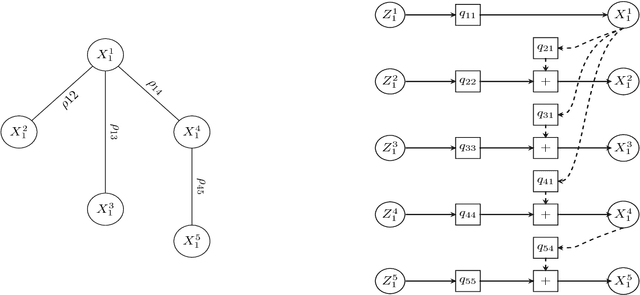
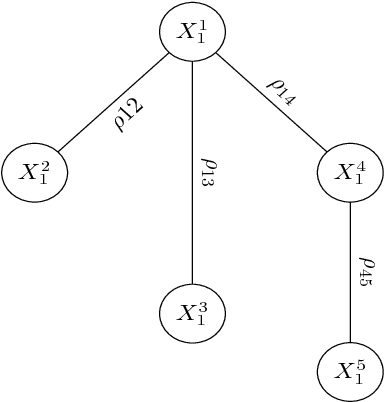
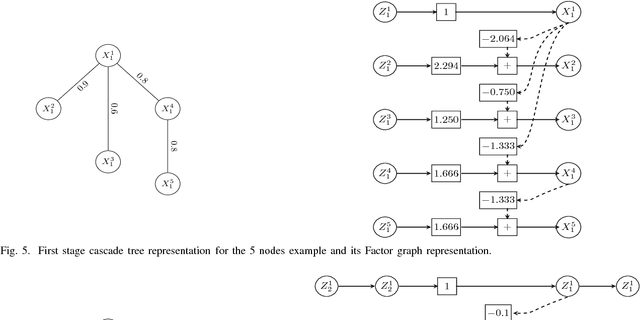
In this paper, we present a general, multistage framework for graphical model approximation using a cascade of models such as trees. In particular, we look at the problem of covariance matrix approximation for Gaussian distributions as linear transformations of tree models. This is a new way to decompose the covariance matrix. Here, we propose an algorithm which incorporates the Cholesky factorization method to compute the decomposition matrix and thus can approximate a simple graphical model using a cascade of the Cholesky factorization of the tree approximation transformations. The Cholesky decomposition enables us to achieve a tree structure factor graph at each cascade stage of the algorithm which facilitates the use of the message passing algorithm since the approximated graph has less loops compared to the original graph. The overall graph is a cascade of factor graphs with each factor graph being a tree. This is a different perspective on the approximation model, and algorithms such as Gaussian belief propagation can be used on this overall graph. Here, we present theoretical result that guarantees the convergence of the proposed model approximation using the cascade of tree decompositions. In the simulations, we look at synthetic and real data and measure the performance of the proposed framework by comparing the KL divergences.
The Quality of the Covariance Selection Through Detection Problem and AUC Bounds
Oct 18, 2017



We consider the problem of quantifying the quality of a model selection problem for a graphical model. We discuss this by formulating the problem as a detection problem. Model selection problems usually minimize a distance between the original distribution and the model distribution. For the special case of Gaussian distributions, the model selection problem simplifies to the covariance selection problem which is widely discussed in literature by Dempster [2] where the likelihood criterion is maximized or equivalently the Kullback-Leibler (KL) divergence is minimized to compute the model covariance matrix. While this solution is optimal for Gaussian distributions in the sense of the KL divergence, it is not optimal when compared with other information divergences and criteria such as Area Under the Curve (AUC). In this paper, we analytically compute upper and lower bounds for the AUC and discuss the quality of model selection problem using the AUC and its bounds as an accuracy measure in detection problem. We define the correlation approximation matrix (CAM) and show that analytical computation of the KL divergence, the AUC and its bounds only depend on the eigenvalues of CAM. We also show the relationship between the AUC, the KL divergence and the ROC curve by optimizing with respect to the ROC curve. In the examples provided, we pick tree structures as the simplest graphical models. We perform simulations on fully-connected graphs and compute the tree structured models by applying the widely used Chow-Liu algorithm [3]. Examples show that the quality of tree approximation models are not good in general based on information divergences, the AUC and its bounds when the number of nodes in the graphical model is large. We show both analytically and by simulations that the 1-AUC for the tree approximation model decays exponentially as the dimension of graphical model increases.