 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAPFormer: Robust Arbitrary Point Tracking via Transient Asynchronous Fusion of Frames and Events
Mar 05, 2026Tracking any point (TAP) is a fundamental yet challenging task in computer vision, requiring high precision and long-term motion reasoning. Recent attempts to combine RGB frames and event streams have shown promise, yet they typically rely on synchronous or non-adaptive fusion, leading to temporal misalignment and severe degradation when one modality fails. We introduce TAPFormer, a transformer-based framework that performs asynchronous temporal-consistent fusion of frames and events for robust and high-frequency arbitrary point tracking. Our key innovation is a Transient Asynchronous Fusion (TAF) mechanism, which explicitly models the temporal evolution between discrete frames through continuous event updates, bridging the gap between low-rate frames and high-rate events. In addition, a Cross-modal Locally Weighted Fusion (CLWF) module adaptively adjusts spatial attention according to modality reliability, yielding stable and discriminative features even under blur or low light. To evaluate our approach under realistic conditions, we construct a novel real-world frame-event TAP dataset under diverse illumination and motion conditions. Our method outperforms existing point trackers, achieving a 28.2% improvement in average pixel error within threshold. Moreover, on standard point tracking benchmarks, our tracker consistently achieves the best performance. Project website: tapformer.github.io
Fully Spiking Neural Networks for Unified Frame-Event Object Tracking
May 27, 2025The integration of image and event streams offers a promising approach for achieving robust visual object tracking in complex environments. However, current fusion methods achieve high performance at the cost of significant computational overhead and struggle to efficiently extract the sparse, asynchronous information from event streams, failing to leverage the energy-efficient advantages of event-driven spiking paradigms. To address this challenge, we propose the first fully Spiking Frame-Event Tracking framework called SpikeFET. This network achieves synergistic integration of convolutional local feature extraction and Transformer-based global modeling within the spiking paradigm, effectively fusing frame and event data. To overcome the degradation of translation invariance caused by convolutional padding, we introduce a Random Patchwork Module (RPM) that eliminates positional bias through randomized spatial reorganization and learnable type encoding while preserving residual structures. Furthermore, we propose a Spatial-Temporal Regularization (STR) strategy that overcomes similarity metric degradation from asymmetric features by enforcing spatio-temporal consistency among temporal template features in latent space. Extensive experiments across multiple benchmarks demonstrate that the proposed framework achieves superior tracking accuracy over existing methods while significantly reducing power consumption, attaining an optimal balance between performance and efficiency. The code will be released.
A Plug-and-Play Learning-based IMU Bias Factor for Robust Visual-Inertial Odometry
Mar 16, 2025



The bias of low-cost Inertial Measurement Units (IMU) is a critical factor affecting the performance of Visual-Inertial Odometry (VIO). In particular, when visual tracking encounters errors, the optimized bias results may deviate significantly from the true values, adversely impacting the system's stability and localization precision. In this paper, we propose a novel plug-and-play framework featuring the Inertial Prior Network (IPNet), which is designed to accurately estimate IMU bias. Recognizing the substantial impact of initial bias errors in low-cost inertial devices on system performance, our network directly leverages raw IMU data to estimate the mean bias, eliminating the dependency on historical estimates in traditional recursive predictions and effectively preventing error propagation. Furthermore, we introduce an iterative approach to calculate the mean value of the bias for network training, addressing the lack of bias labels in many visual-inertial datasets. The framework is evaluated on two public datasets and one self-collected dataset. Extensive experiments demonstrate that our method significantly enhances both localization precision and robustness, with the ATE-RMSE metric improving on average by 46\%. The source code and video will be available at \textcolor{red}{https://github.com/yiyscut/VIO-IPNet.git}.
Uncertainty-Aware Normal-Guided Gaussian Splatting for Surface Reconstruction from Sparse Image Sequences
Mar 14, 20253D Gaussian Splatting (3DGS) has achieved impressive rendering performance in novel view synthesis. However, its efficacy diminishes considerably in sparse image sequences, where inherent data sparsity amplifies geometric uncertainty during optimization. This often leads to convergence at suboptimal local minima, resulting in noticeable structural artifacts in the reconstructed scenes.To mitigate these issues, we propose Uncertainty-aware Normal-Guided Gaussian Splatting (UNG-GS), a novel framework featuring an explicit Spatial Uncertainty Field (SUF) to quantify geometric uncertainty within the 3DGS pipeline. UNG-GS enables high-fidelity rendering and achieves high-precision reconstruction without relying on priors. Specifically, we first integrate Gaussian-based probabilistic modeling into the training of 3DGS to optimize the SUF, providing the model with adaptive error tolerance. An uncertainty-aware depth rendering strategy is then employed to weight depth contributions based on the SUF, effectively reducing noise while preserving fine details. Furthermore, an uncertainty-guided normal refinement method adjusts the influence of neighboring depth values in normal estimation, promoting robust results. Extensive experiments demonstrate that UNG-GS significantly outperforms state-of-the-art methods in both sparse and dense sequences. The code will be open-source.
Tracking Any Point with Frame-Event Fusion Network at High Frame Rate
Sep 18, 2024



Tracking any point based on image frames is constrained by frame rates, leading to instability in high-speed scenarios and limited generalization in real-world applications. To overcome these limitations, we propose an image-event fusion point tracker, FE-TAP, which combines the contextual information from image frames with the high temporal resolution of events, achieving high frame rate and robust point tracking under various challenging conditions. Specifically, we designed an Evolution Fusion module (EvoFusion) to model the image generation process guided by events. This module can effectively integrate valuable information from both modalities operating at different frequencies. To achieve smoother point trajectories, we employed a transformer-based refinement strategy that updates the point's trajectories and features iteratively. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches, particularly improving expected feature age by 24$\%$ on EDS datasets. Finally, we qualitatively validated the robustness of our algorithm in real driving scenarios using our custom-designed high-resolution image-event synchronization device. Our source code will be released at https://github.com/ljx1002/FE-TAP.
Spatio-Temporal Matching for Siamese Visual Tracking
May 06, 2021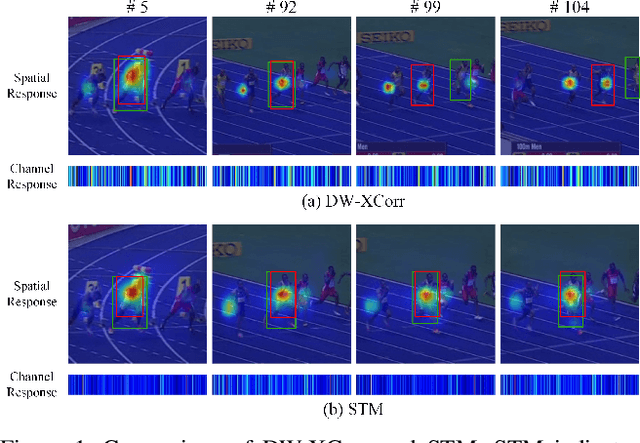
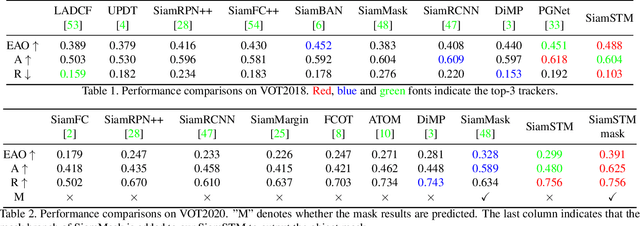
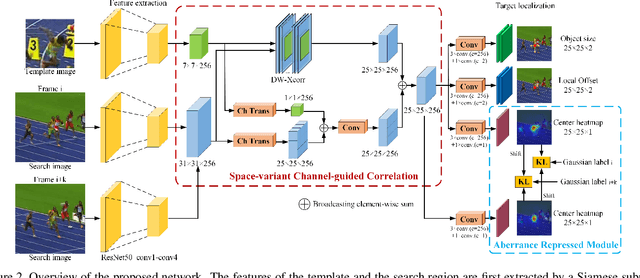
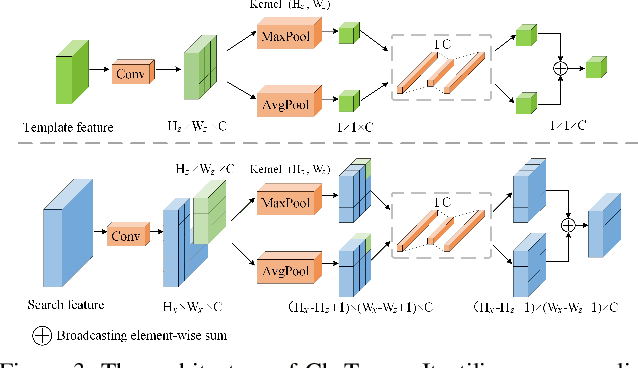
Similarity matching is a core operation in Siamese trackers. Most Siamese trackers carry out similarity learning via cross correlation that originates from the image matching field. However, unlike 2-D image matching, the matching network in object tracking requires 4-D information (height, width, channel and time). Cross correlation neglects the information from channel and time dimensions, and thus produces ambiguous matching. This paper proposes a spatio-temporal matching process to thoroughly explore the capability of 4-D matching in space (height, width and channel) and time. In spatial matching, we introduce a space-variant channel-guided correlation (SVC-Corr) to recalibrate channel-wise feature responses for each spatial location, which can guide the generation of the target-aware matching features. In temporal matching, we investigate the time-domain context relations of the target and the background and develop an aberrance repressed module (ARM). By restricting the abrupt alteration in the interframe response maps, our ARM can clearly suppress aberrances and thus enables more robust and accurate object tracking. Furthermore, a novel anchor-free tracking framework is presented to accommodate these innovations. Experiments on challenging benchmarks including OTB100, VOT2018, VOT2020, GOT-10k, and LaSOT demonstrate the state-of-the-art performance of the proposed method.