 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVB: A Video Dataset of Cattle Visual Behaviors
May 26, 2023

Existing image/video datasets for cattle behavior recognition are mostly small, lack well-defined labels, or are collected in unrealistic controlled environments. This limits the utility of machine learning (ML) models learned from them. Therefore, we introduce a new dataset, called Cattle Visual Behaviors (CVB), that consists of 502 video clips, each fifteen seconds long, captured in natural lighting conditions, and annotated with eleven visually perceptible behaviors of grazing cattle. We use the Computer Vision Annotation Tool (CVAT) to collect our annotations. To make the procedure more efficient, we perform an initial detection and tracking of cattle in the videos using appropriate pre-trained models. The results are corrected by domain experts along with cattle behavior labeling in CVAT. The pre-hoc detection and tracking step significantly reduces the manual annotation time and effort. Moreover, we convert CVB to the atomic visual action (AVA) format and train and evaluate the popular SlowFast action recognition model on it. The associated preliminary results confirm that we can localize the cattle and recognize their frequently occurring behaviors with confidence. By creating and sharing CVB, our aim is to develop improved models capable of recognizing all important behaviors accurately and to assist other researchers and practitioners in developing and evaluating new ML models for cattle behavior classification using video data.
Point-Syn2Real: Semi-Supervised Synthetic-to-Real Cross-Domain Learning for Object Classification in 3D Point Clouds
Oct 31, 2022

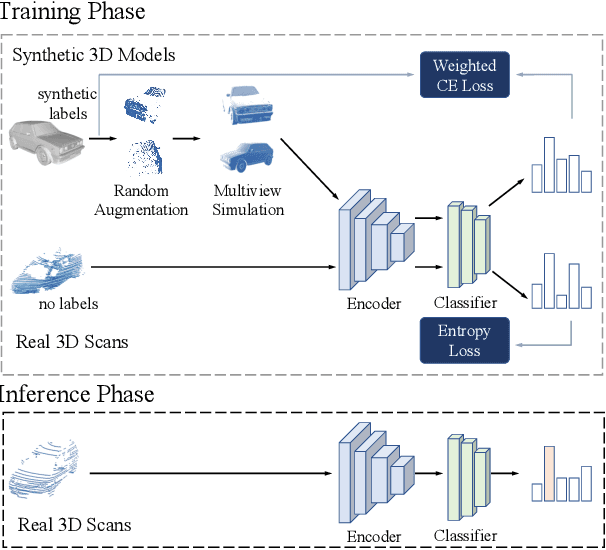
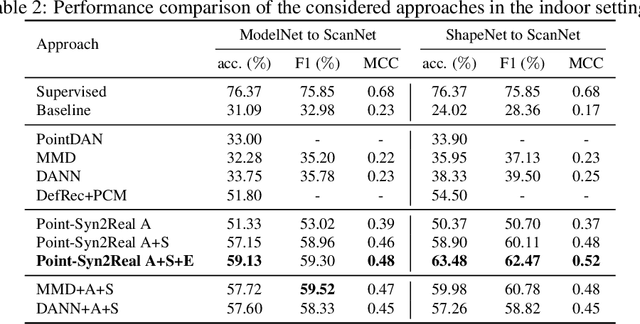
Object classification using LiDAR 3D point cloud data is critical for modern applications such as autonomous driving. However, labeling point cloud data is labor-intensive as it requires human annotators to visualize and inspect the 3D data from different perspectives. In this paper, we propose a semi-supervised cross-domain learning approach that does not rely on manual annotations of point clouds and performs similar to fully-supervised approaches. We utilize available 3D object models to train classifiers that can generalize to real-world point clouds. We simulate the acquisition of point clouds by sampling 3D object models from multiple viewpoints and with arbitrary partial occlusions. We then augment the resulting set of point clouds through random rotations and adding Gaussian noise to better emulate the real-world scenarios. We then train point cloud encoding models, e.g., DGCNN, PointNet++, on the synthesized and augmented datasets and evaluate their cross-domain classification performance on corresponding real-world datasets. We also introduce Point-Syn2Real, a new benchmark dataset for cross-domain learning on point clouds. The results of our extensive experiments with this dataset demonstrate that the proposed cross-domain learning approach for point clouds outperforms the related baseline and state-of-the-art approaches in both indoor and outdoor settings in terms of cross-domain generalizability. The code and data will be available upon publishing.
In-situ animal behavior classification using knowledge distillation and fixed-point quantization
Sep 09, 2022
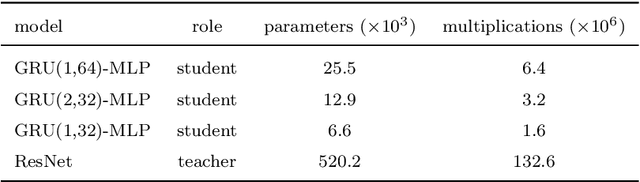
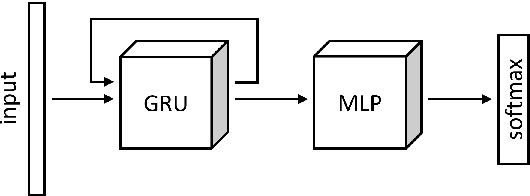
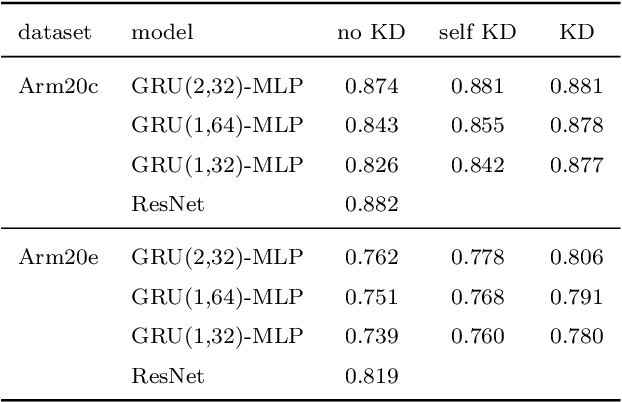
We explore the use of knowledge distillation (KD) for learning compact and accurate models that enable classification of animal behavior from accelerometry data on wearable devices. To this end, we take a deep and complex convolutional neural network, known as residual neural network (ResNet), as the teacher model. ResNet is specifically designed for multivariate time-series classification. We use ResNet to distil the knowledge of animal behavior classification datasets into soft labels, which consist of the predicted pseudo-probabilities of every class for each datapoint. We then use the soft labels to train our significantly less complex student models, which are based on the gated recurrent unit (GRU) and multilayer perceptron (MLP). The evaluation results using two real-world animal behavior classification datasets show that the classification accuracy of the student GRU-MLP models improves appreciably through KD, approaching that of the teacher ResNet model. To further reduce the computational and memory requirements of performing inference using the student models trained via KD, we utilize dynamic fixed-point quantization through an appropriate modification of the computational graphs of the models. We implement both unquantized and quantized versions of the developed KD-based models on the embedded systems of our purpose-built collar and ear tag devices to classify animal behavior in situ and in real time. The results corroborate the effectiveness of KD and quantization in improving the inference performance in terms of both classification accuracy and computational and memory efficiency.