 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Effects of Projectors in Knowledge Distillation
Oct 26, 2023



Conventionally, during the knowledge distillation process (e.g. feature distillation), an additional projector is often required to perform feature transformation due to the dimension mismatch between the teacher and the student networks. Interestingly, we discovered that even if the student and the teacher have the same feature dimensions, adding a projector still helps to improve the distillation performance. In addition, projectors even improve logit distillation if we add them to the architecture too. Inspired by these surprising findings and the general lack of understanding of the projectors in the knowledge distillation process from existing literature, this paper investigates the implicit role that projectors play but so far have been overlooked. Our empirical study shows that the student with a projector (1) obtains a better trade-off between the training accuracy and the testing accuracy compared to the student without a projector when it has the same feature dimensions as the teacher, (2) better preserves its similarity to the teacher beyond shallow and numeric resemblance, from the view of Centered Kernel Alignment (CKA), and (3) avoids being over-confident as the teacher does at the testing phase. Motivated by the positive effects of projectors, we propose a projector ensemble-based feature distillation method to further improve distillation performance. Despite the simplicity of the proposed strategy, empirical results from the evaluation of classification tasks on benchmark datasets demonstrate the superior classification performance of our method on a broad range of teacher-student pairs and verify from the aspects of CKA and model calibration that the student's features are of improved quality with the projector ensemble design.
Improved Feature Distillation via Projector Ensemble
Oct 27, 2022In knowledge distillation, previous feature distillation methods mainly focus on the design of loss functions and the selection of the distilled layers, while the effect of the feature projector between the student and the teacher remains under-explored. In this paper, we first discuss a plausible mechanism of the projector with empirical evidence and then propose a new feature distillation method based on a projector ensemble for further performance improvement. We observe that the student network benefits from a projector even if the feature dimensions of the student and the teacher are the same. Training a student backbone without a projector can be considered as a multi-task learning process, namely achieving discriminative feature extraction for classification and feature matching between the student and the teacher for distillation at the same time. We hypothesize and empirically verify that without a projector, the student network tends to overfit the teacher's feature distributions despite having different architecture and weights initialization. This leads to degradation on the quality of the student's deep features that are eventually used in classification. Adding a projector, on the other hand, disentangles the two learning tasks and helps the student network to focus better on the main feature extraction task while still being able to utilize teacher features as a guidance through the projector. Motivated by the positive effect of the projector in feature distillation, we propose an ensemble of projectors to further improve the quality of student features. Experimental results on different datasets with a series of teacher-student pairs illustrate the effectiveness of the proposed method.
Hyperspectral Image Recovery via Hybrid Regularization
Aug 26, 2016



Natural images tend to mostly consist of smooth regions with individual pixels having highly correlated spectra. This information can be exploited to recover hyperspectral images of natural scenes from their incomplete and noisy measurements. To perform the recovery while taking full advantage of the prior knowledge, we formulate a composite cost function containing a square-error data-fitting term and two distinct regularization terms pertaining to spatial and spectral domains. The regularization for the spatial domain is the sum of total-variation of the image frames corresponding to all spectral bands. The regularization for the spectral domain is the l1-norm of the coefficient matrix obtained by applying a suitable sparsifying transform to the spectra of the pixels. We use an accelerated proximal-subgradient method to minimize the formulated cost function. We analyze the performance of the proposed algorithm and prove its convergence. Numerical simulations using real hyperspectral images exhibit that the proposed algorithm offers an excellent recovery performance with a number of measurements that is only a small fraction of the hyperspectral image data size. Simulation results also show that the proposed algorithm significantly outperforms an accelerated proximal-gradient algorithm that solves the classical basis-pursuit denoising problem to recover the hyperspectral image.
Compressive hyperspectral imaging via adaptive sampling and dictionary learning
Dec 02, 2015
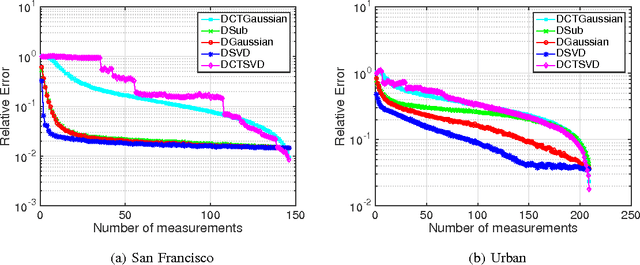
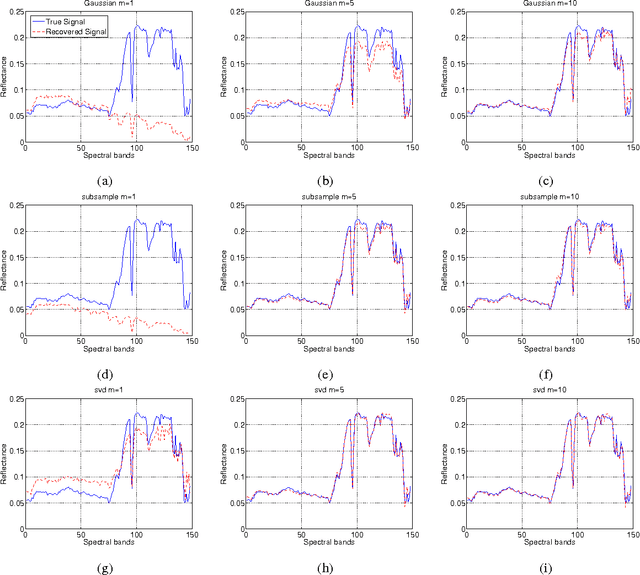
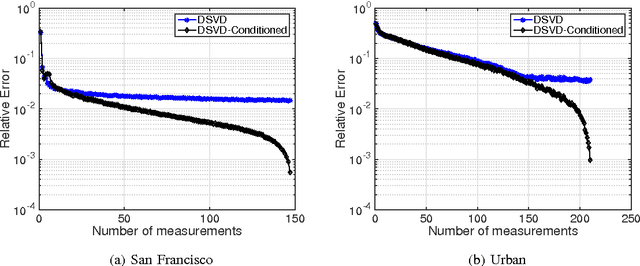
In this paper, we propose a new sampling strategy for hyperspectral signals that is based on dictionary learning and singular value decomposition (SVD). Specifically, we first learn a sparsifying dictionary from training spectral data using dictionary learning. We then perform an SVD on the dictionary and use the first few left singular vectors as the rows of the measurement matrix to obtain the compressive measurements for reconstruction. The proposed method provides significant improvement over the conventional compressive sensing approaches. The reconstruction performance is further improved by reconditioning the sensing matrix using matrix balancing. We also demonstrate that the combination of dictionary learning and SVD is robust by applying them to different datasets.
Sparse Bayesian Learning for EEG Source Localization
Jan 19, 2015



Purpose: Localizing the sources of electrical activity from electroencephalographic (EEG) data has gained considerable attention over the last few years. In this paper, we propose an innovative source localization method for EEG, based on Sparse Bayesian Learning (SBL). Methods: To better specify the sparsity profile and to ensure efficient source localization, the proposed approach considers grouping of the electrical current dipoles inside human brain. SBL is used to solve the localization problem in addition with imposed constraint that the electric current dipoles associated with the brain activity are isotropic. Results: Numerical experiments are conducted on a realistic head model that is obtained by segmentation of MRI images of the head and includes four major components, namely the scalp, the skull, the cerebrospinal fluid (CSF) and the brain, with appropriate relative conductivity values. The results demonstrate that the isotropy constraint significantly improves the performance of SBL. In a noiseless environment, the proposed method was 1 found to accurately (with accuracy of >75%) locate up to 6 simultaneously active sources, whereas for SBL without the isotropy constraint, the accuracy of finding just 3 simultaneously active sources was <75%. Conclusions: Compared to the state-of-the-art algorithms, the proposed method is potentially more consistent in specifying the sparsity profile of human brain activity and is able to produce better source localization for EEG.